软件设计模式之(三) 解释器模式
欢迎大家提出意见,一起讨论!
转载请标明是引用于 http://blog.csdn.net/chenyujing1234
例子代码:(编译工具:Eclipse)
http://www.rayfile.com/zh-cn/files/1291b5bd-9418-11e1-b6a1-0015c55db73d/
参考书籍: <<软件秘笈-----设计模式那点事>>
1、创建自己的语言解释器
2、模式定义
3、模式分析
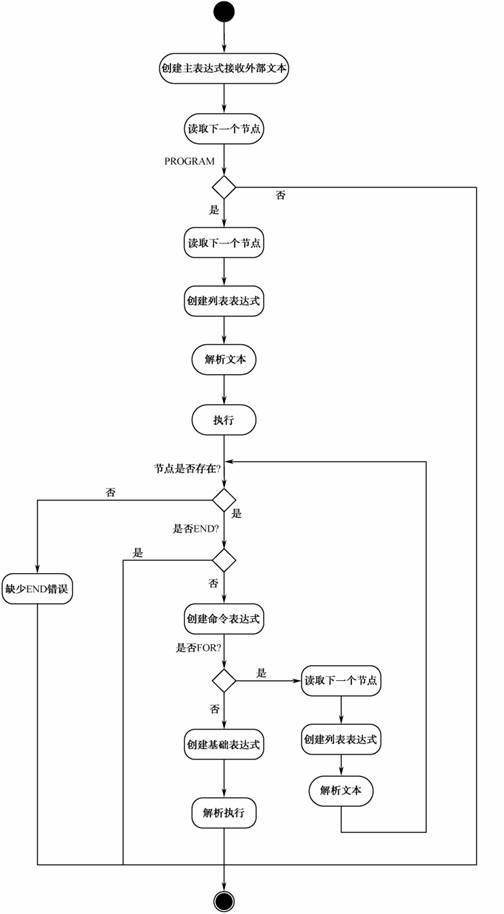
4、模式实现
4.1 创建上下文环境
创建Context环境类,该类主要用于保存待执行的语句、当前节点和动态参数内容,还有一些操作内部属性的公共方法。
该类中的getTokenContent方法是用来获得含有动态参数的节点内容的。eg:FOR语句中的i从90到100 就是一个动态内容。
/**
* 上下文环境
*
* @author
*
*/
public class Context {
// 待解析的文本内容
private final StringTokenizer stringTokenizer;
// 当前命令
private String currentToken;
// 用来存储动态变化信息内容
private final Map<String, Object> map = new HashMap<String, Object>();
/**
* 构造方法设置解析内容
*
* @param text
*/
public Context(String text) {
// 使用空格分隔待解析文本内容
this.stringTokenizer = new StringTokenizer(text);
}
/**
* 解析文本
*/
public String next() {
if (this.stringTokenizer.hasMoreTokens()) {
currentToken = this.stringTokenizer.nextToken();
} else {
currentToken = null;
}
return currentToken;
}
/**
* 判断命令是否正确
*
* @param command
* @return
*/
public boolean equalsWithCommand(String command) {
if (command == null || !command.equals(this.currentToken)) {
return false;
}
return true;
}
/**
* 获得当前命令内容
*
* @return
*/
public String getCurrentToken() {
return this.currentToken;
}
/**
* 获得节点的内容
*
* @return
*/
public String getTokenContent(String text) {
String str = text;
if (str != null) { // 替换map中的动态变化内容后返回 Iterator<String>
// 替换map中的动态变化内容后返回
Iterator<String> iterator = this.map.keySet().iterator();
while (iterator.hasNext()) {
String key = iterator.next();
Object obj = map.get(key);
str = str.replaceAll(key, obj.toString());
}
}
return str;
}
public void put(String key, Object value) {
this.map.put(key, value);
}
public void clear(String key) {
this.map.remove(key);
}
}
4、2 主表达式----ProgramExpression
创建ProgramExpression实现IExpressions
/**
*
* 表达式接口
*
* @author
*
*/
public interface IExpressions {
/**
* 解析
*
* @param context
*/
public void parse(Context context);
/**
* 执行方法
*
* @param context
*/
public void interpret();
}
ProgramExpression 在解析方法中,读取下一个节点,即语句文本的第一个节点的内容;在执行方法中,判断当前节点内容。
/**
* program 表达式
*
* @author
*
*/
public class ProgramExpression implements IExpressions {
// 上下文环境
private final Context context;
// 当前命令
private final static String COMMAND = "PROGRAM";
// 存储下一个表达式引用
private IExpressions expressions;
/**
* 构造方法将待解析的内容传入
*
* @param text
*/
public ProgramExpression(String text) {
this.context = new Context(text);
this.parse(this.context);
}
@Override
public void parse(Context context) {
// 获取第一个命令节点
this.context.next();
}
/**
* 实现解释方法
*/
@Override
public void interpret() {
// 判断是否是以PROGRAM 开始
if (!this.context.equalsWithCommand(COMMAND)) {
System.out.println("The '" + COMMAND + "' is Excepted For Start!");
} else {
// 是以PROGRAM 开始
this.context.next();
this.expressions = new ListExpression();
this.expressions.parse(this.context);
// ListExpression表达式开始解析
this.expressions.interpret();
}
}
}
4.3 列表表达式---ListExpression
有一个私有属性内容,是存储命令语句的列表。while(true)循环中的CommandExpression命令表达式使while能跳出循环,
因为它会继续入下读取节点内容进行解析。
/**
* 列表表达式
*
* @author
*
*/
public class ListExpression implements IExpressions {
private Context context;
private final ArrayList<IExpressions> list = new ArrayList<IExpressions>();
/**
* 构造方法将待解析的context传入
*
* @param context
*/
public void parse(Context context) {
this.context = context;
// 在ListExpression解析表达式中,循环解释语句中的每一个单词,直到终结符表达式或者异常情况退出
while (true) {
if (this.context.getCurrentToken() == null) {
// 获取当前节点如果为 null 则表示缺少END表达式
System.out.println("Error: The Experssion Missing 'END'! ");
break;
} else if (this.context.equalsWithCommand("END")) {
this.context.next();
// 解析正常结束
break;
} else {
// 建立Command 表达式
IExpressions expressions = new CommandExperssion(this.context);
// 添加到列表中
list.add(expressions);
}
}
}
/**
* 实现解释方法
*/
@Override
public void interpret() {
// 循环list列表中每一个表达式 解释执行
Iterator<IExpressions> iterator = list.iterator();
while (iterator.hasNext()) {
(iterator.next()).interpret();
}
}
}
4.4 命令表达式----CommandExpression
它的内容是增加一项内容,该表达式相当于一个门面,用来统一解析复杂表达式语句和基础表达式语句.
命令表达式的内容很简单,解析方法就是判断当前节点是复杂表达式还是基础表达式,然后分别创建相应的表达式内容进行解析。
/**
* 命令表达式
*
* @author
*
*/
public class CommandExperssion implements IExpressions {
private final Context context;
private IExpressions expressions;
/**
* 构造方法将待解析的context传入
*
* @param context
*/
public CommandExperssion(Context context) {
this.context = context;
this.parse(this.context);
}
public void parse(Context context) {
// 判断当前命令类别 在此只对For和最原始命令进行区分
if (this.context.equalsWithCommand("FOR")) {
// 创建For表达式进行解析
expressions = new ForExpression(this.context);
} else {
// 创建原始命令表达式进行内容解析
expressions = new PrimitiveExpression(this.context);
}
}
/**
* 解析内容
*/
@Override
public void interpret() {
// 解析内容
this.expressions.interpret();
}
}
4.5 循环表达式 ----- ForExpression
该类的内容比较复杂,我们需要保存循环变量内容,还要解析变量循环的起始位置信息并保存,然后创建列表表达式进行下一步解析。
循环表达式中的解析方法需要解析变量内容,以及变量的起始位置信息,然后创建列表表达式进行解析;执行方法则是从开始位置到结束位置进行循环,
设置变量内容,调用列表表达式的执行方法,最后清除临时变量信息。
/**
* For表达式
*
* @author
*
*/
public class ForExpression implements IExpressions {
private final Context context;
// 存储当前索引key值
private String variable;
// 存储循环起始位置
private int start_index;
// 存储循环结束位置
private int end_index;
private IExpressions expressions;
/**
* 构造方法将待解析的context传入
*
* @param context
*/
public ForExpression(Context context) {
this.context = context;
this.parse(this.context);
}
/**
* 解析表达式
*/
@Override
public void parse(Context context) {
// 首先获取当前节点
this.context.next();
while (true) {
// 判断节点
if (this.context.equalsWithCommand("FROM")) {
// 设置开始索引内容
String nextStr = this.context.next();
try {
this.start_index = Integer.parseInt(nextStr);
} catch (Exception e) {
System.out
.println("Error: After 'FROM' Expression Exist Error!Please Check the Format Of Expression is Correct!");
break;
}
// 获取下一个节点
this.context.next();
} else if (this.context.equalsWithCommand("TO")) {
// 设置结束索引内容
String nextStr = this.context.next();
try {
this.end_index = Integer.parseInt(nextStr);
} catch (Exception e) {
System.out
.println("Error: After 'TO' Expression Exist Error!Please Check the Format Of Expression is Correct!");
}
this.context.next();
break;
} else {
// 设置当前索引变量内容
if (this.variable == null) {
this.variable = this.context.getCurrentToken();
}
// 获取下一个节点
this.context.next();
}
}
// 建立列表表达式
this.expressions = new ListExpression();
this.expressions.parse(this.context);
}
/**
* 实现解释方法
*/
@Override
public void interpret() {
// 建立命令表达式
for (int x = this.start_index; x <= this.end_index; x++) {
// 设置变量内容
this.context.put("" + this.variable, x);
// 执行解释方法
this.expressions.interpret();
}
// 移除使用的临时变量内容
this.context.clear("" + this.variable);
}
}
4.6 基础表达式 ---- PrimitiveExpression
根据当前节点内容执行相应的操作。
解析方法获得当前节点内容,以及将执行内容信息:执行方法判断当前节点内容,如果是PRINTLN,则打印内容。
/**
* 最基础的表达式
*
* @author
*
*/
public class PrimitiveExpression implements IExpressions {
private Context context;
// 节点名称
private String tokenName;
// 文本内容
private String text;
/**
* 构造方法将待解析的context传入
*
* @param context
*/
public PrimitiveExpression(Context context) {
this.parse(context);
}
@Override
public void parse(Context context) {
this.context = context;
this.tokenName = this.context.getCurrentToken();
this.context.next();
if ("PRINTLN".equals(this.tokenName)) {
this.text = this.context.getCurrentToken();
this.context.next();
}
}
/**
* 实现解释方法
*/
@Override
public void interpret() {
// 首先获取当前节点内容
if ("PRINTLN".equals(tokenName)) {
// 获得内容信息
// 打印内容
System.out.println(this.context.getTokenContent(this.text));
}
}
}
5、让"mydia"语言解释器开始工作
创建Client客户端应用程序。
/**
* 主应用程序
*
* @author
*
*/
public class Client {
/**
* @param args
*/
public static void main(String[] args) {
// myida语言语句
String str = "PROGRAM PRINTLN start... FOR i FROM 90 TO 100 PRINTLN i END PRINTLN end... END";
System.out.println("str:" + str);
// 创建PROGRAM表达式
IExpressions expressions = new ProgramExpression(str);
// 解释执行
expressions.interpret();
}
}
首先定义了"mydia"语言的语句,然后打印该语句内容,接下来就是创建主表达式,将待解析的语句传入,然后解释执行。
结果:
str:PROGRAM PRINTLN start... FOR i FROM 90 TO 100 PRINTLN i END PRINTLN end... END start... 90 91 92 93 94 95 96 97 98 99 100 end...
6、设计原则
1、“开-闭”原则。
解释器模式其实就是一个语法分析工具,它最显著的设计原则表面在扩展性方面,我们修改语法规则只需要修改相应的非终结表达式就可以了,如果要增加
新的语法规则,则只需要增加非终结表达式就可以了。(即增加与ForExpression、PrimitiveExpression类似的表达式)避免了一般情况下修改复杂烦琐的解析程序。
然而,解释器模式的不足在于,如果一个语言的语法规则非常复杂,就会引起表达式膨胀,为维护带来困难。
2、封装变化部分
解释器模式将可能变化的部分封装在非终结符表达式中,这使得修改语法规则和增加规则只能针对非终结符进行,而不必修改终结表达式内容。
有效地进行软件结构的扩展。