使用trie树统计单词出现的频数
首先给出trie树的原理:trie树是以空间换取时间,利用字符串的公共前缀来降低查询开销。举个例子:add,addition,这两个单词,他们的公共前缀是add,应用trie数进行存储的时候,add只会被存储一次,如果以add为前缀的单词很多,这样就节省了很多的存储空间。
trie树的性质:
1,字符种数决定trie中branch的个数,以单词为例,共有26个英文单词,那么每个节点中会有26个指针域。
2,branch数组的下标代表字符相对于a的相对位置。
3,插入和查询的时间复杂度均与给定单词的长度len成正比,即为:o(len)。
4,每个节点附设一个count域,若count域被初始化为0,如果在插入所有单词之后,遍历trie树的时候,count不等于0,则表示从根节点到此节点的
每个字母连接成的单词出现的次数。
如图所示,该trie树存有abc、d、da、dda四个字符串,如果是字符串会在节点的尾部进行标记(count!=0)。没有后续字符的branch分支指向NULL: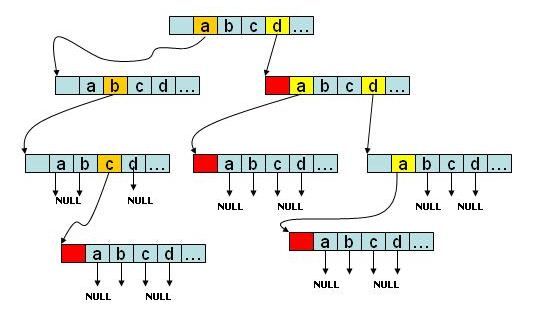
此图为挪用他人的,自己画不这么好,可以把第一个域当做count域。
先给出程序:
#include<stdio.h>
#include<stdlib.h>
#include<memory.h>
const int branchNum=26;
typedef struct TrieNode
{
int count; //单词出现的频数
struct TrieNode *child[branchNum];
}TrieNode,*TrieTree;
TrieNode *trie_create_node()//创建一个tTrieNode节点
{
TrieNode *temp=(TrieNode*)malloc(sizeof(TrieNode));
temp->count=0;
memset(temp->child,NULL,sizeof(temp->child));
return temp;
}
void trie_insert_word(TrieTree t,const char *word)//插入单词
{
TrieNode *node;
node=t;
int index;
while(*word)
{
index=*word-'a';
if(node->child[index]==NULL)
node->child[index]=trie_create_node();
node=node->child[index];
word++;
}
node->count++;
}
int trie_search_word(TrieTree t,const char *word)//查找单词
{
TrieNode *node=t;
while(*word&&node!=NULL)
{
node=node->child[*word-'a'];
word++;
}
if(node!=NULL&&node->count>0)
return 1;
else
return 0;
}
int trie_word_count(TrieTree t,const char *word)//统计单词出现的频数
{
TrieNode *node=t;
while(*word&&node!=NULL)
{
node=node->child[*word-'a'];
word++;
}
return node->count;
}
void trie_destroy_tree(TrieTree t)
{
int i;
for(i=0;i<branchNum;i++)
if(t->child[i]!=NULL)
trie_destroy_tree(t->child[i]);
free(t);
}
void main()
{
TrieTree t=trie_create_node();
char word[][10] = {"test","study","open","show","tee","work","work","test","tea","word",
"tea","word","test","test","test","show","study","open","word","test"};
for(int i = 0;i < 20;i++ )
{
trie_insert_word(t,word[i]);
}
for(i = 0;i < 20;i++ )
{
printf("%s:%d\n",word[i],trie_word_count(t,word[i]));
}
char s[10] = "testit";
printf("the word %s exist? %s \n",s,trie_search_word(t,s)?"yes":"no");
}
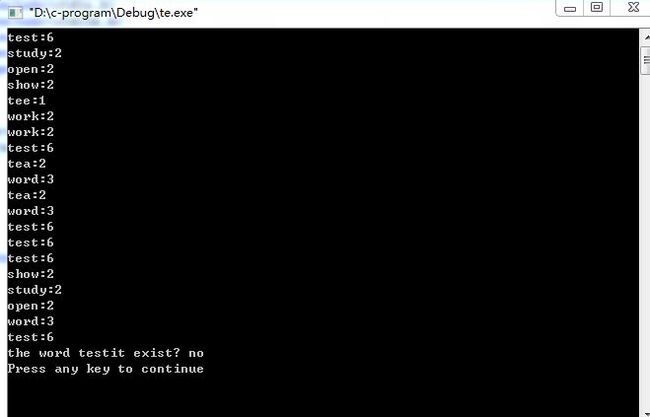
从给出的运行结果图,可以清晰的看到每个单词出现的频数,单问题也随之而来了:很容易发现,每个单词及每个<单词,频数>对输出的次数和每个单词出现的频数相同,众而周知,trie树被用来设计处理海量数据,如果说一个含有100万的单词的文本文件中,最终统计出来的不重复单词只有几万个,那么依照上面程序中的遍历方法,是想相当浪费时间的,从而说明,开始设计的那个struct TrieNode不是一个好的数据结构.......
最近在思索,寻找好的方法,设计一个好的数据结构,还没有思路,希望路过的大侠给个思路。