电子商务网站-全文检索系统总体介绍
有很久没有更新了,过去的一年,升级TSE4.0系统把大家累坏了,最近给新员工准备了一个培训ppt,贴在这里吧。csdn的图片上传越改越糟糕,连续传2张图片就不行了,新图片不能和删除的图片同名,估计是删除数据延迟的问题,体验不爽。好多图片都传不上去
全文检索的一些概念
文档:搜索引擎最小信息检索单元。对于网页搜索一条文档理解为一个网页,对paipai网搜索,一条文档表示一个完整的商品信息
倒排索引:关键词到文档编号的映射。
{pair<KeyWord,docid1,docid2…..>}
索引切换:将索引服务器中生成好的索引数据拷贝到搜索服务器
全文检索系统总体架构
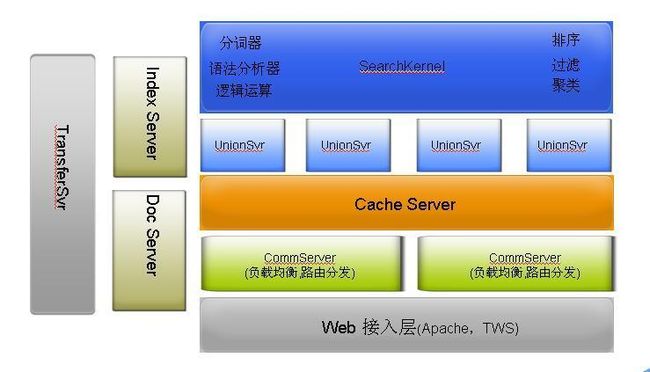
Web: 使用TWS服务器,接受用户请求,处理业务逻辑,渲染页面,80%以上的产品需求集中在这里
Commserver:协议分发服务器,将不同的请求发送到不同的后台
CacheServer:缓存服务器,协议级Cache,支持即时删除,LRU淘汰,有70%左右的命中率
UnionServer:聚合服务器,将分布式搜索系统返回的检索结果合并
SearchKernel:检索服务器,负责处理搜索请求
DocServer:文档服务器,负责存储具体的文档信息,返回完整的文档信息给用户
IndexServer:索引服务器,负责生成索引
TransferServer:中转服务器,负责综合排序,将商城数据格式化为搜索的标准数据格式
全文检索的处理流程
用户发送搜索请求,Web层对用户的输入条件进行过滤,进行同义词、直达…处理,将处理后的请求发送到commserver
Commserver根据Appid对请求分发到Cache或者其他后台,负载均衡
Cache收到请求后判断是否命中,命中则返回,不命中则转发给UnionServer,同时cache存储返回结果
UnionServer收到请求后,负载均衡,分发给各个SearchKernel并行检索
SearchKernel检索后,返回排好序的DocId集合
Union对各个后台返回的Docid集合进行合并
Union把合并后的结果集发送到DocSvr,获取完整文档信息,返回给CacheSvr
SearchKernel的处理流程一
SearchKernel收到用户请求,解析出查询串
针对查询串进行分析,生成语法树
对语法树每个节点,进行分词查询倒排索引
对查询出的多个倒排索引按照语法关系,进行逻辑运算
按照DocId进行其他查询条件的过滤
对DocId进行排序
将DocId返回给UnionSvr
SearchKernel的处理流程二
索引的格式一
Tis文件:
<TermCnt,TermInfos>
TermInfos-><termInfo>……
termInfo-><Term,DocFreq,.frq文件偏移,.prx文件偏移>
Term-><PrefixLen,Suffrix,FieldNum>
PrefixLen->前缀的长度,例如:china,chinese,Prefix为”chin”,PrefixLen=4,suffix=“ese”
PS:Term表示一个短语(索引分词的最小粒度)
Freq文件:
表示一个Term在文档中出现的次数
<TermFreqs>TermCount
TermFreqs-><TermFreq>
TermFreq->DocID,Freq?
DocID/2表示文档编号的偏移(相对于前一个文档),如果DocID为奇数,表示Term在文档只出现过一次,为偶数是,Freq表示了出现多少次。
例如:一个词在文档3中出现1次,在文档9中出现了8次,则TermFreqs中出现如下序列:
TermFreqs=<7,18,8>
索引的格式二
prx文件:
表示一个Term在文档中出现的位置,和frq文件配合使用
<TermPositions>
TermPositions-><Postions>
Positions-><pos>
Posà位置序列,从小到大排序
例如:某个term在文档1的位置3,5出现,在文档2的位置4,9出现,Positions的序列如下:
<3,2,4,5>
tii文件:
Tis文件的索引信息,方便快速查找tis文件中某个域信息
Fdx文件:
Fdt文件的索引
<fieldpostions>
Feildpostionsà某个文档在fdt中的位置信息,定长,可以随机访问
Fdt文件:
存储具体的域信息
<fieldcount,<fieldnum,Bits,Value>>
索引的存储方法
差分存储
{1,4,7,9}存储为{1,3,3,2}
VInt压缩
每字节的高位表示是否还有剩余字节
低七位表示数值
0~127使用一个字节表示
128:00000001 10000000
分布式索引
为什么需要分布式
减低数据压力,便于并行处理
如何分布
数据切分方式
如何扩容
针对部分节点扩容,不需要每次都用翻倍的方式扩容
增量索引
数据量不断增大,索引文件变大
增量切换的时间增长,切换的风险增加
增量索引和全量索引的合并
实时搜索引擎
搜索的准确性
案例一
商品A:上海鲜花速递
商品B:青岛海鲜特价供应
用户输入“海鲜”,商品A,B同时命中如何解决排序问题?
案例二
用户搜索“诺基亚”出现很多“诺基亚”的耳机
用户搜索“N72”,会出现很多赠送“N72耳机“的商品
关键词类目优先
针对主产品和附属产品设置不同的权重
Nokia手机的权重大于Nokia耳机的权重
对于一些无法区分主产品和附属产品的,通过配置来解决
如何做到自动化,不需要人工配置?
从用户的搜索日志统计,自动更新
关键词直达
对于一些含义明确的关键词,不需要再进行全文检索
搜索“N72”,直接到N72的类目
缺点是什么?
我们强制修改了用户的搜索条件,增加了类目过滤
搜索的结果数变少
类目优先可以解决上面的问题,但是增加了后台的复杂度,更新也相对比较困难。直达可以直接在前台处理。
模糊匹配
用户输入长关键词时,容易出现搜索不到
例如:”新款波司登羽绒服”,”诺基亚N72手机“
问题根源:词位置信息的约束
如果去掉词位置信息判断是否就可以解决这类问题?
用户搜索“手机充电器”
商品A包含”买诺基亚N72手机送充电器“
比较完善的解决方案:设置权重多重排序
同音词、同义词
同义词,主要用户扩大搜索结果范围
搜索“婴儿“,标题中含有“宝宝”的也可以出来
搜索“一”,标题中含有“1”的也可以出来
同音词,主要用于纠错
搜索“诺积压“,提示用户是否需要搜索”诺基亚“
同音判断
搜索”Marcbook”,提示用户是否需要搜索“MacBook”
步长判断
Smartbox
按照词被搜索频率的排序
数据每天增量更新
支持分词
吞吐>1000个/秒
拼音到汉字的映射(开发中)
拼音缩写到汉字的映射(开发中)
未来的挑战
准实时
预排序
程序级Cache
聚类
并行计算
负载均衡
丰富索引格式