hadoop mr的一些文件归属(包括临时文件的存储情况)
一、概述
一个计算的流程如下图所示,对于一个简单的wordcount的计算中,总共要经历哪些文件呢?本文将详细探讨这个话题。文章可能会重新编辑,如果想浏览最新内容请访问原创博客:http://blog.csdn.net/bxyz1203/article/details/8057810。由于作者个人知识面有限,如果描述有错误或者遗留之处敬请谅解,再欢迎指出,我们共同进步。
本文分析的是0.19.1版本。其实无论是哪个版本(除了最新的2)都差不多。
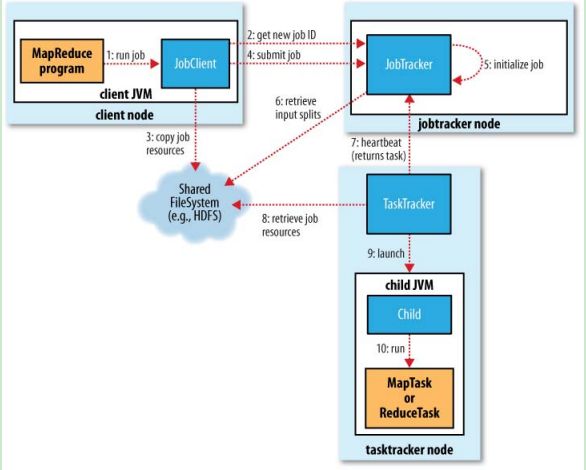
mr各种文件存储的大致目录:

一般会在{mapred.system.dir}目录中写入job.jar、job.xml、job.split文件。
2、JobTracker初始化job的时候会从hdfs中拷贝job.xml、job.split文件,为了存储JobHistory日志及获得数据分片等一些数据。
在本地{mapred.local.dir}中存储job.xml。job.xml是client 的jobConf继承taskTracker的 jobConf得到的。
-rw-r--r-- 10 dragon.caol supergroup 14612 2012-10-10 19:19 /tmp/hadoop-dragon.caol/mapred/system/job_201210101858_0001/job.jar -rw-r--r-- 1 dragon.caol supergroup 166 2012-10-10 19:19 /tmp/hadoop-dragon.caol/mapred/system/job_201210101858_0001/job.split -rw-r--r-- 1 dragon.caol supergroup 17638 2012-10-10 19:19 /tmp/hadoop-dragon.caol/mapred/system/job_201210101858_0001/job.xml drwxrwxrwx - dragon.caol supergroup 0 2012-10-10 19:19 /tmp/hadoop-dragon.caol/mapred/system/job_201210101858_0001/libjars -rw------- 1 dragon.caol supergroup 4 2012-10-10 18:59 /tmp/hadoop-dragon.caol/mapred/system/jobtracker.info3、TaskTracker通过心跳向JobTracker获得task后,一般是有四个task:jobsetup->map->reduce->jobclean。(对于比较简单的只有一个map与reduced的情况)对于任务的执行,map、reduce会执行一些用户的代码外,最终其实会落到OutputCommitter(其实这个也可以自定义的)的实现类上面。
jobsetup会从hdfs中拷贝job.jar、job.xml到{mapred.local.dir}中;后map、reduce的一些临时数据会存储到{mapred.local.dir}中;最后Jobclean会删除此job在TaskTracker的{mapred.local.dir}及{output}/_temporary中产生的一些临时数据。
3.1、对于map中间产生的一些临时数据。这些文件是由SpillThread线程生成的。包括 索引文件spill.n.out.index及数据文件spill.n.out等,这些文件的组织相对比较复杂。最后会被reduce调用http RESTful请求来获取。
3.2、对于reduce的一部分数据会存储到hdfs的output的_temporary中,当reduce完成时会转移最终生成文件到输出根目录。(当然对于一般的情况下,reduce开始的阶段会从map的临时文件中拷贝数据,所以一般reduce不完成,map产生的数据也不会被删除)
4、日志文件(过程中产生的,没有具体的步骤。)
4.1、JobHistory存储在{output}/_logs/history中,这个也是最后剩下在hdfs中的日志了。分为两部分,一个部分存储jobclient提交的job.xml;一部分存储执行过程中的数据。这个日志我们一般可以拿来分析任务的执行过程,例如导入Gridmix模拟线上场景做压力测试。注意这里存储的job.xml是client 的jobConf继承JobTracker的 jobConf得到的。
4.2、还有一些文件日志都是放在计算执行过程中的磁盘上,参见:附二。基本在{HADOOP_HOME}/logs文件中。此些是System.out/err及log4j产生的一些日志。对于map、reduce的任务,由于是用户自定义的,可能产生的日志量非常大,我们一般会限制日志输出的大小或者条数。
一个job执行完成,其实在{mapred.sysrem.dir}/{jobid}及{mapred.local.dir}/{jobid}数据都会删除的。最终剩下的也就是:{output}中的一些文件,一般包括:part-r-xxxxx最终结果文件及JobHistory;再就是在各个本地磁盘上面的log日志了。
ps:
附一:看下{mapred.local.dir}的目录结构<其中jobTracker、taskTracker分别在各自的机器上面>
.
|-- jobTracker
| `-- job_201210101610_0003.xml
`-- taskTracker
`-- jobcache
`-- job_201210101610_0003
|-- attempt_201210101610_0003_m_000000_0
| |-- job.xml
| |-- output
| | |-- file.out
| | `-- file.out.index
| |-- pid
| `-- split.dta
|-- attempt_201210101610_0003_m_000001_0
| |-- job.xml
| `-- work
|-- jars
| |-- META-INF
| | |-- MANIFEST.MF
| | `-- Executor.class
。。。。。。省去一些解压缩的文件
| `-- job.jar
|-- job.xml
`-- work
附二:看下:logs目录:
<其中 hadoop-dragon.caol-xxxx是由守护进程记录的日志,各自分散在自己的机器上;userlogs是由taskTracker产生的,
也是存储在taskTracker的机器上面;再其他都是存储在JobTracker上面。>
.
|-- hadoop-dragon.caol-datanode-hd19-vm1.yunti.yh.aliyun.com.log
|-- hadoop-dragon.caol-datanode-hd19-vm1.yunti.yh.aliyun.com.out
|-- hadoop-dragon.caol-jobtracker-hd19-vm1.yunti.yh.aliyun.com.log
|-- hadoop-dragon.caol-jobtracker-hd19-vm1.yunti.yh.aliyun.com.out
|-- hadoop-dragon.caol-namenode-hd19-vm1.yunti.yh.aliyun.com.log
|-- hadoop-dragon.caol-namenode-hd19-vm1.yunti.yh.aliyun.com.out
|-- hadoop-dragon.caol-secondarynamenode-hd19-vm1.yunti.yh.aliyun.com.log
|-- hadoop-dragon.caol-secondarynamenode-hd19-vm1.yunti.yh.aliyun.com.out
|-- hadoop-dragon.caol-tasktracker-hd19-vm1.yunti.yh.aliyun.com.log
|-- hadoop-dragon.caol-tasktracker-hd19-vm1.yunti.yh.aliyun.com.out
|-- history
| |-- h1_1349856617736_job_201210101610_0003_conf.xml
| `-- h1_1349856617736_job_201210101610_0003_dragon.caol_word+count
|-- history.idx
|-- job_201210101610_0003_conf.xml
`-- userlogs
`-- job_201210101610_0003
|-- attempt_201210101610_0003_m_000000_0
| |-- log.index
| |-- stderr
| |-- stdout
| `-- syslog
|-- attempt_201210101610_0003_m_000001_0
| |-- log.index
| |-- stderr
| |-- stdout
| `-- syslog
|-- attempt_201210101610_0003_m_000002_0
| |-- log.index
| |-- stderr
| |-- stdout
| `-- syslog
`-- attempt_201210101610_0003_r_000000_0
|-- log.index
|-- stderr
|-- stdout
`-- syslog