Introduction to Oozie
Tasks performed in Hadoop sometimes require multiple Map/Reduce jobs to be chained together to complete its goal. [1] Within the Hadoop ecosystem, there is a relatively new component Oozie [2], which allows one to combine multiple Map/Reduce jobs into a logical unit of work, accomplishing the larger task. In this article we will introduce Oozie and some of the ways it can be used.
What is Oozie ?
Oozie is a Java Web-Application that runs in a Java servlet-container - Tomcat and uses a database to store:
- Workflow definitions
- Currently running workflow instances, including instance states and variables
Oozie workflow is a collection of actions (i.e. Hadoop Map/Reduce jobs, Pig jobs) arranged in a control dependency DAG (Direct Acyclic Graph), specifying a sequence of actions execution. This graph is specified in hPDL (a XML Process Definition Language).

hPDL is a fairly compact language, using a limited amount of flow control and action nodes. Control nodes define the flow of execution and include beginning and end of a workflow (start, end and fail nodes) and mechanisms to control the workflow execution path ( decision, fork and join nodes). Action nodes are the mechanism by which a workflow triggers the execution of a computation/processing task. Oozie provides support for the following types of actions: Hadoop map-reduce, Hadoop file system, Pig, Java and Oozie sub-workflow (SSH action is removed as of Oozie schema 0.2).
All computation/processing tasks triggered by an action node are remote to Oozie - they are executed by Hadoop Map/Reduce framework. This approach allows Oozie to leverage existing Hadoop machinery for load balancing, fail over, etc. The majority of these tasks are executed asynchronously (the exception is the file system action that is handled synchronously). This means that for most types of computation/processing tasks triggered by workflow action, the workflow job has to wait until the computation/processing task completes before transitioning to the following node in the workflow. Oozie can detect completion of computation/processing tasks by two different means, callbacks and polling. When a computation/processing tasks is started by Oozie, Oozie provides a unique callback URL to the task, the task should invoke the given URL to notify its completion. For cases that the task failed to invoke the callback URL for any reason (i.e. a transient network failure) or when the type of task cannot invoke the callback URL upon completion, Oozie has a mechanism to poll computation/processing tasks for completion.
Oozie workflows can be parameterized (using variables like ${inputDir} within the workflow definition). When submitting a workflow job values for the parameters must be provided. If properly parameterized (i.e. using different output directories) several identical workflow jobs can concurrently.
Some of the workflows are invoked on demand, but the majority of times it is necessary to run them based on regular time intervals and/or data availability and/or external events. The Oozie Coordinator system allows the user to define workflow execution schedules based on these parameters. Oozie coordinator allows to model workflow execution triggers in the form of the predicates, which can reference to data, time and/or external events. The workflow job is started after the predicate is satisfied.
It is also often necessary to connect workflow jobs that run regularly, but at different time intervals. The outputs of multiple subsequent runs of a workflow become the input to the next workflow. Chaining together these workflows result it is referred as a data application pipeline. Oozie coordinator support creation of such data Application pipelines.
Installing Oozie
Oozie can be installed, on existing Hadoop system, either from a tarball , RPM or Debian Package. Our Hadoop installation is Cloudera’s CDH3, which already contains Oozie. As a result, we just used yum to pull it down and perform the installation on an edge node[1].There are two components in Oozie distribution - Oozie-client and Oozie-server. Depending on the size of your cluster, you may have both components on the same edge server or on separate machines. The Oozie server contains the components for launching and controlling jobs, while the client contains the components for a person to be able to launch Oozie jobs and communicate with the Oozie server.
For more information on the installation process please using Cloudera distribution, visit the Cloudera website[2]
Note: In addition to the installation process, its recommended to add the shell variable OOZIE_URL
(export OOZIE_URL=http://localhost:11000/oozie)
to your .login, .kshrc, or the shell startup file of your choice.
A Simple Example
To show Oozie usage let us turn to a simple example. We have two Map/Reduce jobs[3] - one that is doing initial ingestion of the data and the second one merging data of the given type. The actual ingestion needs to execute initial ingestion and then merge data for two of the types - Lidar and Multicam. To automate this process we have created a simple Oozie Workflow (Listing 1)
<!-- Copyright (c) 2011 NAVTEQ! Inc. All rights reserved. NGMB IPS ingestor Oozie Script --> <workflow-app xmlns='uri:oozie:workflow:0.1' name='NGMB-IPS-ingestion'> <start to='ingestor'/> <action name='ingestor'> <java> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>default</value> </property> </configuration> <main-class>com.navteq.assetmgmt.MapReduce.ips.IPSLoader</main-class> <java-opts>-Xmx2048m</java-opts> <arg>${driveID}</arg> </java> <ok to="merging"/> <error to="fail"/> </action> <fork name="merging"> <path start="mergeLidar"/> <path start="mergeSignage"/> </fork> <action name='mergeLidar'> <java> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>default</value> </property> </configuration> <main-class>com.navteq.assetmgmt.hdfs.merge.MergerLoader</main-class> <java-opts>-Xmx2048m</java-opts> <arg>-drive</arg> <arg>${driveID}</arg> <arg>-type</arg> <arg>Lidar</arg> <arg>-chunk</arg> <arg>${lidarChunk}</arg> </java> <ok to="completed"/> <error to="fail"/> </action> <action name='mergeSignage'> <java> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>default</value> </property> </configuration> <main-class>com.navteq.assetmgmt.hdfs.merge.MergerLoader</main-class> <java-opts>-Xmx2048m</java-opts> <arg>-drive</arg> <arg>${driveID}</arg> <arg>-type</arg> <arg>MultiCam</arg> <arg>-chunk</arg> <arg>${signageChunk}</arg> </java> <ok to="completed"/> <error to="fail"/> </action> <join name="completed" to="end"/> <kill name="fail"> <message>Java failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message> </kill> <end name='end'/> </workflow-app>
Listing 1: Simple Oozie Workflow
This workflow defines 3 actions - ingestor, mergeLidar and mergeSignage. Each action is implemented as a Map/Reduce[4] job. The workflow starts with the start node, which transfer control to the Ingestor action. Once the ingestor step completes, a fork control node [4] is invoked, which will start execution of mergeLidar and mergeSignage in parallel[5]. Once both actions complete, the join control node [5] is invoked[6]. On successful completion of join node, the control is passed to the end node, which ends the process.
Once workflow is created it has to be deployed correctly. A typical Oozie deployment is a HDFS directory, containing workflow.xml (Listing 1), config-default.xml and a lib subdirectory, containing jar files of classes used by workflow actions.
(Click on the image to enlarge it.)

Figure 1: Oozie deployment
A config-default.xml file is optional and typically contains workflow parameters common to all workflow instances. A simple example of config-default.xml is presented at Listing 2.
<configuration> <property> <name>jobTracker</name> <value>sachicn003:2010</value> </property> <property> <name>nameNode</name> <value>hdfs://sachicn001:8020</value> </property> <property> <name>queueName</name> <value>default</value> </property> </configuration>
Listing 2: Config-default.xml
Once a workflow is deployed, an Oozie provides a command line utility [5] can be used to submit, start and manipulate a workflow. This utility typically runs on the edge node of Hadoop cluster[7]and requires a jobs properties file (see sidebar – configuring workflow properties) - Listing 3.
oozie.wf.application.path=hdfs://sachicn001:8020/user/blublins/workflows/IPSIngestion jobTracker=sachicn003:2010 nameNode=hdfs://sachicn001:8020
Listing 3: Job properties file
With job properties in place, a command presented at Listing 4 can be used to run an Oozie workflow.
oozie job –oozie http://sachidn002.hq.navteq.com:11000/oozie/ -D driveID=729-pp00002-2011-02-08-09-59-34 -D lidarChunk=4 -D signageChunk=20 -config job.properties –run
Listing 4: Run workflow command
Configuring Workflow PropertiesThere is some overlap between config-default.xml, jobs properties file and job arguments that can be passed to Oozie as part of command line invocations. Although documentation does not describe clearly when to use which, the overall recommendation is as follows:
The way Oozie processes these three sets of the parameters is as follows:
|
An Oozie console (Figure 2) can be used to watch the progress and results of workflow execution.
(Click on the image to enlarge it.)
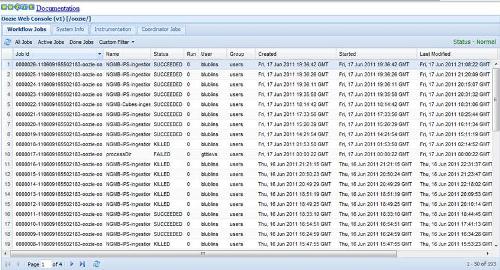
Figure 2: Oozie console
Oozie console can also be used to get details of the job execution, for example job log[8] (Figure 3)
(Click on the image to enlarge it.)
Figure 3: Oozie console – Job log
Programmatic Workflow invocation
Although command line interface, described above works well for the manual invocation of Oozie, it is sometimes is advantageous to invoke Oozie programmatically. This can be useful when Oozie worklows are either part of a specific application or a larger enterprise process. Such programmatic invocation can be implemented either using Oozie Web Services APIs [6] or Oozie Java client APIs [7]. A very simple Oozie java client invoking described above process is presented at Listing 5
package com.navteq.assetmgmt.oozie;import java.util.LinkedList;
import java.util.List;
import java.util.Properties;import org.apache.oozie.client.OozieClient;
import org.apache.oozie.client.OozieClientException;
import org.apache.oozie.client.WorkflowJob;
import org.apache.oozie.client.WorkflowJob.Status;public class WorkflowClient {
private static String OOZIE_URL = "http://sachidn002.hq.navteq.com:11000/oozie/";
private static String JOB_PATH = "hdfs://sachicn001:8020/user/blublins/workflows/IPSIngestion";
private static String JOB_Tracker = "sachicn003:2010";
private static String NAMENode = "hdfs://sachicn001:8020";OozieClient wc = null;
public WorkflowClient(String url){
wc = new OozieClient(url);
}public String startJob(String wfDefinition, List<WorkflowParameter> wfParameters)
throws OozieClientException{// create a workflow job configuration and set the workflow application path
Properties conf = wc.createConfiguration();
conf.setProperty(OozieClient.APP_PATH, wfDefinition);// setting workflow parameters
conf.setProperty("jobTracker", JOB_Tracker);
conf.setProperty("nameNode", NAMENode);
if((wfParameters != null) && (wfParameters.size() > 0)){
for(WorkflowParameter parameter : wfParameters)
conf.setProperty(parameter.getName(), parameter.getValue());
}
// submit and start the workflow job
return wc.run(conf);
}public Status getJobStatus(String jobID) throws OozieClientException{
WorkflowJob job = wc.getJobInfo(jobID);
return job.getStatus();
}public static void main(String[] args) throws OozieClientException, InterruptedException{
// Create client
WorkflowClient client = new WorkflowClient(OOZIE_URL);
// Create parameters
List<WorkflowParameter> wfParameters = new LinkedList<WorkflowParameter>();
WorkflowParameter drive = new WorkflowParameter("driveID","729-pp00004-2010-09-01-09-46");
WorkflowParameter lidar = new WorkflowParameter("lidarChunk","4");
WorkflowParameter signage = new WorkflowParameter("signageChunk","4");
wfParameters.add(drive);
wfParameters.add(lidar);
wfParameters.add(signage);
// Start Oozing
String jobId = client.startJob(JOB_PATH, wfParameters);
Status status = client.getJobStatus(jobId);
if(status == Status.RUNNING)
System.out.println("Workflow job running");
else
System.out.println("Problem starting Workflow job");
}
}
Listing 5: Simple Oozie java client
Here, first workflow client is initialized with Oozie server URL. Once initialization is complete, this client can be used to submit and start jobs (startJob method), get the status of the running job (getStatus method) and other operations.
Building java action, passing parameters to workflow
In our examples so far we have shown how to pass parameters to Java node using <arg> tag. Considering that java node is the main approach to introduce custom calculations to Oozie, it is also important to be able to pass data from Java node to Oozie.
According to java node documentation [3], the “capture-output” element can be used to propagate values from java node back into Oozie context. These values can then be accessed via EL-functions by other steps in the workflow. The return values need to be written out as a java properties format file. The name for such properties files can be obtained via a System property specified by the constant “JavaMainMapper.OOZIE_JAVA_MAIN_CAPTURE_OUTPUT_FILE” .A simple example demonstrating how to do this is presented at Listing 6.
package com.navteq.oozie; import java.io.File; import java.io.FileOutputStream; import java.io.OutputStream; import java.util.Calendar; import java.util.GregorianCalendar; import java.util.Properties;public class GenerateLookupDirs {
/**
* @param args
*/
public static final long dayMillis = 1000 * 60 * 60 * 24;
private static final String OOZIE_ACTION_OUTPUT_PROPERTIES = "oozie.action.output.properties";public static void main(String[] args) throws Exception {
Calendar curDate = new GregorianCalendar();
int year, month, date;
String propKey, propVal;String oozieProp = System.getProperty(OOZIE_ACTION_OUTPUT_PROPERTIES);
if (oozieProp != null) {
File propFile = new File(oozieProp);
Properties props = new Properties();for (int i = 0; I < 8; ++i)
{
year = curDate.get(Calendar.YEAR);
month = curDate.get(Calendar.MONTH) + 1;
date = curDate.get(Calendar.DATE);
propKey = "dir"+i;
propVal = year + "-" +
(month < 10 ? "0" + month : month) + "-" +
(date < 10 ? "0" + date : date);
props.setProperty(propKey, propVal);
curDate.setTimeInMillis(curDate.getTimeInMillis() - dayMillis);
}
OutputStream os = new FileOutputStream(propFile);
props.store(os, "");
os.close();
} else
throw new RuntimeException(OOZIE_ACTION_OUTPUT_PROPERTIES
+ " System property not defined");
}
}
Listing 6: Passing parameters to Oozie
In this example we assume that there is a directory in HDFS for every day. So this class first gets the current date and then calculates previous 7 closest date (including current) and passes directories names back to Oozie.
Conclusion
In this article we have introduced Oozie – a workflow engine for Hadoop and provided a simple example of its usage. In the next article we will look at a more complex example, allowing us to discuss more Oozie features.
Acknowledgements
Authors are thankful to our Navteq colleague Gregory Titievsky for providing some of the examples.
About the Authors
Boris Lublinsky is principal architect at NAVTEQ, where he is working on defining architecture vision for large data management and processing and SOA and implementing various NAVTEQ projects. He is also an SOA editor for InfoQ and a participant of SOA RA working group in OASIS. Boris is an author and frequent speaker, his most recent book "Applied SOA".
Michael Segel has spent the past 20+ years working with customers identifying and solving their business problems. Michael has worked in multiple roles, in multiple industries. He is an independent consultant who is always looking to solve any challenging problems. Michael has a Software Engineering degree from the Ohio State University.
[1] An edge node is a machine that has the Hadoop libraries installed , yet is not part of the actual cluster. It is for applications that have the ability to connect to the cluster and host ancillary services and end user applications which directly access the cluster.
[2] See this link for Oozie installation.
[3] The detail of these jobs are irrelevant for this article, so we do not present it here
[4] Map/Reduce jobs can be implemented in Oozie in two different ways – as true Map/Reduce action[2], where you specifiy Mapper and Reducer classes and their configuration or as java action [3] where you specify the class that is starting Map/Reduce job using Hadoop APIs. Because we already had all java mains that were using Hadoop APIs and were implementing some additional functionality, we have chosen the second approach.
[5] Oozie guarantees that both actions will be submitted to Job tracker in parallel. The actual parallelism in execution is outside of Oozie’ control and depends on requirements of the job, capacity of the cluster and scheduler used by your Map/Reduce installation.
[6] The role of the join action is to synchronize multiple threads of parallel execution started by fork actions. If all execution threads started by fork complete successfully, join action is waiting for all of them to complete. If at least on thread of execution fails, the kill node will “kill” remaining running threads.
[7] This node does not have to be the one, where Oozie is installed.
[8] While Oozie job log contains details of the workflow execution, in order to see details of action execution it is necessary to switch to Hadoop Map/Reduce Administration page.