Facebook Haystack 管理百亿照片
转自:http://server.it168.com/a2009/0504/274/000000274726.shtml
当今时代信息的爆炸性增长,使得数据管理变得富有挑战。以Facebook 为例,每周新增照片为2亿2000万张,约25TB,加上 Facebook 用户之前已经上传的总容量超过1.5PB 的150亿张照片。如何有效管理好这些庞大的数据量意义重大。本文引自 Facebook 工程师文章,希望对读者有所启发。
旧的 NFS 照片架构面临挑战
之前,Facebook采用的NFS照片系统架构分以下几个层:
# 上传层接收用户上传的照片并保存在 NFS 存储层。
# 照片服务层接收 HTTP 请求并从 NFS 存储层输出照片。
# NFS存储层建立在商业存储系统之上。
因为每张照片都以文件形式单独存储,这样庞大的照片量导致非常庞大的元数据规模,超过了 NFS 存储层的缓存上限,导致每次招聘请求会上传都包含多次I/O操作。庞大的元数据成为整个照片架构的瓶颈。这就是为什么 Facebook 主要依赖 CDN 的原因。为了解决这些问题,他们做了两项优化:
# Cachr: 一个缓存服务器,缓存 Facebook 的小尺寸用户资料照片。
# NFS文件句柄缓存:部署在照片输出层,以降低 NFS 存储层的元数据开销。
注:CDN- Content Delivery Network,即内容分发网络。其目的是通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到最接近用户的网络"边缘",使用户可以就近取得所需的内容,解决Internet网络拥挤的状况,提高用户访问网站的响应速度。从技术上全面解决由于网络带宽小、用户访问量大、网点分布不均等原因所造成的用户访问网站响应速度慢的问题。
新的Haystack照片架构消除瓶颈
新的照片架构将输出层和存储层合并为一个物理层,建立在一个基于 HTTP 的照片服务器上,照片存储在一个叫做 haystack 的对象库,以消除照片读取操作中不必要的元数据开销。新架构中,I/O 操作只针对真正的照片数据(而不是文件系统元数据)。haystack 可以细分为以下几个功能层:
# HTTP 服务器
# 照片存储
# Haystack 对象存储
# 文件系统
# 存储空间
存储
Haystack 部署在商业存储刀片服务器上,典型配置为一个2U的服务器,包含:
# 两个4核CPU
# 16GB - 32GB 内存
# 硬件 RAID,含256-512M NVRAM 高速缓存
# 超过12个1TB SATA 硬盘
每个刀片服务器提供大约10TB的存储能力,使用了硬件 RAID-6, RAID 6在保持低成本的基础上实现了很好的性能和冗余。不佳的写性能可以通过高速缓存解决,硬盘缓存被禁用以防止断电损失。
文件系统
Haystack 对象库是建立在10TB容量的单一文件系统之上。文件系统中的每个文件都在一张区块表中对应具体的物理位置,目前使用的文件系统为 XFS。
Haystack 对象库
Haystack 是一个简单的日志结构,存储着其内部数据对象的指针。一个 Haystack 包括两个文件,包括指针和索引文件:(图1)
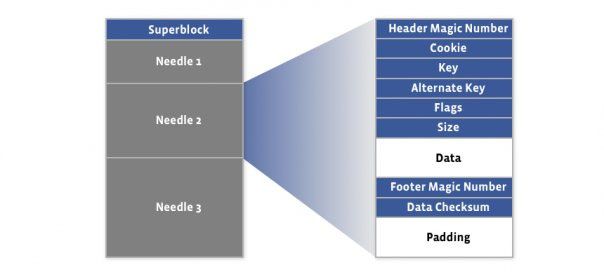
Haystack 对象存储结构(图2)
指针和索引文件结构(图3、4)

Haystack 写操作
Haystack 写操作同步将指针追加到 haystack 存储文件,当指针积累到一定程度,就会生成索引写到索引文件。为了降低硬件故障带来的损失,索引文件还会定期写道存储空间中。
Haystack 读操作
传到 haystack 读操作的参数包括指针的偏移量,key,代用Key,Cookie 以及数据尺寸。Haystack 于是根据数据尺寸从文件中读取整个指针。
Haystack 删除操作
删除比较简单,只是在 Haystack 存储的指针上设置一个已删除标志。已经删除的指针和索引的空间并不回收。
照片存储服务器
照片存储服务器负责接受 HTTP 请求,并转换成相应的 Haystack 操作。为了降低I/O操作,该服务器维护着全部 Haystack 中文件索引的缓存。服务器启动时,系统就会将这些索引读到缓存中。由于每个节点都有数百万张照片,必须保证索引的容量不会超过服务器的物理内存。
对于用户上传的图片,系统分配一个64位的独立ID,照片接着被缩放成4种不同尺寸,每种尺寸的图拥有相同的随机 Cookie 和 ID,图片尺寸描述(大,中,小,缩略图)被存在代用key 中。接着上传服务器通知照片存储服务器将这些资料联通图片存储到 haystack 中。
每张图片的索引缓存包含以下数据(图5)
Haystack 使用 Google 的开源 sparse hash data 结构以保证内存中的索引缓存尽可能小。
照片存储的写/修改操作
写操作将照片数据写到 Haystack 存储并更新内存中的索引。如果索引中已经包含相同的 Key,说明是修改操作。
照片存储的读操作
传递到 Haystack 的参数包括 Haystack ID,照片的 Key, 尺寸以及 Cookie,服务器从缓存中查找并到 Haystack 中读取真正的数据。
照片存储的删除操作
通知 Haystack 执行删除操作之后,内存中的索引缓存会被更新,将便宜量设置为0,表示照片已被删除。
重新捆扎
重新捆扎会复制并建立新的 Haystack,期间,略过那些已经删除的照片的数据,并重新建立内存中的索引缓存。
HTTP 服务器
Http 框架使用的是简单的 evhttp 服务器。使用多线程,每个线程都可以单独处理一个 HTTP 请求。
结束语
Haystack 是一个基于 HTTP 的对象存储,包含指向实体数据的指针,该架构消除了文件系统元数据的开销,并实现将全部索引直接存储到缓存,以最小的 I/O 操作实现对照片的存储和读取。