Matlab---BP神经网络(获取数学表达式)
-
- 前言
- 源代码
- 数据预处理分析
- 1 相关性分析
- 2 聚类分析
- 3 随机获取训练数据和预测数据集
- 4 对数据进行归一化
- BP神经网络
- 1 BP神经网络结构本例
- 2 神经网络训练后权值和阈值查看
- 3 神经网络训练完输出与输入关系式
0 前言
训练数据下载:
data.mat
1. 源代码
【main.m】
%% 清空环境变量
clc
clear
%% 从Excel导入变量
load data;
%% 相关性分析
R = corrcoef(tempData);
figure;
ss = size(tempData,2);
%热图,将相关性可视化出来
imagesc(R);
set(gca,'xtick',1:ss);
set(gca,'ytick',1:ss);
set(gca,'xticklabel',variables);
set(gca,'yticklabel',variables);
axis([0 ss+1 0 ss+1]);
grid;
colorbar;
%% 获取BP神经网络训练数据
%通过聚类分析得到训练数据
allData = tempKmean(tempData,variables);
[m0,n0] = size(allData)
input = allData(:,1:(end-1));
output = allData(:,end)'; %% 随机选取s组训练数据,以及t组预测数据(s+t < 25000) s = m0-(m0/20); t = (m0)/20; k = rand(1,s+t); %重新得到向量k的有序(从小到大排列)向量m,并得到对应的下标向量n [m,n]=sort(k); input_train = input(n(1:s),:)';
output_train = output(n(1:s));
input_test = input(n(s+1:s+t),:)'; output_test = output(n(s+1:s+t)); %% 训练数据归一化 [inputn,inputps] = mapminmax(input_train); [outputn,outputps] = mapminmax(output_train); %% BP网络训练 %初始化网络结构 net=newff(inputn,outputn,6); net.trainParam.epochs=1000; net.trainParam.lr=0.1; net.trainParam.goal=0.00004; %网络训练 net=train(net,inputn,outputn); %% 用训练好的BP神经网络预测函数输出 %预测数据归一化 inputn_test=mapminmax('apply',input_test,inputps);
%预测输入预测
Y = sim(net,inputn_test);
figure;
plot(Y);
title('BP神经网络预测输出','FontName','Times New Roman','FontWeight','Bold','FontSize',16)
%% 输出结果反归一化
BPoutput = mapminmax('reverse',Y',outputps)'; figure; plot(BPoutput); title('输出结果反归一化','FontName','Times New Roman','FontWeight','Bold','FontSize',16);
%% 网络预测函数
% tansig数学表达式:a = tansig(n) = 2./(1+exp(-2*n))-1
% purlin数学表达式:a = purelin(n) = n
%获取权值和阈值
w1 = net.iw{1,1} %输入层到隐层的权值
b1 = net.b{1,1} %输入层到隐层的阈值
w2 = net.lw{2,1} %隐层到输出层的权值
b2 = net.b{2,1} %隐层到输出层的阈值
%预测输出 temp为两行四列临时变量如393 5.6 0.39 111.4
in = [393 5.6 0.39 111.4]
temp = [0 0;0 0;0 0;0 0]
temp(:,2) = in';
temp1 = mapminmax('apply',temp,inputps);
inputData = temp1(:,2);
%计算预测值
%隐含层的值
hidden = tansig(w1*inputData + b1)
%输出层的值
out = purelin(w2*hidden + b2);
%反归一化得到预测值
out = mapminmax('reverse',out,outputps)【tempKmean.m】
function allData = tempKmean(tempData,variables)
%%
%KMeans算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。
%然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。
%% 获取聚类原始数据
X = tempData(:,(end-1):end);
%% 聚类分析,蓝色为BP神经网络训练数据
opts = statset('Display','final');
%调用Kmeans函数
%X N*P的数据矩阵
%Idx N*1的向量,存储的是每个点的聚类标号
%Ctrs K*P的矩阵,存储的是K个聚类质心位置
%SumD 1*K的和向量,存储的是类间所有点与该类质心点距离之和
%D N*K的矩阵,存储的是每个点与所有质心的距离;
%Replicates ,聚类的重复次数
%15 为聚类重复次数
[Idx,Ctrs,SumD,D] = kmeans(X,2,'Replicates',15,'Options',opts);
%打印Ctrs SumD的值
Ctrs
SumD
%% 获取神经网络训练数据
test1Data = tempData(Idx==1,:);
test2Data = tempData(Idx==2,:);
[m1,n1] = size(test1Data)
[m2,n2] = size(test2Data)
I = find(test1Data(:,end-1) >= 600);
N = length(I)
if(N >= 12)
if(m1 < 100)
allData = test2Data;
%画出聚类为1的点。X(Idx==1,1),为第一类的样本的第一个坐标;X(Idx==1,2)为第二类的样本的第二个坐标
plot(X(Idx==1,1),X(Idx==1,2),'b.','MarkerSize',12);
hold on;
plot(X(Idx==2,1),X(Idx==2,2),'r.','MarkerSize',12);
hold on;
xlabel(variables(end-1),'FontName','Times New Roman','FontSize',14)
ylabel(variables(end),'FontName','Times New Roman','FontSize',14)
%绘出聚类中心点,kx表示是圆形
plot(Ctrs(:,1),Ctrs(:,2),'kx','MarkerSize',12,'LineWidth',4)
plot(Ctrs(:,1),Ctrs(:,2),'kx','MarkerSize',12,'LineWidth',4)
legend('*非经济航速训练数据*','*经济航速训练数据*','质心(Centroids)','Location','NW');
title('聚类分析','FontName','Times New Roman','FontWeight','Bold','FontSize',10);
box off;
else
%训练数据太多了,也包含了非常大的油耗量
allData = test1Data;
%画出聚类为1的点。X(Idx==1,1),为第一类的样本的第一个坐标;X(Idx==1,2)为第二类的样本的第二个坐标
plot(X(Idx==1,1),X(Idx==1,2),'r.','MarkerSize',12);
hold on;
plot(X(Idx==2,1),X(Idx==2,2),'b.','MarkerSize',12);
hold on;
xlabel(variables(end-1),'FontName','Times New Roman','FontSize',14)
ylabel(variables(end),'FontName','Times New Roman','FontSize',14)
%绘出聚类中心点,kx表示是圆形
plot(Ctrs(:,1),Ctrs(:,2),'kx','MarkerSize',12,'LineWidth',4)
plot(Ctrs(:,1),Ctrs(:,2),'kx','MarkerSize',12,'LineWidth',4)
legend('$经济航速训练数据$','$非经济航速训练数据$','质心(Centroids)','Location','NW');
title('聚类分析','FontName','Times New Roman','FontWeight','Bold','FontSize',10);
box off;
end
else
allData = test1Data;
%画出聚类为1的点。X(Idx==1,1),为第一类的样本的第一个坐标;X(Idx==1,2)为第二类的样本的第二个坐标
plot(X(Idx==1,1),X(Idx==1,2),'r.','MarkerSize',12);
hold on;
plot(X(Idx==2,1),X(Idx==2,2),'b.','MarkerSize',12);
hold on;
xlabel(variables(end-1),'FontName','Times New Roman','FontSize',14)
ylabel(variables(end),'FontName','Times New Roman','FontSize',14)
%绘出聚类中心点,kx表示是圆形
plot(Ctrs(:,1),Ctrs(:,2),'kx','MarkerSize',12,'LineWidth',4)
plot(Ctrs(:,1),Ctrs(:,2),'kx','MarkerSize',12,'LineWidth',4)
legend('#经济航速训练数据#','#非经济航速训练数据#','质心(Centroids)','Location','NW');
title('聚类分析','FontName','Times New Roman','FontWeight','Bold','FontSize',10);
box off;
end2. 数据预处理分析
2.1 相关性分析
2.2 聚类分析
为bp神经网络训练进行数据聚类,找出航速高,油耗低的数据,作为神经网络的训练数据。
2.3 随机获取训练数据和预测数据集
s = m0-(m0/20);
t = (m0)/20;
k = rand(1,s+t);
%重新得到向量k的有序(从小到大排列)向量m,并得到对应的下标向量n
[m,n]=sort(k);
input_train = input(n(1:s),:)'; output_train = output(n(1:s)); input_test = input(n(s+1:s+t),:)';
output_test = output(n(s+1:s+t)); 2.4 对数据进行归一化
%% 训练数据归一化
[inputn,inputps] = mapminmax(input_train);
[outputn,outputps] = mapminmax(output_train);
%预测数据归一化
inputn_test=mapminmax('apply',input_test,inputps);注:归一化函数mapminmax默认归一化到[-1,1]之间,又tansig函数输入要求是[-1,1],所以采用默认的归一化设置。
3. BP神经网络
3.1 BP神经网络结构(本例)
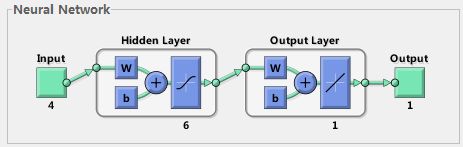
6个输入,即输入层8个节点,一个输出,即输出层一个节点。包含一个隐含层,设置为了6个节点,其中隐含层默认的激励函数为tansig,输出层默认的传递函数为purlin。其中w为各层权值,b为各层阈值。
tansig数学表达式:a = tansig(n) = 2./(1+exp(-2*n))-1
purlin数学表达式:a = purelin(n) = n
3.2 神经网络训练后权值和阈值查看
net.iw{1,1}; %输入层到隐层的权值
net.b{1,1}; %输入层到隐层的阈值
net.lw{2,1}; %隐层到输出层的权值
net.b{2,1}; %隐层到输出层的阈值

3.3 神经网络训练完输出与输入关系式
输入变量为xi,(i=1,2,...,ni)向nh个隐含层单元传递输入信号,即每一个隐含单元的激励Oj满足如下方程:
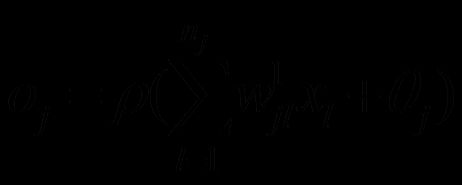
式中,ρ为隐含层神经元的激励函数( a = tansig(n) = 2./(1+exp(-2*n))-1 )。同样输出层单元为:
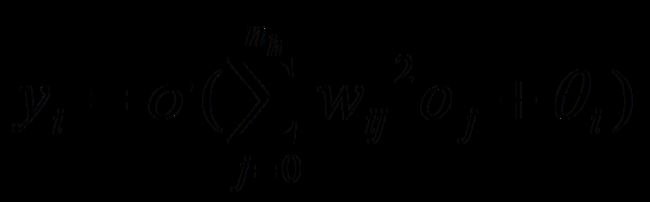
式中,
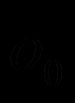 =1,σ为输出层神经元的激励函数;j为隐含层的第j个节点,i为第i个输入变量。
=1,σ为输出层神经元的激励函数;j为隐含层的第j个节点,i为第i个输入变量。
在MATLAB中,我们上面说到了隐含层的默认激励函数为tansig,输出层的激励函数为purlin。代入上式即可。
具体的程序计算为:
%% 网络预测函数
% tansig数学表达式:a = tansig(n) = 2./(1+exp(-2*n))-1
% purlin数学表达式:a = purelin(n) = n
%获取权值和阈值
w1 = net.iw{1,1} %输入层到隐层的权值
b1 = net.b{1,1} %输入层到隐层的阈值
w2 = net.lw{2,1} %隐层到输出层的权值
b2 = net.b{2,1} %隐层到输出层的阈值
%预测输出 temp为两行四列临时变量如393 5.6 0.39 111.4
in = [393 5.6 0.39 111.4]
temp = [0 0;0 0;0 0;0 0]
temp(:,2) = in';
temp1 = mapminmax('apply',temp,inputps);
inputData = temp1(:,2);
%计算预测值
%隐含层的值
hidden = tansig(w1*inputData + b1)
%输出层的值
out = purelin(w2*hidden + b2);
%反归一化得到预测值
out = mapminmax('reverse',out,outputps)out 为预测的经济航速输出。