一个线程池引发的悲剧
在对 Jetty 性能测试 AJP 静态页面发现,压力一上来 LR 端就出现 504 错误,查看 nginx 的 logs 发现 大量请求 upstream timeout ,意思是说在 nginx 上来的请求在 jetty 接收时出现问题。使用 netstat –ano|grep 8009 发现个有意思的东西如下图:
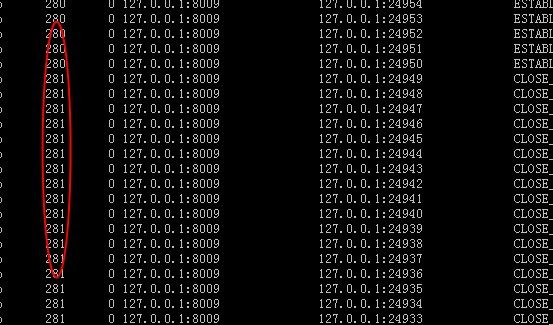
Recv-Q 接收队列大量数据等待copy,可以看到每个连接都有 281 个字节在等待,正常状况这个 Recv-Q 应该是 0 ,并且大量服务器连接处于被动关闭状态 CLOSE_WAIT.
这里就有两个问题:
1、 为什么服务器连接被 nginx 主动给干掉了?
2、 为什么 jetty 后端处理会有这么多等待队列?
顺着这两个问题,之前怀疑是 nginx 有什么问题,结果查了半天没查出来,再看这里 ESTABLISHED 只有 10 个,而且非常固定,而 CLOSE_WAIT 连接却在不断增多。
接下来 /opt/java1/bin/jstack 15679|grep ‘poo-’ –c 看了下线程数,恰好只有 10 个线程,恰好是我设置的线程池最小线程数量,按道理压力这么大的情况下,这里的线程数应该大于 10 才对,于是猜测会不会是线程池问题 ( 没其他办法了,完全是乱猜 ) ?
一看配置:
<Set name="ThreadPool"> <!-- Default queued blocking threadpool --> <New class="org.eclipse.jetty.util.thread. ExecutorThreadPool"> <Arg>10</ Arg > <!--core线程数--> <Arg>200</ Arg ><!—最大线程数--> <Arg>60000</ Arg ><!--keeplive--> </New> </Set>
貌似没什么问题,不过看看 org.eclipse.jetty.util.thread. ExecutorThreadPool 的源代码:
上面代码其实是调用下面这个构造函数:
public ExecutorThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime) { this(new ThreadPoolExecutor(corePoolSize,maximumPoolSize,keepAliveTime,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>())); }
这是使用的 JDK 的自带线程池 ThreadPoolExecutor ,特别注意最后一个参数 new LinkedBlockingQueue<Runnable>() ,这是放任务的队列,而且是一个无边界的队列。为什么要强调这个,请见其最终代码实现,或者看下 JDK 的描述:
无界队列。 使用无界队列(例如,不具有预定义容量的 LinkedBlockingQueue )将导致在所有 corePoolSize 线程都忙时新任务在队列中等待。这样,创建的线程就不会超过 corePoolSize 。(因此, maximumPoolSize 的值也就无效了。)当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web 页服务器中。这种排队可用于处理瞬态突发请求,当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
就是说这个队列可以放无穷多的任务 ( 只要内存足够大 ) ,只要能放进去任务,那么线程数最多就是我们设置的 corePoolSize, 我们前面设置的是 10 ,这就能解释为什么前面我们的线程数不能超过 10 了,虽然很多任务在等待执行。
于是,我将该线程池重新做了一下设置,服务器恢复正常。
那么 nginx 为什么会主动关闭连接?答案很简单, socket 本身只能接收一定数量的连接请求数据,如果数据没有被处理掉,那么upstream 就不能继续发送,一直等到超时为止,也就是前面出现upstream timeout ,然后nginx关闭了这个连接,因此会出现一大堆的 CLOSE_WAIT 。
-----------