OMAP3630下的Linux SPI总线驱动分析(2)
4 OMAP3630 SPI 控制器驱动
在Linux内核中,SPI 控制器驱动位于drivers/spi目录下,OMAP3630 的spi控制器驱动程序为omap2_mcspi.c。SPI 控制器驱动的注册采用Platform设备和驱动机制。
4.1 SPI 控制器的Platform device
Android2.1中Platform device的注册代码位于内核的arch/arm/mach-omap2/devices.c中。4.1.1 Platform device的定义
在文件arch/arm/mach-omap2/devices.c中,Platform device定义如下:
static struct omap2_mcspi_platform_config omap2_mcspi1_config = {
.num_cs = 4,
};
static struct resource omap2_mcspi1_resources[] = {
{
.start = OMAP2_MCSPI1_BASE,
.end = OMAP2_MCSPI1_BASE + 0xff,
.flags = IORESOURCE_MEM,
},
};
static struct platform_device omap2_mcspi1 = {
.name = "omap2_mcspi",
.id = 1,
.num_resources = ARRAY_SIZE(omap2_mcspi1_resources),
.resource = omap2_mcspi1_resources,
.dev = {
.platform_data = &omap2_mcspi1_config,
},
};
static struct omap2_mcspi_platform_config omap2_mcspi2_config = {
.num_cs = 2,
};
static struct resource omap2_mcspi2_resources[] = {
{
.start = OMAP2_MCSPI2_BASE,
.end = OMAP2_MCSPI2_BASE + 0xff,
.flags = IORESOURCE_MEM,
},
};
static struct platform_device omap2_mcspi2 = {
.name = "omap2_mcspi",
.id = 2,
.num_resources = ARRAY_SIZE(omap2_mcspi2_resources),
.resource = omap2_mcspi2_resources,
.dev = {
.platform_data = &omap2_mcspi2_config,
},
};
#if defined(CONFIG_ARCH_OMAP2430) || defined(CONFIG_ARCH_OMAP3)
static struct omap2_mcspi_platform_config omap2_mcspi3_config = {
.num_cs = 2,
};
static struct resource omap2_mcspi3_resources[] = {
{
.start = OMAP2_MCSPI3_BASE,
.end = OMAP2_MCSPI3_BASE + 0xff,
.flags = IORESOURCE_MEM,
},
};
static struct platform_device omap2_mcspi3 = {
.name = "omap2_mcspi",
.id = 3,
.num_resources = ARRAY_SIZE(omap2_mcspi3_resources),
.resource = omap2_mcspi3_resources,
.dev = {
.platform_data = &omap2_mcspi3_config,
},
};
#endif
#ifdef CONFIG_ARCH_OMAP3
static struct omap2_mcspi_platform_config omap2_mcspi4_config = {
.num_cs = 1,
};
static struct resource omap2_mcspi4_resources[] = {
{
.start = OMAP2_MCSPI4_BASE,
.end = OMAP2_MCSPI4_BASE + 0xff,
.flags = IORESOURCE_MEM,
},
};
static struct platform_device omap2_mcspi4 = {
.name = "omap2_mcspi",
.id = 4,
.num_resources = ARRAY_SIZE(omap2_mcspi4_resources),
.resource = omap2_mcspi4_resources,
.dev = {
.platform_data = &omap2_mcspi4_config,
},
};
#endif
可以看到,这边定义了4个SPI控制器的Platform device,id分别为“1,2,3, 4”,name都为“omap2_mcspi”,变量resource中定义了适配器的寄存器基地址。
4.1.2 Platform device的注册
Platform device的注册是由内核启动时完成的。在文件arch/arm/mach-omap2/devices.c中,具体的代码如下:static int __init omap2_init_devices(void) { /* please keep these calls, and their implementations above, * in alphabetical order so they're easier to sort through. */ omap_hsmmc_reset(); omap_init_camera(); omap_init_mbox(); omap_init_mcspi(); omap_init_sti(); omap_init_sha1_md5(); return 0; } arch_initcall(omap2_init_devices);
内核启动时会调用函数omap2_init_devices(),函数omap2_init_devices ()再调到spi的初始化函数omap_init_mcspi(),omap_init_mcspi()代码如下:
static void omap_init_mcspi(void)
{
platform_device_register(&omap2_mcspi1);
platform_device_register(&omap2_mcspi2);
#if defined(CONFIG_ARCH_OMAP2430) || defined(CONFIG_ARCH_OMAP3)
if (cpu_is_omap2430() || cpu_is_omap343x())
platform_device_register(&omap2_mcspi3);
#endif
#ifdef CONFIG_ARCH_OMAP3
if (cpu_is_omap343x())
platform_device_register(&omap2_mcspi4);
#endif
}
函数omap2_init_devices()通过调用platform_device_register()将Platform device注册到Platform总线上,完成注册后,寄存器的基地址等信息会在设备树中描述了,此后只需利用platform_get_resource等标准接口自动获取即可,实现了驱动和资源的分离。
4.2 SPI 控制器的Platform driver
Andrord 2.1中Platform driver的注册代码位于内核的drivers/spi/omap2_mcspi.c中,该驱动的注册目的是初始化OMAP3630的SPI 控制器,提供SPI总线数据传输的具体实现,并且向spi core层注册spi 控制器。4.2.1 Platform driver的定义
在文件drivers/spi/omap2_mcspi.c中,platform driver定义如下:static struct platform_driver omap2_mcspi_driver = {
.driver = {
.name = "omap2_mcspi",
.owner = THIS_MODULE,
},
.remove = __exit_p(omap2_mcspi_remove),
};
可以看到,这里的name字段与4.1.1中定义的Platform device的name字段相同,用于驱动和设备匹配时使用。
4.2.2 Platform driver的注册
在文件drivers/spi/omap2_mcspi.c中,platform driver注册如下:static int __init omap2_mcspi_init(void)
{
omap2_mcspi_wq = create_singlethread_workqueue(
omap2_mcspi_driver.driver.name);
if (omap2_mcspi_wq == NULL)
return -1;
return platform_driver_probe(&omap2_mcspi_driver, omap2_mcspi_probe);
}
subsys_initcall(omap2_mcspi_init);
在内核启动时会调用函数omap2_mcspi_init(),该函数先创建一个名字为"omap2_mcspi"的workqueue,第二章中提到过spi的数据传输是基于workqueue的,所以这边的初始化函数会首先创建一个workqueue。Workqueue创建成功后才会用函数platform_driver_probe()来注册Platform driver,该函数是带有probe函数的平台驱动注册函数,用于非hot-plug设备。
注册时,会扫描platform bus上的所有设备,由于匹配因子name为" omap2_mcspi ",因此与4.1.1节中注册的Platform device匹配成功,于是函数omap2_mcspi_probe()将被调用,控制器device和driver将被绑定起来。
在文件drivers/spi/omap2_mcspi.c中会涉及到一个数据结构omap2_mcspi,这个结构定义了专门针对omap3630的SPI控制器结构,代码如下:
struct omap2_mcspi {
struct work_struct work;
/* lock protects queue and registers */
spinlock_t lock;
struct list_head msg_queue;
struct spi_master *master;
struct clk *ick;
struct clk *fck;
/* Virtual base address of the controller */
void __iomem *base;
unsigned long phys;
/* SPI1 has 4 channels, while SPI2 has 2 */
struct omap2_mcspi_dma *dma_channels;
};
msg_queue对应消息队列。master对应通用的spi控制器结构。
ick和fck分别对应接口时钟和功能时钟。
base对应SPI控制器寄存器的虚拟地址。
phys对应SPI控制器寄存器的物理地址。
dma_channels对应SPI控制器的DMA通道。
函数omap2_mcspi_probe()的执行流程如下图:
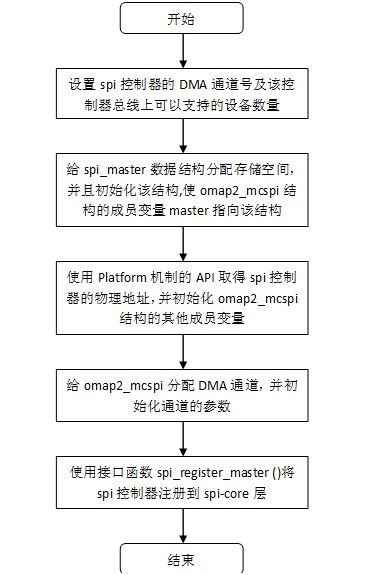
图4.1 omap2_mcspi_probe()的执行流程
函数omap2_mcspi_probe()的简要代码如下:
static int __init omap2_mcspi_probe(struct platform_device *pdev)
{
struct spi_master *master;
struct omap2_mcspi *mcspi;
……
switch (pdev->id) {
case 1:
rxdma_id = spi1_rxdma_id;
txdma_id = spi1_txdma_id;
num_chipselect = 4;
break;
case 2:
……
#if defined(CONFIG_ARCH_OMAP2430) || defined(CONFIG_ARCH_OMAP3)
case 3:
……
#endif
#ifdef CONFIG_ARCH_OMAP3
case 4:
……
#endif
default:
return -EINVAL;
}
master = spi_alloc_master(&pdev->dev, sizeof *mcspi);
……
if (pdev->id != -1)
master->bus_num = pdev->id;
master->setup = omap2_mcspi_setup;
master->transfer = omap2_mcspi_transfer;
master->cleanup = omap2_mcspi_cleanup;
master->num_chipselect = num_chipselect;
dev_set_drvdata(&pdev->dev, master);
mcspi = spi_master_get_devdata(master);
mcspi->master = master;
r = platform_get_resource(pdev, IORESOURCE_MEM, 0);
if (r == NULL) {
status = -ENODEV;
goto err1;
}
if (!request_mem_region(r->start, (r->end - r->start) + 1,
pdev->dev.bus_id)) {
status = -EBUSY;
goto err1;
}
mcspi->phys = r->start;
mcspi->base = ioremap(r->start, r->end - r->start + 1);
……
INIT_WORK(&mcspi->work, omap2_mcspi_work);
spin_lock_init(&mcspi->lock);
INIT_LIST_HEAD(&mcspi->msg_queue);
mcspi->ick = clk_get(&pdev->dev, "mcspi_ick");
……
mcspi->fck = clk_get(&pdev->dev, "mcspi_fck");
……
mcspi->dma_channels = kcalloc(master->num_chipselect,
sizeof(struct omap2_mcspi_dma),
GFP_KERNEL);
……
for (i = 0; i < num_chipselect; i++) {
mcspi->dma_channels[i].dma_rx_channel = -1;
mcspi->dma_channels[i].dma_rx_sync_dev = rxdma_id[i];
mcspi->dma_channels[i].dma_tx_channel = -1;
mcspi->dma_channels[i].dma_tx_sync_dev = txdma_id[i];
}
……
status = spi_register_master(master);
……
return status;
……
}
可以看到,omap2_mcspi_probe()函数会给spi_master的赋setup,transfer等初始化以及数据传输函数,为了能提高spi的传输速度,一般会采用DMA模式,最后使用了spi_register_master ()将spi控制器注册到spi core层,在4.1.1节中定义了4个SPI总线设备,所以这里会建立4个spi控制器,总线号分别为1,2,3,4。
5 OMAP3630 SPI 设备驱动
在Linux内核中,SPI 设备可以是各种SPI接口的设备,设备可以有不同的用途,这里以Ti的触摸屏控制器芯片tsc2005为例来介绍SPI设备驱动的注册过程,对应的设备驱动程序为tsc2005.c,位于目录drivers/input/touchscreen下。5.1 Tsc2005设备注册
Tsc2005设备的创建以及注册分为两步。5.1.1 将tsc2005设备信息加入到设备链表
在板级初始化时将tsc2005的名称,地址和相关的信息加入到链表board_list中,该链表定义在driver/spi/spi.c中,记录了具体开发板上的SPI设备信息。static LIST_HEAD(board_list);
在board-xxxx.c中,tsc2005设备信息定义如下:static struct spi_board_info xxxx_spi_board_info[] __initdata = {
……
{
.modalias = "tsc2005",
.platform_data = &tsc2005_config,
.controller_data = &touchscreen_spi_cfg,
.mode = SPI_MODE_1,
.irq = OMAP_GPIO_IRQ(TS_GPIO),
.max_speed_hz = 700000,
.bus_num = 0,
.chip_select = 2,
},
};
Tsc2005设备信息通过函数spi_register_board_info()加入到链表board_list中,代码如下:
static void __init omap_xxxx_init(void)
{
omap_i2c_init();
……
spi_register_board_info(xxxx_spi_board_info,
ARRAY_SIZE(xxxx_spi_board_info));
……
}
Tsc2005加入到设备链表board_list的流程图如下图:
图5.1 tsc2005加入到SPI设备链表的过程
spi_register_board_info()函数的定义在driver/spi/spi.c中,如下:
int __init spi_register_board_info(struct spi_board_info const *info, unsigned n)
{
struct boardinfo *bi;
bi = kmalloc(sizeof(*bi) + n * sizeof *info, GFP_KERNEL);
if (!bi)
return -ENOMEM;
bi->n_board_info = n;
memcpy(bi->board_info, info, n * sizeof *info);
mutex_lock(&board_lock);
list_add_tail(&bi->list, &board_list);
mutex_unlock(&board_lock);
return 0;
}
5.1.2 Tsc2005 spi_device的创建并添加
Tsc2005 spi_device的创建并添加在SPI控制器驱动注册过程中完成,SPI 控制器驱动的注册可以参考4.2.2节,spi_register_master()函数在注册SPI控制器驱动的过程会扫描5.1.1中提到的SPI设备链表board_list,如果该总线上有对应的SPI设备,则创建相应的 spi_device,并将其添加到SPI的设备链表中。流程图如下所示:
图5.2创建并添加spi_device
相应的代码位于driver/spi/spi.c,如下:
int spi_register_master(struct spi_master *master)
{
static atomic_t dyn_bus_id = ATOMIC_INIT((1<<15) - 1);
struct device *dev = master->dev.parent;
int status = -ENODEV;
int dynamic = 0;
……
status = device_add(&master->dev);
……
scan_boardinfo(master);
……
}
函数spi_register_master()调用scan_boardinfo()函数扫描板级的设备。
static void scan_boardinfo(struct spi_master *master)
{
struct boardinfo *bi;
mutex_lock(&board_lock);
list_for_each_entry(bi, &board_list, list) {
struct spi_board_info *chip = bi->board_info;
unsigned n;
for (n = bi->n_board_info; n > 0; n--, chip++) {
if (chip->bus_num != master->bus_num)
continue;
/* NOTE: this relies on spi_new_device to
* issue diagnostics when given bogus inputs
*/
(void) spi_new_device(master, chip);
}
}
mutex_unlock(&board_lock);
}
在scan_boardinfo()函数中遍历SPI设备链表board_list,设备的总线号和控制器的总线号相等,则使用函数spi_new_device()创建该设备。
struct spi_device *spi_new_device(struct spi_master *master,
struct spi_board_info *chip)
{
struct spi_device *proxy;
int status;
……
proxy = spi_alloc_device(master);
……
proxy->chip_select = chip->chip_select;
proxy->max_speed_hz = chip->max_speed_hz;
proxy->mode = chip->mode;
proxy->irq = chip->irq;
strlcpy(proxy->modalias, chip->modalias, sizeof(proxy->modalias));
proxy->dev.platform_data = (void *) chip->platform_data;
proxy->controller_data = chip->controller_data;
proxy->controller_state = NULL;
status = spi_add_device(proxy);
if (status < 0) {
spi_dev_put(proxy);
return NULL;
}
return proxy;
}
在函数spi_new_device ()中使用函数spi_alloc_device()创建一个spi_device,spi_alloc_device()代码如下:
struct spi_device *spi_alloc_device(struct spi_master *master)
{
struct spi_device *spi;
struct device *dev = master->dev.parent;
if (!spi_master_get(master))
return NULL;
spi = kzalloc(sizeof *spi, GFP_KERNEL);
……
spi->master = master;
spi->dev.parent = dev;
spi->dev.bus = &spi_bus_type;
spi->dev.release = spidev_release;
device_initialize(&spi->dev);
return spi;
}
首先为spi_device分配内存空间,接着初始化该结构体,将该设备的bus初始化为spi_bus_type,说明该设备将被挂接到SPI总线上,方便与spi driver匹配,初始化master为当前的SPI控制器。从spi_alloc_device()函数返回后继续初始化spi_device结构体的chip_select,mode,modalias, controller_data等变量,这里的proxy->modalias被初始化为chip->modalias,在5.1.1中,chip->modalias初始化为“tsc2005”,proxy->modalias后面会用于spi device和spi driver匹配时使用,最后调用spi_add_device ()将该SPI设备proxy添加到SPI设备链表中。
int spi_add_device(struct spi_device *spi)
{
static DEFINE_MUTEX(spi_add_lock);
struct device *dev = spi->master->dev.parent;
int status;
……
if (bus_find_device_by_name(&spi_bus_type, NULL, dev_name(&spi->dev))
!= NULL) {
dev_err(dev, "chipselect %d already in use\n",
spi->chip_select);
status = -EBUSY;
goto done;
}
……
status = spi->master->setup(spi);
……
/* Device may be bound to an active driver when this returns */
status = device_add(&spi->dev);
…….
}
函数spi_add_device ()进一步初始化SPI设备proxy,验证在spi_bus_type是否已存在该设备,如果没有则初始化该设备所在的spi控制器,最后使用device_add(&spi->dev)添加该SPI设备proxy到SPI设备链表中。
5.2 Tsc2005设备驱动注册
在driver/input/touchscreen/tsc2005.c中,定义了tsc2005的设备驱动,代码如下:static struct spi_driver tsc2005_driver = {
.driver = {
.name = "tsc2005",
.owner = THIS_MODULE,
},
#ifdef CONFIG_PM
.suspend = tsc2005_suspend,
.resume = tsc2005_resume,
#endif
.probe = tsc2005_probe,
.remove = __devexit_p(tsc2005_remove),
};
注册的简要示意图如下:
图5.3 tsc2005设备驱动的注册
相应的代码位于driver/input/touchscreen/tsc2005.c和driver/spi/spi.c。
static int __init tsc2005_init(void)
{
printk(KERN_INFO "TSC2005 driver initializing\n");
return spi_register_driver(&tsc2005_driver);
}
module_init(tsc2005_init);
在模块加载的时候首先调用tsc2005_init(),然后tsc2005_init()调用函数spi_register_driver()注册tsc2005_driver结构体。
int spi_register_driver(struct spi_driver *sdrv)
{
sdrv->driver.bus = &spi_bus_type;
if (sdrv->probe)
sdrv->driver.probe = spi_drv_probe;
if (sdrv->remove)
sdrv->driver.remove = spi_drv_remove;
if (sdrv->shutdown)
sdrv->driver.shutdown = spi_drv_shutdown;
return driver_register(&sdrv->driver);
}
函数spi_register_driver()初始化该驱动的总线为spi_bus_type,然后使用函数driver_register(&sdrv->driver)注册该驱动,因此内核会在SPI总线上遍历所有SPI设备,由于该tsc2005 设备驱动的匹配因子name变量为“tsc2005”,因此正好和在5.1.2里创建的chip->modalias为“tsc2005”的SPI 设备匹配。因此SPI设备驱动的probe函数tsc2005_probe()将会被调用,具体代码如下:
static int __devinit tsc2005_probe(struct spi_device *spi)
{
struct tsc2005 *tsc;
struct tsc2005_platform_data *pdata = spi->dev.platform_data;
int r;
……
tsc = kzalloc(sizeof(*tsc), GFP_KERNEL);
……
dev_set_drvdata(&spi->dev, tsc);
tsc->spi = spi;
spi->dev.power.power_state = PMSG_ON;
spi->mode = SPI_MODE_0;
spi->bits_per_word = 8;
……
spi_setup(spi);
r = tsc2005_ts_init(tsc, pdata);
……
}
在tsc2005_probe()函数中,完成一些具体tsc2005设备相关的初始化等操作,这边就不再详述。
6 用户空间的支持
和I2C一样,SPI也具有一个通用的设备的动程序,通过一个带有操作集file_operations的标准字符设备驱动为用户空间提供了访问接口。此驱动模型是针对SPI设备的,只有注册board info时modalias是”spidev”的才能由此驱动访问。访问各个slave的基本框架是一致的,具体的差异将由从设备号来体现,代码部分位于drivers/spi/spidev.c。
6.1 Spidev的注册
在drivers/spi/spidev.c中,首先定义了SPI设备驱动spidev_spi:static struct spi_driver spidev_spi = {
.driver = {
.name = "spidev",
.owner = THIS_MODULE,
},
.probe = spidev_probe,
.remove = __devexit_p(spidev_remove),
};
spidev_spi注册代码如下:
static int __init spidev_init(void)
{
int status;
……
status = register_chrdev(SPIDEV_MAJOR, "spi", &spidev_fops);
if (status < 0)
return status;
spidev_class = class_create(THIS_MODULE, "spidev");
……
status = spi_register_driver(&spidev_spi);
……
}
module_init(spidev_init);
首先注册了一个主设备号为SPIDEV_MAJOR,操作集为spidev_fops,名字为“spi”的字符设备。在文件drivers/spi/spidev.c中,SPI_MAJOR被定义为153。在spidev.c中spidev_fops的定义如下:
static struct file_operations spidev_fops = {
.owner = THIS_MODULE,
/* REVISIT switch to aio primitives, so that userspace
* gets more complete API coverage. It'll simplify things
* too, except for the locking.
*/
.write = spidev_write,
.read = spidev_read,
.unlocked_ioctl = spidev_ioctl,
.open = spidev_open,
.release = spidev_release,
};
该操作集是用户空间访问该字符设备的接口。然后调用函数spi_register_driver(&spidev_spi)将spidev_spi 驱动注册到SPI 核心层中,spidev_spi驱动注册过程中会扫描SPI总线上的所有SPI设备,一旦扫描到关键字modalias为”spidev”的SPI设备时,则与该SPI驱动匹配,匹配函数spidev_probe()被调用,具体的注册流程图如下:
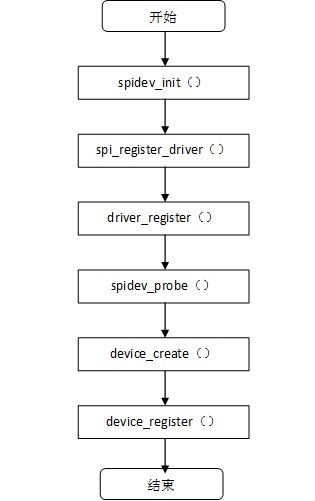
图5.1 SPIdev_driver注册过程
spidev_probe ()函数的代码如下:
static int spidev_probe(struct spi_device *spi)
{
struct spidev_data *spidev;
int status;
unsigned long minor;
/* Allocate driver data */
spidev = kzalloc(sizeof(*spidev), GFP_KERNEL);
if (!spidev)
return -ENOMEM;
/* Initialize the driver data */
spidev->spi = spi;
……
minor = find_first_zero_bit(minors, N_SPI_MINORS);
if (minor < N_SPI_MINORS) {
struct device *dev;
spidev->devt = MKDEV(SPIDEV_MAJOR, minor);
dev = device_create(spidev_class, &spi->dev, spidev->devt,
spidev, "spidev%d.%d",
spi->master->bus_num, spi->chip_select);
status = IS_ERR(dev) ? PTR_ERR(dev) : 0;
} else {
dev_dbg(&spi->dev, "no minor number available!\n");
status = -ENODEV;
}
if (status == 0) {
set_bit(minor, minors);
list_add(&spidev->device_entry, &device_list);
}
…….
}
在匹配函数spidev_probe()中,会首先为spidev_data结构体分配内存空间,该结构体定义如下:
struct spidev_data {
dev_t devt;
spinlock_t spi_lock;
struct spi_device *spi;
struct list_head device_entry;
/* buffer is NULL unless this device is open (users > 0) */
struct mutex buf_lock;
unsigned users;
u8 *buffer;
};
结构体中包含了spi_device结构体,device_entry链表头等成员变量。分配完spidev_data结构体后对其进行初始化,然后创建spi设备,成功后将该spidev_data添加到device_list链表中,该链表维护这些modalias为”spidev”的SPI设备。device_list链表定义在spidev.c中如下:
static LIST_HEAD(device_list);
这些SPI设备以SPIDEV_MAJOR为主设备号,以函数find_first_zero_bit()的返回值为从设备号创建并注册设备节点。如果系统有udev或者是hotplug,那么就会在/dev下自动创建相关的设备节点了,其名称命名方式为spidevB.C,B为总线编号,C为片选序号。
6.2 Spidev的打开
Spidev的open函数如下:static int spidev_open(struct inode *inode, struct file *filp)
{
struct spidev_data *spidev;
int status = -ENXIO;
lock_kernel();
mutex_lock(&device_list_lock);
list_for_each_entry(spidev, &device_list, device_entry) {
if (spidev->devt == inode->i_rdev) {
status = 0;
break;
}
}
if (status == 0) {
if (!spidev->buffer) {
spidev->buffer = kmalloc(bufsiz, GFP_KERNEL);
if (!spidev->buffer) {
dev_dbg(&spidev->spi->dev, "open/ENOMEM\n");
status = -ENOMEM;
}
}
if (status == 0) {
spidev->users++;
filp->private_data = spidev;
nonseekable_open(inode, filp);
}
} else
pr_debug("spidev: nothing for minor %d\n", iminor(inode));
mutex_unlock(&device_list_lock);
unlock_kernel();
return status;
}
Open操作是用户空间程序和内核驱动交互的第一步,首先会遍历device_list链表,然后根据设备节点号进行匹配查找对应的spidev_data节点从而找到相应的从设备,然后给spidev分配buffer空间,最后filp的private_data被赋值为spidev,而最终返回给用户空间的就是这个struct file结构体。对于SPI 驱动来说,用户空间所获得的就是spidev这个关键信息,在其中可以找到所有有关的信息如spidev的SPI设备。用open函数将spidev设备打开以后,就可以通过ioctl函数的各种命令来对modalias为”spidev”的SPI设备进行读写等操作,也可以通过 read和write函数完成对SPI设备的读写。
对SPI设备的具体操作在这里不再具体阐述,可以参看spidev.c源代码。
7 SPI数据收发
第二章的时候的时候已经讲到过,SPI的通信是通过消息队列机制也就是workqueue,核心思想就是要构造一个spi_message。7.1 SPI数据收发数据结构
SPI数据收发用到的结构体主要有两个,spi_message和spi_transfer,两者都定义在include/linux/spi/spi.h中。spi_message定义如下:
/** * struct spi_message - one multi-segment SPI transaction * @transfers: list of transfer segments in this transaction * @spi: SPI device to which the transaction is queued * @is_dma_mapped: if true, the caller provided both dma and cpu virtual * addresses for each transfer buffer * @complete: called to report transaction completions * @context: the argument to complete() when it's called * @actual_length: the total number of bytes that were transferred in all * successful segments * @status: zero for success, else negative errno * @queue: for use by whichever driver currently owns the message * @state: for use by whichever driver currently owns the message * * A @spi_message is used to execute an atomic sequence of data transfers, * each represented by a struct spi_transfer. The sequence is "atomic" * in the sense that no other spi_message may use that SPI bus until that * sequence completes. On some systems, many such sequences can execute as * as single programmed DMA transfer. On all systems, these messages are * queued, and might complete after transactions to other devices. Messages * sent to a given spi_device are alway executed in FIFO order. * * The code that submits an spi_message (and its spi_transfers) * to the lower layers is responsible for managing its memory. * Zero-initialize every field you don't set up explicitly, to * insulate against future API updates. After you submit a message * and its transfers, ignore them until its completion callback. */ struct spi_message { struct list_head transfers; struct spi_device *spi; unsigned is_dma_mapped:1; /* REVISIT: we might want a flag affecting the behavior of the * last transfer ... allowing things like "read 16 bit length L" * immediately followed by "read L bytes". Basically imposing * a specific message scheduling algorithm. * * Some controller drivers (message-at-a-time queue processing) * could provide that as their default scheduling algorithm. But * others (with multi-message pipelines) could need a flag to * tell them about such special cases. */ /* completion is reported through a callback */ void (*complete)(void *context); void *context; unsigned actual_length; int status; /* for optional use by whatever driver currently owns the * spi_message ... between calls to spi_async and then later * complete(), that's the spi_master controller driver. */ struct list_head queue; void *state; };spi_message 包含了一系列spi_transfer,在所有的spi_transfer发送完毕前,SPI总线一直被占据,其间不会出现总线冲突,因此一个spi_message是一个原子系列,这种特性非常利于复杂的SPI通信协议,如先发送命令字然后才能读取数据。所有的spi_message都按照FIFO顺序执行。
还定义了需要发送的SPI设备,上下文信息context和传输完成后需要的回调函数complete等。
spi_transfer结构体的定义如下:
/** * struct spi_transfer - a read/write buffer pair * @tx_buf: data to be written (dma-safe memory), or NULL * @rx_buf: data to be read (dma-safe memory), or NULL * @tx_dma: DMA address of tx_buf, if @spi_message.is_dma_mapped * @rx_dma: DMA address of rx_buf, if @spi_message.is_dma_mapped * @len: size of rx and tx buffers (in bytes) * @speed_hz: Select a speed other than the device default for this * transfer. If 0 the default (from @spi_device) is used. * @bits_per_word: select a bits_per_word other than the device default * for this transfer. If 0 the default (from @spi_device) is used. * @cs_change: affects chipselect after this transfer completes * @delay_usecs: microseconds to delay after this transfer before * (optionally) changing the chipselect status, then starting * the next transfer or completing this @spi_message. * @transfer_list: transfers are sequenced through @spi_message.transfers * * SPI transfers always write the same number of bytes as they read. * Protocol drivers should always provide @rx_buf and/or @tx_buf. * In some cases, they may also want to provide DMA addresses for * the data being transferred; that may reduce overhead, when the * underlying driver uses dma. * * If the transmit buffer is null, zeroes will be shifted out * while filling @rx_buf. If the receive buffer is null, the data * shifted in will be discarded. Only "len" bytes shift out (or in). * It's an error to try to shift out a partial word. (For example, by * shifting out three bytes with word size of sixteen or twenty bits; * the former uses two bytes per word, the latter uses four bytes.) * * In-memory data values are always in native CPU byte order, translated * from the wire byte order (big-endian except with SPI_LSB_FIRST). So * for example when bits_per_word is sixteen, buffers are 2N bytes long * (@len = 2N) and hold N sixteen bit words in CPU byte order. * * When the word size of the SPI transfer is not a power-of-two multiple * of eight bits, those in-memory words include extra bits. In-memory * words are always seen by protocol drivers as right-justified, so the * undefined (rx) or unused (tx) bits are always the most significant bits. * * All SPI transfers start with the relevant chipselect active. Normally * it stays selected until after the last transfer in a message. Drivers * can affect the chipselect signal using cs_change. * * (i) If the transfer isn't the last one in the message, this flag is * used to make the chipselect briefly go inactive in the middle of the * message. Toggling chipselect in this way may be needed to terminate * a chip command, letting a single spi_message perform all of group of * chip transactions together. * * (ii) When the transfer is the last one in the message, the chip may * stay selected until the next transfer. On multi-device SPI busses * with nothing blocking messages going to other devices, this is just * a performance hint; starting a message to another device deselects * this one. But in other cases, this can be used to ensure correctness. * Some devices need protocol transactions to be built from a series of * spi_message submissions, where the content of one message is determined * by the results of previous messages and where the whole transaction * ends when the chipselect goes intactive. * * The code that submits an spi_message (and its spi_transfers) * to the lower layers is responsible for managing its memory. * Zero-initialize every field you don't set up explicitly, to * insulate against future API updates. After you submit a message * and its transfers, ignore them until its completion callback. */ struct spi_transfer { /* it's ok if tx_buf == rx_buf (right?) * for MicroWire, one buffer must be null * buffers must work with dma_*map_single() calls, unless * spi_message.is_dma_mapped reports a pre-existing mapping */ const void *tx_buf; void *rx_buf; unsigned len; dma_addr_t tx_dma; dma_addr_t rx_dma; unsigned cs_change:1; u8 bits_per_word; u16 delay_usecs; u32 speed_hz; struct list_head transfer_list; };一个spi_transfer是以某种特性如速率、延时及字长连续传输的最小单位。因为SPI是全双工总线,只要总线上有数据传输,则MOSI和MISO上同时有数据采样,对于SPI 控制器来说,其收发缓冲区中都有数据,但是对于SPI设备来说,其可以灵活的选择tx_buf和rx_buf的设置。当发送数据时,tx_buf必须设置为待发送的数据,rx_buf可以为null或者指向无用的缓冲区,即不关心MISO的数据。而当接收数据时,rx_buf必须指向接收缓冲区,而tx_buf可以为Null,则MOSI上为全0,或者tx_buf指向不会引起从设备异常相应的数据,len为待发送或者接收的数据长度,当然当采用DMAf方式传输时,必须初始化相应的DMA地址。当一系列spi_transfer构成一个spi_message时,cs_change的设置非常讲究。当cs_change为0即不变时,则可以连续对同一个设备进行数据收发;当cs_change为1时通常用来停止command的传输而随后进行数据接收。因此cs_change可以利用SPI总线构造复杂的通信协议。
对于SPI总线协议来说,传输单位可以是4-32之间的任意bits,但对于SPI控制器来说,bits_per_word只能是8/16/32,即需要取整,待收发的数据在内存里都是以主机字节序右对齐存储,SPI控制器会自动根据传输单位及大小端进行转换。
7.2 SPI数据收发的函数
SPI数据收发的函数主要有spi_async()和spi_sync()。函数spi_async()定义在include/linux/spi/spi.h中,
/** * spi_async - asynchronous SPI transfer * @spi: device with which data will be exchanged * @message: describes the data transfers, including completion callback * Context: any (irqs may be blocked, etc) * * This call may be used in_irq and other contexts which can't sleep, * as well as from task contexts which can sleep. * * The completion callback is invoked in a context which can't sleep. * Before that invocation, the value of message->status is undefined. * When the callback is issued, message->status holds either zero (to * indicate complete success) or a negative error code. After that * callback returns, the driver which issued the transfer request may * deallocate the associated memory; it's no longer in use by any SPI * core or controller driver code. * * Note that although all messages to a spi_device are handled in * FIFO order, messages may go to different devices in other orders. * Some device might be higher priority, or have various "hard" access * time requirements, for example. * * On detection of any fault during the transfer, processing of * the entire message is aborted, and the device is deselected. * Until returning from the associated message completion callback, * no other spi_message queued to that device will be processed. * (This rule applies equally to all the synchronous transfer calls, * which are wrappers around this core asynchronous primitive.) */ static inline int spi_async(struct spi_device *spi, struct spi_message *message) { message->spi = spi; return spi->master->transfer(spi, message); }
该函数是异步的SPI传输函数,可以用于在中端或者某些不能睡眠的上下文场合,当然也可以用于睡眠的场合。
对于发送给同一个SPI设备的message遵循FIFO的顺序,发送给不同的SPI设备的message可以有不同的顺序。
直到从回调函数返回之前,都不能处理该设备的其他spi_message。从源代码可以看到,该函数最后调用了发送给相应设备的相应控制器的transfer函数。
spi_sync()函数定义在driver/spi/spi.c中,
/** * spi_sync - blocking/synchronous SPI data transfers * @spi: device with which data will be exchanged * @message: describes the data transfers * Context: can sleep * * This call may only be used from a context that may sleep. The sleep * is non-interruptible, and has no timeout. Low-overhead controller * drivers may DMA directly into and out of the message buffers. * * Note that the SPI device's chip select is active during the message, * and then is normally disabled between messages. Drivers for some * frequently-used devices may want to minimize costs of selecting a chip, * by leaving it selected in anticipation that the next message will go * to the same chip. (That may increase power usage.) * * Also, the caller is guaranteeing that the memory associated with the * message will not be freed before this call returns. * * It returns zero on success, else a negative error code. */ int spi_sync(struct spi_device *spi, struct spi_message *message) { DECLARE_COMPLETION_ONSTACK(done); int status; message->complete = spi_complete; message->context = &done; status = spi_async(spi, message); if (status == 0) { wait_for_completion(&done); status = message->status; } message->context = NULL; return status; }该函数是同步的SPI传输函数,只能用于可以睡眠的场合。
7.3 SPI数据传输example
下面是tsc2005进行SPI数据传输的例子,static void tsc2005_write(struct tsc2005 *ts, u8 reg, u16 value) { u32 tx; struct spi_message msg; struct spi_transfer xfer = { 0 }; tx = (TSC2005_REG | reg | TSC2005_REG_PND0 | TSC2005_REG_WRITE) << 16; tx |= value; xfer.tx_buf = &tx; xfer.rx_buf = NULL; xfer.len = 4; xfer.bits_per_word = 24; spi_message_init(&msg); spi_message_add_tail(&xfer, &msg); spi_sync(ts->spi, &msg); }该函数首先定义SPI 传输所需的spi_message和spi_transfer数据结构,初始化他们,然后将spi_transfer添加到spi_message的transfer_list链表中,最后调用spi_sync()将SPI数据发送出去。
8 鸣谢
http://blog.csdn.net/sailor_8318/article/details/5977733
http://blog.csdn.net/kellycan/article/details/6415228