Greenplum基础
Greenplum基础
- MPP架构
- 一、Greenplum架构
-
- 1.1 Master/Coordinator节点
- 1.2 Segment节点
- 1.3 Interconnect
- 二、Greenplum基本使用
-
- 2.1 登录
- 2.2 数据类型
-
- 2.2.1 枚举类型
- 2.2.2 几何类型
- 2.2.3 网络地址类型
- 2.2.4 JSON类型
- 2.2.5 数组类型
- 2.2.6 复合类型
- 三、DDL(Data Definition Language)数据定义语言
-
- 3.1 创建数据库
- 3.2 创建schema
- 3.3 数据库操作
- 3.4 创建表
-
- 3.4.1 内部表
- 3.4.2 外部表
- 3.4.3 外部表和内部表的区别
- 3.5 修改表
-
- 3.5.1 重命名表
- 3.5.2 增加/修改/替换列信息
- 3.5.3 删除表
- 3.5.4 清空表
- 四、DML(Data Manipulation Language)数据操作语言
-
- 4.1 数据导入
-
- 4.1.1 copy装载数据
- 4.1.2 insert插入数据
- 4.1.3 查询结果建表加载数据
- 4.2 数据更新和删除
-
- 4.2.1 数据更新
- 4.2.2 数据删除
- 4.3 数据导出
MPP架构
MPP(Massively Parallel Processing)架构是一种用于处理大规模数据的计算架构,它通过将任务分配给多个处理单元并行执行,以提高处理速度和性能。MPP 架构的由来可以追溯到对大规模数据处理需求的不断增长,传统的单一处理器或对称多处理器(SMP)架构无法满足这些需求。MPP 架构允许在大规模数据集上实现水平扩展,通过添加更多的处理单元来增加计算和存储能力。
- 分布式存储: MPP 数据库系统通常使用分布式存储架构,将数据分散存储在多个节点上。每个节点都有自己的存储单元,这样可以提高数据的读取和写入速度。
- 并行处理: MPP 架构通过将任务分解成小块,并同时在多个处理单元上执行这些任务来实现并行处理。每个处理单元负责处理数据的一个子集,然后将结果合并以生成最终的输出。
- 共享无状态架构: MPP 系统通常采用共享无状态的架构,即每个节点之间没有共享的状态。这使得系统更容易水平扩展,因为可以简单地添加更多的节点,而不需要共享状态的复杂管理。
- 负载平衡: MPP 数据库通常具有负载平衡机制,确保任务在各个节点上均匀分布,避免某些节点成为性能瓶颈。
- 高可用性: 为了提高系统的可用性,MPP 架构通常设计成具有容错和故障恢复机制。如果一个节点出现故障,系统可以继续运行,而不会丢失数据或中断服务。
一些知名的 MPP 数据库系统包括 Teradata、Greenplum、Amazon Redshift 等。这些系统广泛应用于企业数据仓库、商业智能和大数据分析等领域。总体而言,MPP 架构通过将任务分布到多个节点并行执行,以及有效地利用分布式存储和处理的方式,提供了一种高性能、可伸缩的数据处理解决方案,适用于处理大规模数据的场景。
一、Greenplum架构
Greenplum是基于开源PostgreSQL的分布式数据库,采用shared-nothing(共享无状态)架构,即主机、操作系统、内存、存储都是每台服务器独立自我控制,不存在共享。
Greenplum本质上是一个关系型数据库集群,实际上是由多个独立的数据库服务组合而成的一个逻辑数据库。这种数据库集群采取的是MPP(Massively Parallel Processing)架构,大规模并行处理。
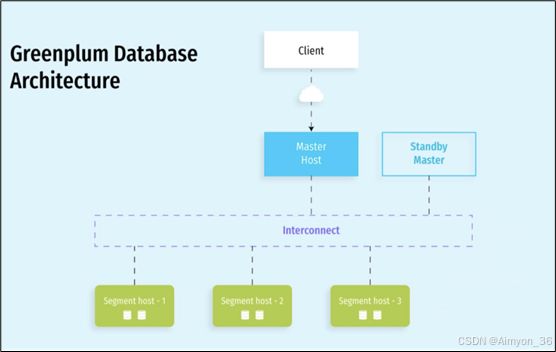
GreenPlum数据库是由Master Server、Segment Server和Interconnect三部分组成,Master Server和Segment Server的互联使用Interconnect。
协调者(Coordinator) 和 Master 节点 是同一个概念,只是不同版本或文档中使用的术语不同。它们都指的是 Greenplum 集群中负责查询解析、任务分发和结果汇总的核心节点。
在较新版本的 Greenplum(特别是 Greenplum 6 及以后),官方文档逐渐采用 Coordinator(协调者) 这一术语取代Master,以更清晰地描述其功能。
在技术领域,“Master” 这一术语逐渐被认为不够中立或可能引发歧义,因此许多开源项目(如 Greenplum、PostgreSQL 等)开始采用更中立的术语,如 “Coordinator” 或 “Primary”。
“Coordinator” 更准确地描述了该节点的核心功能,即协调整个集群的工作,而不是“主从”关系中的“主”。
Greenplum是一个关系型数据库,是由数个独立的数据服务组合成的逻辑数据库,整个集群由多个数据节点(Segment Host)和控制节点(Master Host)组成。在典型的Shared-Nothing中,每个节点上所有的资源的CPU、内存、磁盘都是独立的,每个节点都只有全部数据的一部分,也只能使用本节点的数据资源。
在Greenplum中,需要存储的数据在进入到表时,将先进行数据分布的处理工作,将一个表中的数据平均分布到每个节点上,并为每个表指定一个分布列(Distribute Column),之后便根据Hash来分布数据,基于Shared-Nothing的原则,Greenplum这样处理可以充分发挥每个节点处IO的处理能力。
1.1 Master/Coordinator节点
Master/Coordinator节点是整个系统的控制中心和对外的服务接入点,它负责接收用户SQL请求,将SQL生成查询计划进行并行处理优化,然后将查询计划分配到所有的Segment节点并进行处理,协调组织各个Segment节点按照查询计划一步一步地进行并行处理,最后获取到Segment的计算结果,再返回给客户端。
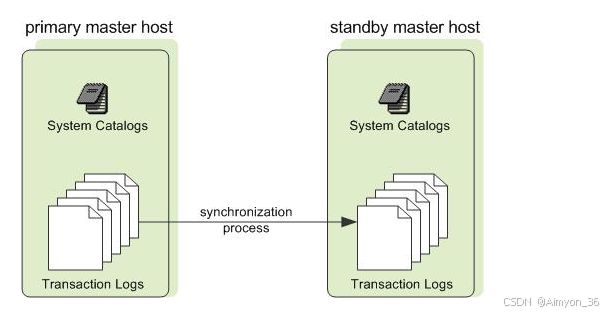
从用户的角度看Greenplum集群,看到的只是Master节点,无需关心集群内部的机制,所有的并行处理都是在Master控制下自动完成的。Master节点一般只有一个或二个。
1.2 Segment节点
Segment节点是Greenplum执行并行任务的并行计算节点,它接收Master的指令进行MPP并行计算,因此所有Segment节点的计算性总和就是整个集群的性能,通过增加Segment节点,可以线性化得增加集群的处理性能和存储容量,Segment节点可以是1~10000个节点。
1.3 Interconnect
Interconnect是Master节点与Segment节点、Segment节点与Segment节点之间进行数据传输的组件,它基于千兆交换机或者万兆交换机实现数据再节点之间的高速传输。
外部数据在加载到Segment时,采用并行数据流进行加载,直接加载到Segment节点,这项独特的技术是Greenplum的专有技术,保证数据在最短时间内加载到数据库中。
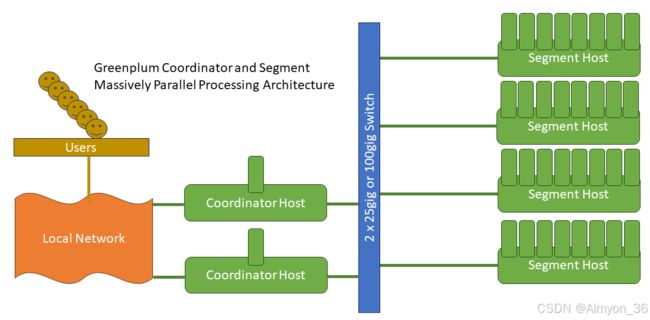
官方介绍的Greenplum架构:
二、Greenplum基本使用
2.1 登录
psql 命令登录gp,psql/命令用法可以通过 psql --help 查看帮助信息。
psql 命令格式为:psql -h hostname -p port -d database -U user -W password
- -h后面接对应的master或者segment主机名,默认是本机。
- -p后面接master或者segment的端口号,默认5432(master节点),如果登陆segment节点,则需要指定segment端口6000。
- -d后面接数据库名,默认gpdw,可将上述参数配置到用户环境变量中。
- -U登陆用户名,默认gpadmin。
一般直接psql默认登录就可以:
[aimyon@hadoop102 ~]$ psql
psql (9.4.26)
Type "help" for help.
gpdw=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+---------+----------+------------+------------+---------------------
gp_sydb | gpadmin | UTF8 | en_US.utf8 | en_US.utf8 |
postgres | gpadmin | UTF8 | en_US.utf8 | en_US.utf8 |
template0 | gpadmin | UTF8 | en_US.utf8 | en_US.utf8 | =c/gpadmin +
| | | | | gpadmin=CTc/gpadmin
template1 | gpadmin | UTF8 | en_US.utf8 | en_US.utf8 | =c/gpadmin +
| | | | | gpadmin=CTc/gpadmin
远程客户端登录gp
配置其他用户或者客户端远程登陆gp,需要配置以下2个文件:
- 配置 /opt/greenplum/data/master/gpseg-1/pg_hba.conf,新增一条规则,则允许任意ip及密码登陆pg。
- echo “host all gpadmin 0.0.0.0/0 trust” >> /home/gpadmin/data/master/gpseg-1/pg_hba.conf
- 配置修改完成后,重新加载配置文件:gpstop -u
2.2 数据类型
| 类型 | 长度 | 描述 | 范围 |
|---|---|---|---|
| bigint | 8字节 | 大范围整数 | -9223372036854775808 到 +9223372036854775807 |
| smallint | 2字节 | 小范围整数 | -32768到+32767 |
| integer(int) | 4字节 | 常用整数 | -2147483648 到 +2147483647 |
| decimal | 可变长 | 用户指定的精度,精确 | 小数点前 131072 位;小数点后 16383 位 |
| real | 4字节 | 可变精度,不准确 | 6位十进制数字精度 |
| double precision | 8字节 | 可变精度,不准确 | 15位十进制数字精度 |
| smallserial | 2字节 | 自增的小范围整数 | 1到32767 |
| serial | 4字节 | 自增整数 | 1到2147483647 |
| bigserial | 8字节 | 自增的大范围整数 | 1到9223372036854775807 |
| character | 别名char | 定长,不足补空白 | |
| character | varying | 别名varchar | 可变长,有长度限制 |
| text | 可变长 | 无长度限制 | |
| timestamp | 8字节 | 日期和时间,无时区 | 4713 BC到294276 AD |
| timestamp with time zone | 8字节 | 日期和时间,有时区 | 4713 BC到294276 AD |
| date | 4字节 | 只用于日期 | 4713 BC到5874897 AD |
| boolean | 1字节 | true/false | |
| money | 8字节 | 货币金额 | -92233720368547758.08 到 +92233720368547758.07 |
example:
--建表语句
create table student(
id int,
name text,
age int,
eight double precision);
#建表时会提示
Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'id' as the Greenplum Database data distribution key for this table.
这是提醒建表时指定分布键和分布策略,默认第一个字段(或逐渐)和hash策略。
--插入数据
insert into test values
(1,'xiaohaihai',18,75.2),
(2,'xiaosongsong',16,80.6),
(3,'xiaohuihui',17,60.3),
(4,'xiaoyangyang',16,65.8);
2.2.1 枚举类型
枚举类型是一个包含静态和值的有序集合的数据类型,类似于Java中的enum类型,需要使用create type命令创建。
-- 创建枚举类型
create type weeks as enum('Mon','Tue','Wed','Thu','Fri','Sat','Sun');
-- 建表字段使用枚举类型
create table user_schedule (
user_name varchar(100),
available_day weeks
// available_dat weeks DEFAULT 'Mon' 为枚举列设置默认值,防止无效列
);
-- 插入数据
insert into user_schedule (user_name, available_day) values ('Alice', 'Mon');
insert into user_schedule (user_name, available_day) values ('Bob', 'Fri');
insert into user_schedule (user_name, available_day) values ('Charlie', 'Sun');
-- 查询结果
select * from user_schedule;
在 Greenplum 中,枚举类型一旦创建,就会永久存储在数据库中,可以在后续的表定义和查询中重复使用。如果需要修改枚举类型的值列表,必须先删除并重新创建。枚举类型的持久性使其非常适合用于需要固定取值范围的场景。
枚举类型如果没有显式删除就会一直存在,或枚举类型被依赖的对象(如表)删除,且没有其他对象依赖它。
2.2.2 几何类型
几何数据类型表示二维的平面物体。下表列出了GreenPlum支持的几何类型。
| 类型 | 大小 | 描述 | 表现形式 |
|---|---|---|---|
| point | 16字节 | 平面中的点 | (x,y) |
| line | 32字节 | 直线 | ((x1,y1),(x2,y2)) |
| lseg | 32字节 | 线段 | ((x1,y1),(x2,y2)) |
| box | 32字节 | 矩形 | ((x1,y1),(x2,y2)) |
| path | 16+16n字节 | 路径(与多边形相似) | ((x1,y1),…) |
| polygon | 40+16n字节 | 多边形 | ((x1,y1),…) |
| circle | 24字节 | 圆 | <(x,y),r> (圆心和半径) |
-- 建表 创建一个表 geometric_shapes,它包含点、线和多边形类型的列。
create table geometric_shapes (
id serial primary key,
point_col point,
lseg_col lseg,
polygon_col polygon
);
-- 插入数据
insert into geometric_shapes (point_col, lseg_col, polygon_col)
values(point(1, 2), lseg '[(0,0),(1,1)]', polygon '((0,0),(1,0),(1,1),(0,1))');
--- 查询所有
select * from geometric_shapes;
--- 根据点查询
select * from geometric_shapes where point_col <-> point(1, 2) < 0.0001;
--- 根据线段查询
select * from geometric_shapes where lseg_col = lseg '[(0,0),(1,1)]';
--- 根据多边形查询
select * from geometric_shapes where polygon_col ~= polygon '((0,0),(1,0),(1,1),(0,1))';
2.2.3 网络地址类型
GreenPlum提供用于存储IPv4、IPv6、MAC地址的数据类型。用这些数据类型存储网络地址比用纯文本好,因为提供输入错误检查和特殊的操作和功能。
| 类型 | 描述 | 说明 |
|---|---|---|
| cidr | 7或19字节 | IPv4 或 IPv6 网络 |
| inet | 7或19字节 | IPv4 或 IPv6 主机和网络 |
| macaddr | 6字节 | MAC 地址 |
-- 创建包含网络地址数据类型的表
create table network_addresses (
id serial primary key,
ip_address inet,
network cidr,
mac_address macaddr
);
-- 插入数据
insert into network_addresses (ip_address, network, mac_address)
values('192.168.1.1/24', '192.168.1.0/24', '08:00:2b:01:02:03');
-- 查询数据
select * from network_addresses;
-- 查询特定的 IP 地址
select * from network_addresses where ip_address = inet '192.168.1.1';
select * from network_addresses where host(ip_address) = '192.168.1.1';
-- 查询特定的网络
select * from network_addresses where network = cidr '192.168.1.0/24';
-- 查询特定的 MAC 地址
select * from network_addresses where mac_address = macaddr '08:00:2b:01:02:03';
-- 更新数据
update network_addresses set ip_address = inet '192.168.1.2' where id = 1;
-- 删除数据
delete from network_addresses where id = 1;
在对 inet 或 cidr 数据类型进行排序的时候, IPv4 地址总是排在 IPv6 地址前面。
2.2.4 JSON类型
json 数据类型可以用来存储 JSON(JavaScript Object Notation)数据, 这样的数据也可以存储为 text,但是 json 数据类型更有利于检查每个存储的数值是可用的 JSON 值。
-- 创建一个新表,名为 json_demo,包含一个 json 类型的列
create table json_demo (
id serial primary key,
data json
);
-- 向 json_demo 表插入 json 数据,注意 json 数据必须是单引号的字符串
-- 并且遵循 json 格式
insert into json_demo (data) values ('{"name": "张三", "age": 28, "city": "北京"}');
-- 查询 json_demo 表中的 json 数据
select * from json_demo;
-- 使用 ->> 运算符来提取 json 对象中的 name 字段
select data->>'name' as name from json_demo;
2.2.5 数组类型
GreenPlum允许将字段定义成变长的多维数组。数组可以是任何基本类型或用户定义类型,枚举类型或复合类型。
-- 创建一个新表,名为 array_demo,包含一个 int 类型的数组列
create table array_demo (
id serial primary key,
numbers int[] -- int 数组类型列
);
-- 向 array_demo 表插入数组数据
-- 数组使用花括号{}并且元素由逗号分隔
insert into array_demo (numbers) values ('{1,2,3,4,5}');
-- 查询 array_demo 表中的数组数据
select * from array_demo;
-- 使用数组下标来获取数组中的特定元素
-- 注意:Greenplum数组下标从1开始
select numbers[1] as first_element from array_demo;
-- 使用 unnest 函数来展开数组为一系列行
select unnest(numbers) as expanded_numbers from array_demo;
2.2.6 复合类型
复合类型表示一行或者一条记录的结构; 它实际上只是一个字段名和它们的数据类型的列表。GreenPlum允许像简单数据类型那样使用复合类型。比如,一个表的某个字段可以声明为一个复合类型。
-- 定义一个复合类型,名为 person_type,包含姓名、年龄和城市
create type person_type as (
name text,
age int,
city text
);
-- 创建一个新表,名为 composite_demo,包含一个复合类型的列
create table composite_demo (
id serial primary key,
person_info person_type -- 使用之前定义的复合类型作为列类型
);
-- 向 composite_demo 表插入复合类型数据
-- 复合类型数据使用括号,并且属性值由逗号分隔
insert into composite_demo (person_info) values (ROW('张三', 28, '北京'));
三、DDL(Data Definition Language)数据定义语言
3.1 创建数据库
CREATE DATABASE 是 SQL 命令,用于创建一个新的数据库。
CREATE DATABASE name [ [WITH] [OWNER [=] dbowner]
[TEMPLATE [=] template]
[ENCODING [=] encoding]
[TABLESPAC [=] tablespace]
[CONNECTIONE LIMIT [=] connlimit ] ]
-
name 是你要创建的数据库的名称。这个名称是必须的,并且在同一个数据库服务器上必须是唯一的。
-
[ [WITH] [OWNER [=] dbowner]:
- 可选项,OWNER 指定了新数据库的所有者,如果未指定,新数据库的所有者默认是执行该命令的用户。
- dbowner 是数据库所有者的用户名。
-
[TEMPLATE [=] template]:
- 可选项,TEMPLATE 指定了用于创建新数据库的模板。
- 在 PostgreSQL 和 GreenPlum 中,通常有一个名为 template1 的默认模板。如果不指定,就会使用这个默认模板。
- template 是模板数据库的名称。
-
[ENCODING [=] encoding]:
- 可选项,ENCODING 指定了新数据库的字符编码。这个设置决定了数据库可以存储哪些字符。
- encoding 是字符编码的名称,例如 UTF8。
-
[TABLESPACE [=] tablespace]:
- 可选项,TABLESPACE 指定了新数据库的存储位置。表空间是数据库中存储文件的物理位置。
- tablespace 是表空间的名称。
-
[CONNECTION LIMIT [=] connlimit ]:
- 可选项,CONNECTION LIMIT 限制了可以同时连接到数据库的最大客户端数量。
- connlimit 是允许的最大连接数。如果设置为 -1,则表示没有限制。
创建一个name为my_db1的数据库,所属为gpadmin用户,字符集编码使用utf-8,表空间为pg_default,限制最大客户端连接数量。
create database my_db1 with owner gpadmin
encoding 'utf-8'
tablespace pg_default
connection limit 10;
3.2 创建schema
schema 本质上就是一种分组管理工具,它允许将相关性质或类型的多个表和其他数据库对象(如视图、索引、存储过程等)组织在一起。可以把 schema 看作是数据库内部的一个“文件夹”或“命名空间”,用于逻辑上组织和隔离数据,以实现更好的数据管理和安全控制。
一个 database 下可以有多个 schema,schema在 gp 中也叫做 namespace。
# 切换到EmployeeDB数据库
\c EmployeeDB
# 创建schema
create schema sc_test;
postgresql也有schema这个概念,和greenplum的一样,毕竟底层是postgresql。
3.3 数据库操作
-- greenplum命令行客户端
\l --查看所有数据库
\dn --查看所有schema
\c db_gp --切换数据库
-- 可视化客户端中使用以下操作
select datname from pg_database; -- 列出 PostgreSQL 实例中所有数据库的名称
SELECT schema_name FROM information_schema.schemata; -- 查询schema
drop database if exists db_gp; --删除数据库
DROP DATABASE 会删除数据库的系统目录项并且删除包含数据的文件目录。
3.4 创建表
CREATE [EXTERNAL] TABLE table_name(
column1 datatype [NOT NULL] [DEFAULT] [CHECK] [UNIQUE],
column2 datatype,
column3 datatype,
.....
columnN datatype,
[PRIMARY KEY()]
)[ WITH ()]
[LOCATION()]
[FORMAT]
[COMMENT]
[PARTITION BY]
[DISTRIBUTE BY ()];
- create table创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;
- external关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实际数据的路径(location)。
- comment:为表和列添加注释。
- distributed by 为表添加分布键,其必须为主键的子键。
- format 存储数据的文本类型。
- check 为表字段添加检查约束。
- unique 唯一约束,一个表中唯一和主键只能同时存在一个。
- primary key 主键设置,可以是一个或多个列。
- location:指定外部表数据存储位置。
- default:默认值。
- not null非空约束。
- with 可以添加数据追加方式,压缩格式,压缩级别,行列压缩等。
- partiton by 支持两种分区方式,范围分区(range)和列表分区(list)
在 Greenplum 中,表分为内部表(Internal Table) 和 外部表(External Table) 两种不同的表类型,分别用于存储和管理数据。
3.4.1 内部表
-
数据存储:内部表的数据直接存储在 GreenPlum 数据库的数据文件中。这意味着数据被物理存储在数据库服务器上。
-
事务管理:内部表完全支持事务管理。这包括 ACID 属性(原子性、一致性、隔离性和持久性),确保数据完整性和可靠性。
-
索引和约束:你可以在内部表上创建索引和约束,这有助于提高查询性能和维护数据完整性。
-
管理和维护:内部表可以使用数据库的全部管理和维护功能,如备份和恢复。
-
适用性:适用于需要高性能查询和事务完整性的数据。
一:内部表操作
-- 创建内部表
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY,
name VARCHAR(100),
department VARCHAR(100),
hire_date DATE
);
-- 插入数据
INSERT INTO employees (name, department, hire_date) VALUES ('John Doe', 'IT', '2020-01-01');
INSERT INTO employees (name, department, hire_date) VALUES ('Jane Smith', 'HR', '2020-02-01');
-- 查询结果
SELECT * FROM employees;
内部表是 Greenplum 中默认的表类型,数据存储在 Greenplum 集群的本地磁盘上,由 Greenplum 直接管理。
3.4.2 外部表
-
数据存储:外部表的数据存储在数据库外部,如在文件系统、Hadoop HDFS 或任何可通过 SQL/MED(SQL Management of External Data)访问的数据源。外部表仅存储数据的元数据和位置信息。
-
事务管理:外部表不支持事务管理。它们主要用于读取和加载操作,不保证 ACID 属性。
-
索引和约束:由于数据实际存储在外部,你不能在外部表上创建索引或强制执行数据库级别的约束。
-
管理和维护:外部表的管理相对简单,因为它们只是对外部数据源的引用。备份和恢复通常不适用于外部表本身,而是应用于数据源。
-
适用性:适用于 ETL(Extract, Transform, Load)操作,即从外部数据源提取数据,然后可能将其转换和加载到内部表中进行进一步处理。
假设我们有一个 CSV 文件 employee_data.csv,它存储在文件系统中,格式如下:
employee_id,name,department,hire_date
1,John Doe,IT,2020-01-01
2,Jane Smith,HR,2020-02-01
-- 开启一个高性能、并行化的文件分发服务,用于在 Greenplum 集群和外部文件系统之间高效地传输数据。
gpfdist -d /home/gpadmin/software/datas/ -p 8081 &
-- 创建外部表
CREATE EXTERNAL|WRITABLE TABLE ext_employees (
employee_id varchar(100),
name VARCHAR(100),
department VARCHAR(100),
hire_date varchar(100)
)
LOCATION ('gpfdist://hadoop102:8081/employee_data.csv')
FORMAT 'CSV';
SELECT * FROM ext_employees;
gpfdist 是 Greenplum 中用于高效数据传输的重要工具,特别适合与外部表功能结合使用。通过 gpfdist,可以实现高性能的数据加载、导出和共享。在使用过程中,注意性能优化、文件权限和网络配置,以确保数据传输的效率和稳定性。
EXTERNAL关键字创建的外部表,默认是可读外部表,这种表支持 SELECT 操作,不支持 INSERT、UPDATE、DELETE 操作。
WRITABLE关键字创建的外部表,可写外部表,这种表支持 INSERT 操作,不支持 SELECT、UPDATE、DELETE 操作。
3.4.3 外部表和内部表的区别
内部表:
- 可以对内部表进行 INSERT, UPDATE, DELETE 等操作,因为数据存储在数据库内部。
- 支持事务,可以回滚未提交的更改。
- 可以创建索引以提高查询性能。
在这里插入代码片
外部表:
- 通常只用于 SELECT 操作,用于读取外部数据源的数据。
- 不支持事务。
- 不支持索引创建。
内部表和外部表在操作和用途上的主要区别。内部表适合存储和管理数据库内的数据,而外部表适用于从外部数据源临时读取数据。
HIVE中的外部表也是只管理表的元数据,实际数据交由外部管理,并且删除表时不会删除物理数据。
3.5 修改表
3.5.1 重命名表
ALTER TABLE table_name RENAME TO new_table_name
-- 案例
alter table arr_test rename to arr; --将表arr_test重命名为arr
3.5.2 增加/修改/替换列信息
ALTER TABLE tab_name RENAME old_name TO new_name; --修改列名
ALTER TABLE tab_name ALTER COLUMN column_name TYPE column_type [USING column_name::column_type]; --修改列类型
ALTER TABLE table_name ADD|DROP COLUMN col_name [column_type]; --增加/删除列
--案例
alter table arr add column id int; --给表arr添加一个列 id int;
alter table arr rename sal to salary; --给表arr的sal列重命名为salary
alter table arr alter column id type double precision; --给表arr的id列类型由double更改为precision
alter table arr drop column id; --给表arr删除id列
3.5.3 删除表
drop table arr;
DROP TABLE 操作会直接删除表的定义和数据,如果没有备份的情况下无法自动恢复。
3.5.4 清空表
truncate table arr;
truncate只能删除内部表,不能删除外部表中数据。
四、DML(Data Manipulation Language)数据操作语言
4.1 数据导入
4.1.1 copy装载数据
COPY table_name FROM file_path DELIMITER ‘字段之间的分隔符’;
- copy: 表示加载数据到指定表中,仅追加。
- delimiter:表示读取的数据字段之间的分隔符。
准备一份文件在/home/gpadmin/software/datas/employees1.txt目录,文件内容如下:
John,IT,30
Jane,HR,25
创建一张表employees1
CREATE TABLE employees1 (
name VARCHAR(100),
department VARCHAR(50),
age INTEGER
);
将/employees1.txt文件加载到表中:
COPY employees1 FROM '/home/gpadmin/software/datas/employees1.txt' delimiter ',';
copy是追加数据,如果想要覆盖只能先truncate清空表。
4.1.2 insert插入数据
创建一张表employees2
CREATE TABLE employees2 (
name VARCHAR(100),
department VARCHAR(50),
age INTEGER
);
使用insert语句插入数据
insert into employees2 values(‘zhangsan’,'IT',18),(‘lisi’,'HR',20);
根据查询结果插入数据
insert into employees2 select * from employees1;
insert不支持覆盖数据,仅追加。
4.1.3 查询结果建表加载数据
根据查询结果创建表(查询的结果会添加到新创建的表中)。
create table employees3 as select * from employees1 ;
4.2 数据更新和删除
4.2.1 数据更新
修改数据的通用SQL语法
UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];
我们可以同时更新一个或多个字段,也可以在WHERE子句中指定任何条件
update employees3 set name='haihai' where department = 'HR';
4.2.2 数据删除
删除指定数据的通用SQL语法:
DELETE FROM table_name WHERE [condition];
如果没有指定 WHERE 子句,GreenPlum对应表中的所有记录将被删除。一般我们需要在 WHERE 子句中指定条件来删除对应的记录,条件语句可以使用 AND 或 OR 运算符来指定一个或多个。
delete from gp_test where id =1 or name = 'aimyon';
4.3 数据导出
copy employees3 to '/home/gpadmin/software/datas/test.txt';
greenplum无法导出外部表的数据,因为外部表的数据存储在外部数据源,不直接由gp管理。
gp数据库SQL的使用和Hive大差不差,除了\d这种类似的简洁命令,具体使用的时候如果不一样,可以查阅资料解决,后边就不赘述SQL了。