linux网桥浅析
|
什么是桥接?
|
简单来说,桥接就是把一台机器上的若干个网络接口“连接”起来。其结果是,其中一个网口收到的报文会被复制给其他网口并发送出去。以使得网口之间的报文能够互相转发。
交换机就是这样一个设备,它有若干个网口,并且这些网口是桥接起来的。于是,与交换机相连的若干主机就能够通过交换机的报文转发而互相通信。如下图:主机A发送的报文被送到交换机S1的eth0口,由于eth0与eth1、eth2桥接在一起,故而报文被复制到eth1和eth2,并且发送出去,然后被主机B和交换机S2接收到。而S2又会将报文转发给主机C、D。
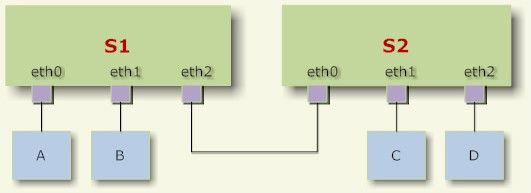
交换机在报文转发的过程中并不会篡改报文数据,只是做原样复制。然而桥接却并不是在物理层实现的,而是在数据链路层。交换机能够理解数据链路层的报文,所以实际上桥接 却又 不是单纯的报文转发。
交换机会关心填写在报文的数据链路层头部中的Mac地址信息(包括源地址和目的地址),以便了解每个Mac地址所代表的主机都在什么位置(与本交换机的哪个网口相连)。在报文转发时,交换机就只需要向特定的网口转发即可,从而避免不必要的网络交互。这个就是交换机的“地址学习”。但是如果交换机遇到一个自己未学习到的地址,就不会知道这个报文应该从哪个网口转发,则只好将报文转发给所有网口(接收报文的那个网口除外)。
比如主机C向主机A发送一个报文,报文来到了交换机S1的eth2网口上。假设S1刚刚启动,还没有学习到任何地址,则它会将报文转发给eth0和eth1。同时,S1会根据报文的源Mac地址,记录下“主机C是通过eth2网口接入的”。于是当主机A向C发送报文时,S1只需要将报文转发到eth2网口即可。而当主机D向C发送报文时,假设交换机S2将报文转发到了S1的eth2网口(实际上S2也多半会因为地址学习而不这么做),则S1会直接将报文丢弃而不做转发(因为主机C就是从eth2接入的)。
然而,网络拓扑不可能是永不改变的。假设我们将主机B和主机C换个位置,当主机C发出报文时(不管发给谁),交换机S1的eth1口收到报文,于是交换机S1会更新其学习到的地址,将原来的“主机C是通过eth2网口接入的”改为“主机C是通过eth1网口接入的”。
但是如果主机C一直不发送报文呢?S1将一直认为“主机C是通过eth2网口接入的”,于是将其他主机发送给C的报文都从eth2转发出去,结果报文就发丢了。所以交换机的地址学习需要有超时策略。对于交换机S1来说,如果距离最后一次收到主机C的报文已经过去一定时间了(默认为5分钟),则S1需要忘记“主机C是通过eth2网口接入的”这件事情。这样一来,发往主机C的报文又会被转发到所有网口上去,而其中从eth1转发出去的报文将被主机C收到。
linux的桥接实现
相关模型
linux内核支持网口的桥接(目前只支持以太网接口)。但是与单纯的交换机不同,交换机只是一个二层设备,对于接收到的报文,要么转发、要么丢弃。小型的交换机里面只需要一块交换芯片即可,并不需要CPU。而运行着linux内核的机器本身就是一台主机,有可能就是网络报文的目的地。其收到的报文除了转发和丢弃,还可能被送到网络协议栈的上层(网络层),从而被自己消化。
linux内核是通过一个虚拟的网桥设备来实现桥接的。这个虚拟设备可以绑定若干个以太网接口设备,从而将它们桥接起来。如下图(摘自ULNI):
网桥设备br0绑定了eth0和eth1。对于网络协议栈的上层来说,只看得到br0,因为桥接是在数据链路层实现的,上层不需要关心桥接的细节。于是协议栈上层需要发送的报文被送到br0,网桥设备的处理代码再来判断报文该被转发到eth0或是eth1,或者两者皆是;反过来,从eth0或从eth1接收到的报文被提交给网桥的处理代码,在这里会判断报文该转发、丢弃、或提交到协议栈上层。
而有时候eth0、eth1也可能会作为报文的源地址或目的地址,直接参与报文的发送与接收(从而绕过网桥)。
相关数据结构
要使用桥接功能,我们需要在编译内核时指定相关的选项,并让内核加载桥接模块。然后通过“brctl addbr {br_name}”命令新增一个网桥设备,最后通过“brctl addif {eth_if_name}”命令绑定若干网络接口。完成这些操作后,内核中的数据结构关系如下图所示(摘自ULNI):
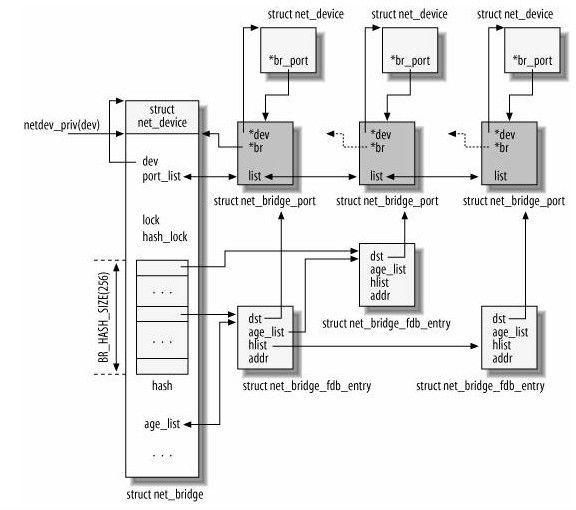
其中最左边的net_device是一个代表网桥的虚拟设备结构,它关联了一个net_bridge结构,这是网桥设备所特有的数据结构。
在net_bridge结构中,port_list成员下挂一个链表,链表中的每一个节点(net_bridge_port结构)关联到一个真实的网口设备的net_device。网口设备也通过其br_port指针做反向的关联(那么显然,一个网口最多只能同时被绑定到一个网桥)。
net_bridge结构中还维护了一个hash表,是用来处理地址学习的。当网桥准备转发一个报文时,以报文的目的Mac地址为key,如果可以在hash表中索引到一个net_bridge_fdb_entry结构,通过这个结构能找到一个网口设备的net_device,于是报文就应该从这个网口转发出去;否则,报文将从所有网口转发。
接收过程
在《linux网络报文接收发送浅析》一文中我们看到,网口设备接收到的报文最终通过net_receive_skb函数被网络协议栈所接收。
net_receive_skb(skb);
这个函数主要做三件事情:
1、如果有抓包程序需要skb,将skb复制给它们;
2、处理桥接;
3、将skb提交给网络层;
这里我们只关心第2步。那么,如何判断一个skb是否需要做桥接相关的处理呢?skb->dev指向了接收这个skb的设备,如果这个net_device的br_port不为空(它指向一个net_bridge_port结构),则表示这个net_device正在被桥接,并且通过net_bridge_port结构中的br指针可以找到网桥设备的net_device结构。于是调用到br_handle_frame函数,让桥接的代码来处理这个报文;
br_handle_frame(net_bridge_port, skb);
如果skb的目的Mac地址与接收该skb的网口的Mac地址相同,则结束桥接处理过程(返回到net_receive_skb函数后,这个skb会最终被提交给网络层);
否则,调用到br_handle_frame_finish函数将报文转发,然后释放skb(返回到net_receive_skb函数后,这个skb就不会往网络层提交了);
br_handle_frame_finish(skb);
首先通过br_fdb_update函数更新网桥设备的地址学习hash表中对应于skb的源Mac地址的记录(更新时间戳及其所指向的net_bridge_port结构);
如果skb的目的地址与本机的其他网口的Mac地址相同(但是与接收该skb的网口的Mac地址不同,否则在上一个函数就返回了),就调用br_pass_frame_up函数,该函数会将skb->dev替换成网桥设备的dev,然后再调用netif_receive_skb来处理这个报文。这下子netif_receive_skb函数被递归调用了,但是这一次却不会再触发网桥的相关处理函数,因为skb->dev已经被替换,skb->dev->br_port已经是空了。所以这一次netif_receive_skb函数最终会将skb提交给网络层;
否则,通过__br_fdb_get函数在网桥设备的地址学习hash表中查找skb的目的Mac地址所对应的dev,如果找到(且通过其时间戳认定该记录未过期),则调用br_forward将报文转发给这个dev;而如果找不到则调用br_flood_forward进行转发,该函数会遍历网桥设备中的port_list,找到每一个绑定的dev(除了与skb->dev相同的那个),然后调用br_forward将其转发;
br_forward(net_bridge_port, skb);
将skb->dev替换成将要进行转发的dev,然后调用br_forward_finish,而后者又会调用br_dev_queue_push_xmit。
最终,br_dev_queue_push_xmit会调用dev_queue_xmit将报文发送出去(见《linux网络报文接收发送浅析》)。注意,此时skb->dev已经被替换成进行转发的dev了,报文会从这个网口被转发出去;
发送过程
在《linux网络报文接收发送浅析》一文中我们看到,协议栈上层需要发送报文时,调用dev_queue_xmit(skb)函数。如果这个报文需要通过网桥设备来发送,则skb->dev指向一个网桥设备。网桥设备没有使用发送队列(dev->qdisc为空),所以dev_queue_xmit将直接调用dev->hard_start_xmit函数,而网桥设备的hard_start_xmit等于函数br_dev_xmit;
br_dev_xmit(skb, dev);
通过__br_fdb_get函数在网桥设备的地址学习hash表中查找skb的目的Mac地址所对应的dev,如果找到,则调用br_deliver将报文发送给这个dev;而如果找不到则调用br_flood_deliver进行发送,该函数会遍历网桥设备中的port_list,找到每一个绑定的dev,然后调用br_deliver将其发送(此处逻辑与之前的转发很像);
br_deliver(net_bridge_port, skb);
这个函数的逻辑与之前转发时调用的br_forward很像。先将skb->dev替换成将要进行转发的dev,然后调用br_forward_finish。如前面所述,br_forward_finish又会调用到br_dev_queue_push_xmit,后者最终调用dev_queue_xmit将报文发送出去。
以上过程忽略了对于广播或多播Mac地址的处理,如果Mac地址是广播或多播地址,就向所有绑定的dev转发报文就行了。
另外,关于地址学习的过期记录,专门有一个定时器周期性地调用br_fdb_cleanup函数来将它们清除。
生成树协议
对于网桥来说,报文的转发、地址学习其实都是很简单的事情。在简单的网络环境中,这就已经足够了。
而对于复杂的网络环境,往往需要对数据通路做一定的冗余,以便当网络中某个交换机出现故障、或交换机的某个网口出现故障时,整个网络还能够正常使用。
那么,我们假设在上面的网络拓扑中增加一条冗余的连接,看看会发生什么事情吧。
假设交换机S1和S2都是刚刚启动(没有学习到任何地址),此时主机C向B发送一个报文。交换机S2的eth2口收到报文,并将其转发到eth0、eth1、eth3,并且记录下“主机C由eth2接入”。交换机S1在其eth2和eth3口都会收到报文,eth2口收到的报文又会从eth3口(及其他口)转发出去、eth3口收到的报文也会从eth2口(及其他口)转发出去。于是交换机S2的eth0、eth1口又将再次收到这个报文,报文的源地址还是主机C。于是S2相继更新学习到的地址,记录下“主机C由eth0接入”,然后又更新为“主机C由eth1接入”。然后报文又继续被转发给交换机S1,S1又会转发回S2。形成一个回路,周而复始,并且每一次轮回还会导致报文被复制给其他网口,最终形成网络风暴。整个网络可能就瘫痪了。
可见,我们之前讨论的交换机是不能在这样的带有环路的拓扑中使用的。但是如果要想给网络添加一定的冗余连接,则又必定会存在环路,这该怎么办呢?
IEEE规范定义了生成树协议(STP),如果网络拓扑中的交换机支持这种协议,则它们会通过BPUD报文(网桥协议数据单元)进行通信,相互协调,暂时阻塞掉某些交换机的某些网口,使得网络拓扑不存在环路,成为一个树型结构。而当网络中某些交换机出现故障,这些被暂时阻塞掉的网口又会重新启用,以保持整个网络的连通性。
由一个带有环路的图生成一棵树的算法是很简单的,但是,正所谓“不识庐山真面目,只缘身在此山中”,网络中的每一台交换机都不知道确切的网络拓扑,并且网络拓扑还可能动态地改变。要通过交换机间的信息传递(传递BPUD报文)来生成这么一棵树,那就不是一件简单的事情了。来看看生成树协议是怎么做到的吧。
确定树根
要生成一棵树,第一步是确定树根。协议规定,只有作为树根节点的交换机才能发送BPUD报文,以协调其他交换机。当一台交换机启动时,它不知道谁是树根,则他会把自己就当作树根,从它的各个网口发出BPUD报文。
BPUD报文可以说是表明发送者身份的报文,里面含有一个“root_id”,也就是发送者的ID(发送者都认为自己就是树根)。这个ID由两部份组成,优先级+Mac地址。ID越小则该交换机越重要,越应该被任命为树根。ID中的优先级是由网络管理员来指定的,当然性能越好的交换机应该被指定为越高的优先级(即越小的值)。两个交换机的ID比较,首先比较的就是优先级。而如果优先级相同,则比较其Mac地址。就好比两个人地位相当,只好按姓氏笔划排列了。而交换机的Mac地址是全世界唯一的,所以交换机ID不会相同。
一开始,各个交换机都自以为是地认为自己是树根,都发出了BPUD报文,并在其中表明了自己的身份。而各个交换机自然也会收到来自于其他交换机的BPUD报文,如果发现别人的ID更小(优先级更高),这时,交换机才意识到“天外有天、人外有人”,于是停止自己愚昧的“自称树根”的举动。并且将收到的带有更高优先级的BPUD报文转发,让其他人也知道有这么个高优先级的交换机存在。
最终,所有交换机会达成共识,知道网络中有一个ID为XXXX的家伙,他才是树根。
确定上行口
确定了树根,也就确定了网络拓扑的最顶层。而其他交换机则需要确定自己的某个网口,作为其向上(树根方向)转发报文的网口(上行口)。想一想,如果一个交换机有多个上行口,则网络拓扑必然会存在回路。所以一个交换机的上行口有且只有一个。
那么这个唯一的上行口怎么确定呢?取各个网口中,到树根的开销最小的那一个。
上面说到,树根发出的BPUD报文会被其他交换机所转发,最终每个交换机的某些网口会收到这个BPUD。BPUD中还有这么三个字段,“到树根的开销”、“交换机ID”、“网口ID”。交换机在转发BPUD时,会更新这三个字段,把“交换机ID”更新为自己的ID,把“网口ID”更新为转发该BPUD的那个网口的编号,而“到树根的开销”则被增加一定的值(根据实际的转发开销,由交换机自己决定。可能是个大概值)。树根最初发出的BPUD,“ 到树根的开销 ”为0。每转发一次,该字段就被增加相应的开销值。
假设树根发出了一个BPUD,由于转发,一个交换机的同一个网口可能会多次收到这个BPUD报文的复本。这些复本可能经过了不同的转发路径才来到这个网口,因此有着不同的“到树根的开销”、“交换机ID”、“网口ID”。这三个字段的值越小,表示按照该BPUD转发的路径,到达树根的开销越小,就认为该BPUD的优先级越高(其实后两个字段也只是启到“按姓氏笔划排列”的作用)。交换机会记录下在其每一个网口上收到的优先级最高的BPUD,并且只有当一个网口当前收到的这个BPUD比它所记录的BPUD(也就是曾经收到的优先级最高的BPUD)的优先级还高时,这个交换机才会将该BPUD报文由其他网口转发出去。最后,比较各个网口所记录的BPUD的优先级,最高者被作为交换机的上行口。
确定需要被阻塞的下行口
交换机除了其上行口之外的其他网口都是下行口。交换机的上行路径不会存在环路,因为交换机都只有唯一的上行口。
而不同交换机的多个下行口有可能是相互连通的,会形成环路。(这些下行口也不一定是直接相连,可能是由物理层的转发设备将多个交换机的多个下行口连在一起。)生成树协议的最后一道工序就是在这一组相互连通的下行口中,选择一个让其转发报文,其他网口都被阻塞。由此消除存在的环路。而那些没有与其他下行口相连的下行口则不在考虑之列,它们不会引起环路,都照常转发。
不过,既然下行口两两相连会产生回路,是不是把这些相连的下行口都阻塞就好了呢?前面提到过可能存在物理层设备将多个网口同时连在一起的情况(如集线器Hub,尽管现在已经很少用了),如图:
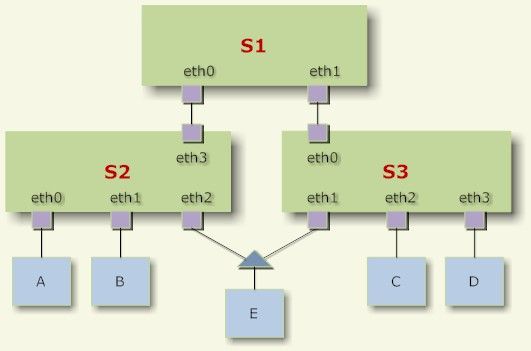
假设交换机S2的eth2口和交换机S3的eth1口是互相连通的两个下行口,如果武断地将这两网口都阻塞,则主机E就被断网了。所以,这两个网口还必须留下一个来提供报文转发服务。
那么对于一组相互连通的下行口,该选择谁来作为这个唯一能转发报文的网口呢?
上面说到,每个交换机在收到优先级最高的BPUD时,都会将其转发。转发的时候,“到树根的开销”、“交换机ID”、“网口ID”都会被更新。于是对于一组相互连通的下行口,从谁那里转发出来的BPUD优先级最高,就说明从它到达树根的开销最小。于是这个网口就可以继续转发报文,而其他网口都被阻塞。
从实现上来说,每个网口需记录下自己转发出去的BPUD的优先级是多少。如果其没有收到比该优先级更高的BPUD(没有与其他下行口相连,收不到BPUD;或者与其他下行口相连,但是收到的BPUD优先级较低),则网口可以转发;否则网口被阻塞。
经过交换机之间的这一系列BPUD报文交换,生成树完成。然而网络拓扑也可能因为一些人为因素(如网络调整)或非人为因素(如交换机故障)而发生改变。于是生成树协议中还定义了很多机制来检测这种改变,而后触发新一轮的BPUD报文交换,形成新的生成树。这个过程就不再赘述了。