NLP | 自然语言处理 - 标注问题与隐马尔科夫模型(Tagging Problems, and Hidden Markov Models)
什么是标注?
在自然语言处理中有一个常见的任务,即标注。常见的有:1)词性标注(Part-Of-Speech Tagging),将句子中的每个词标注词性,例如名词、动词等;2)实体标注(Name Entity Tagging),将句子中的特殊词标注,例如地址、日期、人物姓名等。
下图所示的是词性标注的案例,当输入一个句子时,计算机自动标注出每个词的词性。
下图所示的是实体标注的案例,当输入一个句子时,计算机自动标注出特殊词的实体类别。

粗略看来,这并不是一个简单问题。首先每个词都可能有多个含义,不同情况表达不同含义;其次,一个词的含义或者词性也受到前后多个词的影响。
标注问题的数学表达
在找到解决方案之前,我们最好先用数学的语言来描述一下这个问题。当我们得到一个句子时,我们可以把它看做一个向量。令句子s有共计n个单词,第i个单词用xi来表示,显然s =
x1, x2, ... xn。因此问题可以描述成,对于每个单词xi,我们需要分别给定一个标注yi,因而获得句子的标注y = y1, y2, ... yn。
综上所述,训练模型时我们期望对于任何一个句子s,我们需要得到所有可能出现的标注的概率p(y | s),其中概率最大的y即是我们需要的结果。最终的表达式为tagging(s)= arg max(p(y|s))。
接下来,我们需要考虑如何建立训练集并从中学习出上述的模型。首先,我需要获得一个已经标注好的语料库,语料库中有若干句子,每个句子中的每个词都已有标识。然后,对于语料库中出现的所有的句子s与对应的标识y,我们可以学习出条件概率p(y, s),即某个句子与其对应标识的出现概率。其次,由于语料库无法包含所有可能出现的句子,所以我们希望能够得到一个更加宽泛的表达式,通过贝叶斯公式,我们可以非常看出p(y, s) = p(y) * p(s | y),同时p(y | s) = p(y) * p(s | y) / p(s);我们需要比较的是p(y | s)中的最大值而无需获得p(y | s),因此显然p(s)的具体取值并不重要,因此我们只需要考虑tagging(s)= arg max(p(y) * p(s | y))。
由于语料库无法保存所有客观存在的句子,我们必须找到一种方法来估计p(y)与p(s | y)的取值,而其中一种非常有名的方法就是隐马尔科夫模型。
隐马尔科夫模型
我们依然回到上述问题,给定一个句子s = x1, x2, ... xn,我们给出一个标识组合y = y1, y2, ... yn,使得y = arg max(p(y) * p(s | y)) = arg max(p(x1, x2, ... , xn, y1, y2, ..., yn))。
根据上一章《语言模型》所提到的,我们依然对每个句子做一点优化:
1)增加一个开始符号”*“,我们定义所有句子都是以”*“开始,即X-1 = X0 = *;
2)增加一个结束符号”STOP“,我们定义所有句子都是以”STOP“结束。
同时,
隐马尔科夫模型需要我们做一些额外的假设来简化模型:
1)yk只与前几个元素相关,即标识的语义相关性只影响前后几个元素;
2)单词xk与对应的yk不受其他单词的影响,即p(xi | yi)相互独立.
经过简化以后,我们以三阶隐马尔科夫模型为例,表达式为 p(y1, y2, … yn | x1, x2, … xn) = p(y1, y2, … yn) * p(x1, x2, … xn | y1, y2, … yn) = ∏q(yj | yj-2, yj-1) * ∏ e(xi | yi)。显然,简化后的模型,单个单词在语料库中出现的频率会远远高于句子整体出现的频率。
参数估算
有了隐马尔科夫模型之后,我们需要做的就只是估算参数q(yj | yj-2, yj-1)与e(xi | yi)。q(yj | yj-2, yj-1)在上一章《 语言模型 》中有详细的解释,而e(xi | yi)通过统计每个单词在语料库中的出现情况可以轻松获得。然而有一种特殊情况,某些单词如果在语料库中没有出现,那么e(xi | yi) = 0将导致整体句子的出现概率为0。为了解决这个问题,我们可以采用一个简单的解决方案:
1)首先将语料库中所有的单词分为频繁词与非频繁词(通过一个阈值来确定);
2)频繁词的e(xi | yi)将直接从语料库中统计得出;
3)非频繁词的通过预定的规则划分到多个群组中,通过统计群组的词频来确定e(xi | yi)。
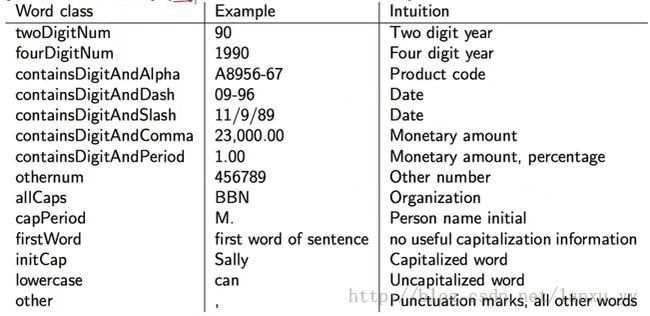
例如,常见的分组方法如下图所示。这种方式对于日期、姓名、缩写等特殊词的效果很好。
算法的复杂度
假设我们已经训练得到 q(yj | yj-2, yj-1) 与 e(xi | yi),给定一个句子s = x1, x2, ... xn,我们应当如何得到标注y = y1, y2, ... yn。
方法1: 暴力方法,遍历所有可能出现的y1, y2, ... yn组合,计算概率并找出概率最大的值。显然,暴力方法的时间复杂度不会令人满意。
方法2:动态规划,定义一个动态规划表达式m(k, u, v),k表示句子的第k位,u,v表示前k为组成的子句的最后两个单词的标识。因此,递归方程可以表述为m(k, u, v) = max(m(k-1, w, u) * q(v | w, u) * e( x | v))。关于动态规划方法, leetcode里有不少案例可以说明。