MP算法与OMP算法
稀疏编码的一般最优化公式为:
其中的零范数为非凸优化。那么如何解这么一个非凸优化问题呢?其中一个常用的解法就是MP算法。
MP算法
MP算法是一种贪心算法(greedy),每次迭代选取与当前样本残差最接近的原子,直至残差满足一定条件。
求解方法
首先解决两个问题,怎么定义“最接近原子”,怎么计算残差?
选择最接近残差的原子:MP里定义用向量内积原子与残差的距离,我们用R表示残差,di表示原子,则:
Max[Dist(R,di)]=max[<R,di>];
残差更新:R=R-<R,di>I;继续选择下一个,直至收敛;
需要注意的是,MP算法中要求字典原子||di||=1,上面的公式才成立。
我们用二维空间上的向量来表示,用如下的图来表述上面的过程:
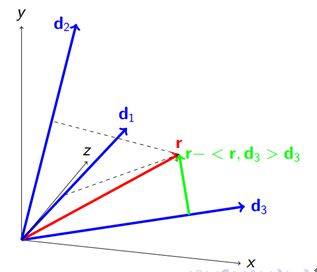
上图中d1,d2,d3表示归一化的原子,红色向量r表示当前残差;
进过内积计算,<r,d3>最大,于是r分解为d3方向以及垂直于d3方向的两个向量(<r,d3>d3及r-<r,d3>d3),把d3方向的分量(<r,d3>d3)加入到已经求得的重构项中,那么绿色向量(r-<r,d3>d3)变为新的残差。
再一轮迭代得到如下:
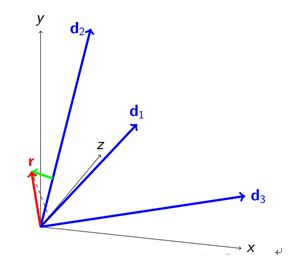
R往d1方向投影分解,绿色向量成为新的残差。
具体算法:

收敛性
从上面的向量图我们可以清楚地看出,k+1的残差Rk+1是k步残差Rk的分量。根据直角三角形斜边大于直角边,|Rk+1|<=|Rk|,则算法收敛。
注意事项:
1.上面也讲过,字典的原子是归一化的,也就是||di||=1,因为我们选取max<R,di>时,如果di长度不统一,不能得出最好的投影。
2.如果我们的字典只有两个向量d1,d2,那么MP算法会在这两个向量间交叉迭代投影,也就是f=a1d1+a2d2+a3d1+a4d2+…..;也就是之前投影过的原子方向,之后还有可能投影。换句话说,MP的方向选择不是最优的,是次优的。
如下图:

这也是其改进版本OMP要改进的地方。
OMP算法
也就是正交的MP算法。
MP算法的次最优性来源其残差只与当前投影方向垂直,这样在接下来的投影中,很有可能会再次投影到原来的方向。
于是,在投影时,如果我们使得残差Rk+1与x1-xk+1的所有向量垂直,则可以克服这个问题,如下:
![]()
求解方法
假设我们已经得到了第k步的最优解:
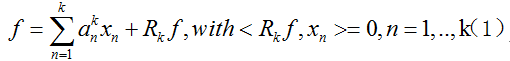
我们要继续更新到第k+1步,目标是得到:
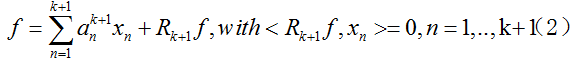
需要注意的是,我们下一步更新时,之前原子的系数 也要更新,否则不能满足约束。
于是我们需要求得如何更新之前原子系数 ,以及如何求得下一个投影方向 。

收敛性:
同样根据勾股定理,得到如下:

于是算法收敛。
具体步骤:


最后,贴一个sparse求解的工具包,里面包含了MP,OMP算法的代码:
http://spams-devel.gforge.inria.fr/
参考文献:
http://lear.inrialpes.fr/people/mairal/tutorial_iccv09/
http://blog.csdn.net/scucj/article/details/7467955
OrthogonalMatching Pursuit:Recursive Function Approximation with Applications to WaveletDecomposition