Visual Tracking with Fully Convolutional Networks 笔记
简单介绍一下背景,这篇文章是大连理工的卢湖川教授http://202.118.75.4/lu/publications.html
的学生Lijun Wang在港中文与Xiaogang Wang团队合作的ICCV2015的文章。笔者7月份在CUHK听报告的时候有幸提前看到相关的展示,感觉结果很惊人。Prof Xiaogang Wang是深度学习的大牛,卢湖川教授是tracking的大牛,这篇文章可谓是强强联合的产物。
开始说这篇文章。作者首先首先从visual tracking的角度针对CNN网络进行研究,
两个属性
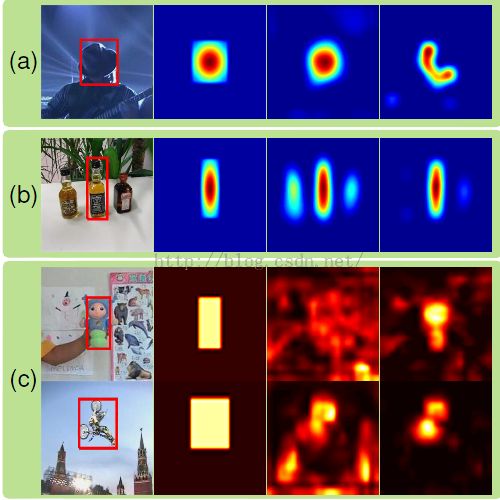
1)不同层上的CNN特征可以针对不同的tracking问题。越top层的特征越抽象,并且具有语义信息。这些特征的优势在于区分不同类别,同时对于形变和遮挡robust(下图a)。但是他们的缺点是无法区别类内的物体,比如不同人(下图b)。而底层的特征更多的是局部特征,可以帮助将目标从背景中分离出来(下图b)。但是无法处理目标外表剧烈变化(下图a)。于是在tracking中作者将两个特征根据干扰的情况,实时切换两种特征。
三个方面的贡献:
1) 分析了从大规模图像分类中学到的CNN特征,找出适合于visual tracking的一些属性。也就是不同的computer vision tasks需要 不同的特征。
2)作者提出了一种新的tracking的方法,同时考虑两个不同卷积层的特征输出,使他们相互补充来处理剧烈的外观变化和区分目标本身。
3)设计了一种方法来自动选择区分性的feature maps,同时忽略掉另外一个以及噪声。
整体框架:
解释如下:
第一步,对于给定的target,对VGG网络的conv4-3和conv5-3层执行feature map selection,目的是选出最相关的feature maps,具体原因就是构建一个L1范数的正则化目标函数。
第二步,在conv5-3的feature maps基础上,构造一个通用网络GNet,用来捕捉目标的类别信息
第三步,在conv4-3的feature maps基础上,构造一个特定网络SNet,用来将目标从背景中区分出来。
第四步,利用第一帧图像来初始化GNet和SNet,但是两个网络采用不用的更新方法
第五步, 对于新的一帧图像,感兴趣区域(ROI)集中在上一帧的目标位置,包含目标和背景上下文信息,通过全卷积网络传递。
第六步,GNet和SNet网络各自产生一个前景heat map。于是对下一帧目标位置的预测就基于这两个热图。
第七步,干扰项检测用来决定采用上一步产生的哪一个热图,从而决定最后目标的位置。
一些细节
值得一提的是作者采用了很多细节的技术,这些对于提升效果很有帮助。
比如对于模型的更新,作者将目标漂移以及热图匹配同时考虑在内。