搜索引擎技术介绍
引言
早些时候分享过一份关于搜索引擎技术的PPT,这篇文章基本上是基于原来框架,在内容上做了一些改进和扩充。
主要是对搜索引擎技术的各方面做一些简单的介绍和入门的指引。
索引
1. 需求与历史
2. 搜索产品简介
3. 搜索技术
3.1 系统
3.2 数据
3.3 算法
4. 开源方案
5. 现状与未来
需求与历史
搜索引擎的诞生源自互联网最根本的用途之一:信息获取。在搜索引擎出现之前,互联网缺少入口,用户往往需要自己记住有用的网站和网页。
为了满足这种需求,最早的“搜索引擎”,即分类目录浏览式的引擎便出现了,Yahoo就是其中的代表。
当时只是把一些有用的网站通过分类的方式手工组织起来,便于用户找到有用的信息。
能够手工组织也是基于早年整个互联网的网站数量也非常少,可以通过人工方式实现组织。
但随着互联网的壮大,网页网站数量越来越多,手工组织的方式变为不可行,于是由机器实现的全文检索引擎便出现了。
用户可以通过关键字查询来获取相关的网页。
但随着网页数量进一步增多,任何关键字查询都会返回大量的相关网页,如果对网页进行评分和排序,返回给用户真正有价值的网页便成为重点。
基于网页之间的链接关系为网页进行评分,成为很多搜索引擎的网页排序算法基础,Google的PageRank算法便是其中的代表者和姣姣者。
Google也以此为基础成为搜索引擎产品中的领先者,为用户提供了更好的搜索结果相关性。
现代搜索引擎基本上也由此基本成型,虽然后来的技术创新和改进很多,但主要的思路基本上没有变。
搜索引擎发展到今天,基础架构和算法在技术上都已经基本成型和成熟。如今的一些改进和变化基于在多元化的信息整合,以及产品形态的改进上。
未来会往什么方向发展,或者有什么革命的变化,都不能确定。
搜索产品
搜索引擎产品其实包括很多种类,并不限于我们最熟悉的全网搜索引擎。
简单分类罗列一下:
* 全网搜索:包括市场份额最高的几大搜索引擎巨头,Google, Yahoo, Bing。
* 中文搜索:在中文搜索市场中,百度一家独大,其它几家如搜狗、搜搜、有道,市场份额相对还比较小。
* 垂直搜索:在各自的垂直领域成为搜索入口的,购物的淘宝,美食的大众点评,旅游的去哪儿,等等。
* 问答搜索:专注于为问句式提供有效的答案,比如Ask.com;其它的如问答社区像Quora和国内的知乎,应该也会往这方面发展。
* 知识搜索:典型代表就是WolframAlpha,区别于提供搜索结果列表,它会针对查询提供更详细的整合信息。
* 云搜索平台:为其它产品和应用提供搜索服务托管平台(SaaS或是PaaS),Amazon刚刚推出它的CloudSearch, IndexTank在被Linkedin收购之前也是做这项服务。
* 其它:比始DuckDuckGo,主打隐私保护,也有部分用户买帐。
各种搜索产品在各自领域都需要解决特定的技术和业务问题,所以也可以建立相对通用搜索的优势,来得到自己的市场和用户。
搜索技术
搜索引擎所涉及和涵盖的技术范围非常广,涉及到了系统架构和算法设计等许多方面。
可以说由于搜索引擎的出现,把互联网产品的技术水平提高到了一个新的高度;搜索引擎无论是在数据和系统规模,还是算法技术的研究应用深度上,都远超之前的简单互联网产品。
列举一些搜索引擎所涉及到的技术点:
* 爬虫 (Crawling)
* 索引结构 (Inverted Index)
* 检索模型 (VSM & TF-IDF)
* 搜索排序 (Relevance Ranking & Evaluation)
* 链接分析 (Link Analysis)
* 分类 (Document & Query Classification)
* 自然语言处理 (NLP: Tokenization, Lemmatization, POS Tagging, NER, etc.)
* 分布式系统 (Distributed Processing & Storage)
* 等等
虽然搜索引擎涉及的技术方方面面,但归结起来最关键的几点在于:
* 系统:大规模分布式系统,支撑大规模的数据处理容量和在线查询负载
* 数据:数据处理和挖掘能力
* 算法:搜索相关性排序,查询分析,分类,等等
系统
搜索引擎系统是一个由许多模块组成的复杂系统。
核心模块通常包括:爬虫,索引,检索,排序。
除了必需的核心模块之外,通常还需要一些支持辅助模块,常见的有链接分析,去重,反垃圾,查询分析,等等。
[附图:搜索系统架构概念模型]
简单介绍一下搜索系统的概念模型中的各模块:
* 爬虫
从互联网爬取原始网页数据,存储于文档服务器。
* 文档服务器
存储原始网页数据,通宵是分布式Key-Value数据库,能根据URL/UID快速获取网页内容。
* 索引
读取原始网页数据,解析网页,抽取有效字段,生成索引数据。
索引数据的生成方式通常是增量的,分块/分片的,并会进行索引合并、优化和删除。
生成的索引数据通常包括:字典数据,倒排表,正排表,文档属性等。
生成的索引存储于索引服务器。
* 索引服务器
存储索引数据,主要是倒排表。
通常是分块、分片存储,并支持增量更新和删除。
数据内容量非常大时,还根据类别、主题、时间、网页质量划分数据分区和分布,更好地服务在线查询。
* 检索
读取倒排表索引,响应前端查询请求,返回相关文档列表数据。
* 排序
对检索器返回的文档列表进行排序,基于文档和查询的相关性、文档的链接权重等属性。
* 链接分析
收集各网页的链接数据和锚文本(Anchor Text),以此计算各网页链接评分,最终会作为网页属性参与返回结果排序。
* 去重
提取各网页的相关特征属性,计算相似网页组,提供离线索引和在线查询的去重服务。
* 反垃圾
收集各网页和网站历史信息,提取垃圾网页特征,从而对在线索引中的网页进行判定,去除垃圾网页。
* 查询分析
分析用户查询,生成结构化查询请求,指派到相应的类别、主题数据服务器进行查询。
* 页面描述/摘要
为检索和排序完成的网页列表提供相应的描述和摘要。
* 前端
接受用户请求,分发至相应服务器,返回查询结果。
[附图:爬虫系统架构]
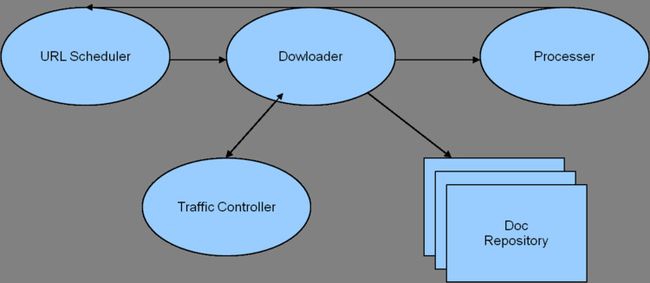
爬虫系统也是由多个模块构成:
* URL Scheduler
存储和高度待爬取的网页地址。
* Downloader
根据指定的网页列表爬取网页内容,存储至文档服务器。
* Processer
对网页内容进行简单处理,提取一些原始属性,为爬取的后续操作服务。
* Traffic Controller
爬取流量控制,防止对目标网站在短时间内造成过大负载。
[附图:搜索系统架构实例:Google]
这是Google早期的一张系统架构图,可以看出Google系统的各模块基本和前面概念模型一致。
所以一个完整的全网搜索系统的大致系统架构是类似的,区别和竞争力体现在细节实现和优化上。
数据
除了搜索引擎系统提供了系统支撑外,搜索结果质量很大程度上依赖于源数据的数量和质量,以及数据处理的能力。
全网数据的主要来源通常是从互联网上进行自动爬取,从一些高质量的种子站点开始,并沿网页链接不断展开,收集巨量的网页数据;这通常能达到数据在数量的要求,但也不可避免混入了大量的低质量网页。
除了自动爬取来的数据外,搜索引擎的数据来源还可以来自人工收集、合作伙伴提供、第三方数据源和API、以及购买;这些来源通常会有更好的质量保证,但在数量规模和覆盖率上会相对少一些,可以和爬取的数据形成有效的互补。
收集到足量的原始数据后,需要进行各种数据处理操作,把原始数据转换成在线检索需要的数据。
这个过程通常包括:网页分析,数据抽取,文本处理和分词,索引及合并;最终生成的数据会包括:词典,倒排表,正排表,文档权重和各种属性。
最终生成的数据要布署上相应的在线检索服务器上,通常会进行数据分区和分片布署,数据内容更丰富时还可能根据内容分类和主题进行分别布署,比如新闻时效类的网页可能就会独立布署,针对性地响应时效类的查询。
[附图:索引数据:字典、倒排表、正排表]
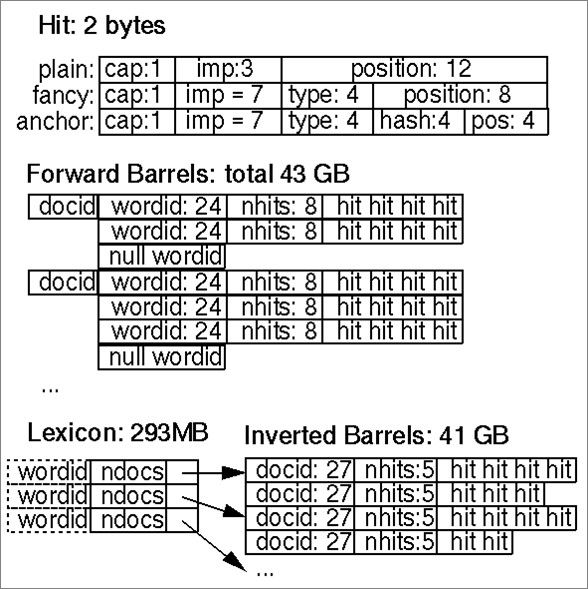
这张图来源于Google早期的索引数据结构,包括词典、倒排表、正排表。
算法
有了相当数量的高质量数据之后,搜索结果的质量改进就取决于搜索算法的准确性上。
现在的搜索引擎通常通过向量空间模型(VSM = Vector Space Model)来计算查询和各文档之间的文本相似性;即把查询或文档抽象成一个词向量,然后再计算向量在向量空间中的夹角,可以用余弦公式得出,作为文本相似度的度量值。
在 基本的向量空间模型基础上通常会进一步加入词的权重值进行改进,通过经典的TF-IDF公式得出,即词频(TF)乘上逆文档频率(IDF);其中TF = Term Frequency,即该词在所在文档中的出现次数;IDF = Invert Document Frequency,即包含该词的文档数除以总文档数,再取反,通常还会取对数来降维,这个值值越大表示这个词越能代表文档特征。
除了通过向量空间模型得出的文本匹配评分外,每个文档还会有自己本身的质量评分,通常由网页链接数据计算得出,代表了该网页本身的流行度权重。
最终的评分会以文本匹配的查询时动态评分和文档静态评分为基础计算得出;搜索引擎的评分计算都会考虑很多因素,但这两项通常是评分计算的基础。
有了确定的排序算法后,另一个重要的任务就是评估搜索结果的质量。
由于搜索结果的好与坏是一个比较主观的过程,所以进行定量的评估并不容易。
常见的做法是通过事先选定一批查询,通过人工评估或是预先设定标准值的方式,逐个评估每个设定查询搜索结果,最终得到一个统计结果,作为搜索算法的评估度量。
另一类做法是直接通过线上的用户点击数据来统计评估搜索结果质量,或是通过A/B测试来比较两种排序算法的点击效果来衡量。
合理而有效的评估方法,是搜索算法可以不断改进和比较的前提。
查询分析是另一个对搜索结果影响很大的方面,主要任务是把用户的查询文本转换成内部的结构化的搜索请求。
涉及的处理可能包括基本的分词处理,专有名词的识别和提取,或是查询模式的识别,或是查询分类的识别。
这些处理的准确性将能极大地改进搜索请求的方式,进一步影响搜索结果的相关性和质量。
开源方案
近年来在搜索公司内部搜索系统和技术的改进和发展的同时,一批开源的搜索系统和解决方案也逐渐发展和成熟起来。
当然开源系统在功能全面性、复杂性和规模上都不能与专业的搜索引擎系统相比,但对于中小企业的搜索应用来说应该已经能很好地满足需求,而且也成功应用到了一些大规模的产品系统中(比如Twitter的搜索就使用和改进了Lucene)。
现在比较常见的开源搜索解决方案有:
* Lucene
Lucene自然是现在最流行,使用度最高的搜索开源方案。它用Java开发,以索引和检索库的方式提供,可以很容易地嵌入需要的应用中。
* Solr & SolrCloud
Solr是Lucene的子项目,同属Apache软件基金会项目;它是基于Lucene之上实的一个完整的搜索服务应用,提供了大量的搜索定制功能,可以满足大部分的搜索产品需求。
SolrCloud是Solr为了加强其分布式服务能力而开发的功能,目前还在开发阶段,将在Solr 4.0发布。
* Zoie & Sensei (Linkedin)
Zoie是Linkedin公司在Lucene基础上实现的准实时索引库,通过加入额外的内存索引,来达到准实时索引的效果。
Sensei是Linkedin公司在Zoie基础上实现的分布式搜索服务,通过索引分区来实现分布式搜索服务。
* ElasticSearch
ElasticSearch 也是刚推出不久的一个基于Lucene实现的分布式搜索服务,据说在分布式支持和易用性上都有不错的表现。因为还比较年轻,真实的应用应该还不多,需要观 察。因为也是基于Lucene的分布式开源搜索框架,基本上会与SolrCloud和Sensei形成正面竞争关系。
* 其它开源产品
除了Lucene家族以外,还有一些其它的开源产品,比如Sphinx和Xapian,也有不少的应用;但近年来的更新频率和社区活跃度都不太能和Lucene系的产品相比。
* 托管平台
除 了开源产品外,现在还出现了一些基于云计算和云服务的搜索服务,比如Amazon新近推了的CloudSearch,还有更早一些的 IndexTank(已被Linkedin收购)。这类服务无需自己布置搜索系统,直接使用在线服务,按需付费,所以也将是开源产品的替代方案和竞争对 手。
附几张上面提到的开源系统的概念模型和架构图:
[附图:Lucene概念模型]
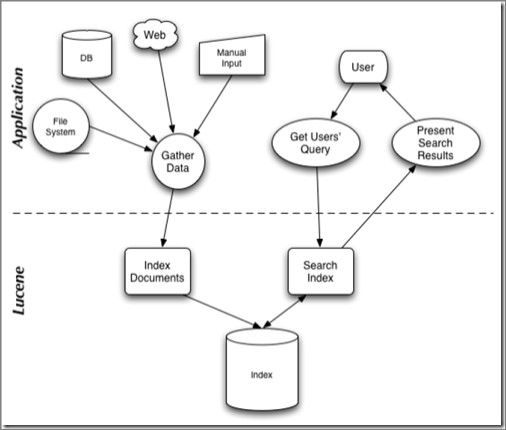
[附图:Lucene工作流程]

[附图:Sensei系统架构]

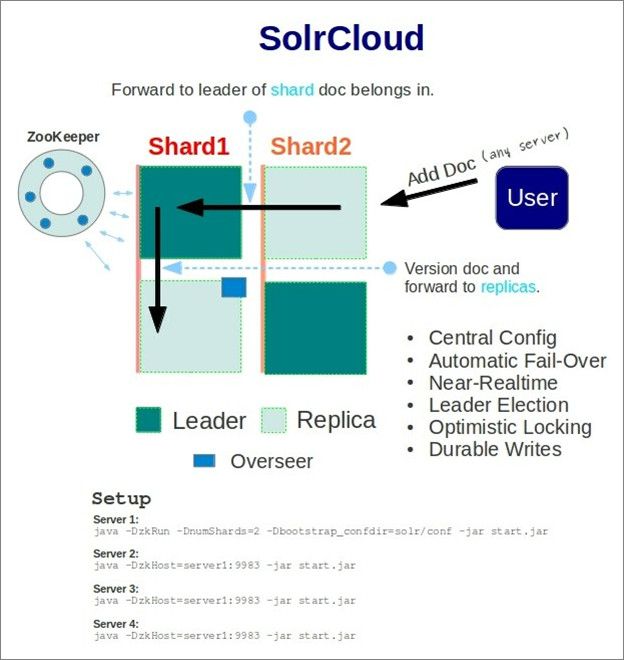
[附图:SolrCloud系统架构]
现状与未来
传统的搜索引擎经过了十几年的发展,目前在技术和产品上都已走向逐渐稳定和成熟,通用搜索的市场也基本进入饱和,不像早些年一直呈现高增长率。
同时,在各个垂直领域,也出现了很多和产品结合的很好的垂直搜索产品,比如淘宝的购物搜索,大众点评的美食搜索,去哪儿和酷讯的旅游搜索等,也都在各自领域占据了相当大的市场,成为除了通用搜索引擎之外的重要的用户入口。
在开源领域,各种开源产品和解决方案也逐渐发展成熟,通用搜索技术不再为大公司所专有,中小企业能够以较低的成本实现自己的搜索应用。
现在搜索引擎产品之间的竞争更多的在数据、应用方式和产品形态上,在系统架构和基本算法上区分并不大。
搜索引擎在未来发展上,一是搜索将不仅仅以独立产品的形式出现,更多的会作为搜索功能整合到更多的产品和应用中。
在产品形态上,基于传统的搜索引擎,会演化出像推荐引擎,知识引擎,决策引擎等形式的产品,更好地满足和服务用户需求。
而搜索引擎所涉及和发展起来的各种技术,会更广泛地应用到各种基它产品上,比如自然语言处理,推荐和广告,数据挖掘,等等。
总之,搜索引擎对互联网技术和产品带来的影响是巨大的,未来也仍将有很大的发展和应用空间。
转自: 网易杭研后台技术中心的博客 http://backend.blog.163.com/blog/static/202294126201252872124208/