NLP | 自然语言处理 - 考虑词汇的语法解析(Lexicalized PCFG)
语法解析的改进
NLP | 自然语言处理 - 语法解析(Parsing, and Context-Free Grammars) 这一章我们讲到了上下文无关语法(PCFG - Probabilistic Context-Free Grammar)的解析方法。PCFG在许多情况下并没有考虑词的顺序关系,例如NN NN(Milk Cup)这样的情况两个名词被等价的对待,因为也可能导致语法解析的二义性。为了获得更好的解析正确率,我们将在PCFG的基础上做一些改进。
对于每一条规则,我们将添加一个规则的首要词(head)。例如 VP =>
VP PP,VP就是这个规则的首要词。那么首要词如何来确定呢?其实我们可以通过我们对英语语法的理解来制定一些规则来确定首要词。
例如,对名词短语 (NP)而言,可以包含如下规则(规则按顺序匹配,命中是停止):
1)当规则包含NN, NNS或者NNP时,选择最右侧的NN, NNS或者NNP作首要词,例如the milk
cup
2)当规则包含一个NP时,选择最左侧的NP,例如
(NP the car) (PP in (NP the street))
3)当规则包含一个JJ时,选择最右侧的JJ,例如the
old
4)当规则包含一个CD时,选择最右侧的CD,例如
1000
5)选择最右侧的元素
对于动词短语(VP)而言,可以保护如下规则(规则按顺序匹配,命中是停止):
1)当规则包含Vi、Vt时,选择最左侧的Vi或者Vt,例如
go home
2)当规则包含VP时,选择最左侧的VP,例如
(VP go home) (to (VP have lunch))
3)选择最左侧的元素
有了首要词(header)这个概念以后,我们的语法树将可以被表示得更加的精细。但是显然,随之而来的计算量也将更大,同时对训练集数据量的要求也更多。
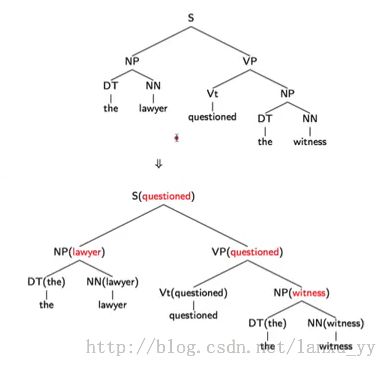
定义
与上一章 NLP | 自然语言处理 - 语法解析(Parsing, and Context-Free Grammars) 的定义类似,我们将改进后的语法解析定义如下,并称之为Chomsky Normal Form。
1)N表示一组非叶子节点的标注,例如{S、NP、VP、N...}
2)Σ表示一组叶子结点的标注,例如{boeing、is...}
3)R表示一组规则,每条规则可以表示为
a) X(h)->Y1(h)Y2(w),X∈N,Yi∈N
,h,w∈Σ
b) X(h)->Y1(w)Y2(h),X∈N,Yi∈N,h,w∈Σ
c) X(h)->h,X∈N,h∈Σ
4)S表示语法树开始的标注
已知一棵语法书时,我们可以通过如下的公式来预测该句子出现的概率,整个过程与上一章所述非常类似。

参数估计
那么,下一个问题是我们如何获得X(h)->Y1(w)Y2(h)这样一个规则的出现概率呢,例如q(S(saw) -> NP(man) VP(saw))?
我们需要对公式做一个变型,
q(S(saw) -> NP(man) VP(saw)) = q(S ->2 NP
VP
| S, saw) * q(man | S -> NP
VP
, saw)。右侧第一个子式表示当句子的首要词是saw时出现S -> NP VP的概率,右侧第二个子式表示当首要词为saw并且语法确定为S -> NP VP的情况下出现man的概率。
第二个问题是当我们的训练数据集中有足够多的S -> NP(man) VP(saw)时我们可以比较好的学习这个规则。那么,如果我们没有足够多的规则时,我们应该如何去估计呢?与之前章节的处理方法类似,我们可以用平滑的方式去获得近似的值,如下式所示:
q(S ->2 NP VP | S, saw) = k1 * p(S ->2 NP VP | S, saw) + k2 * p(S ->2 NP VP | S)