fgetws和fread读取不同编码文本文件时的结果
平时写各种程序时经常会遇到字符编码的问题,对于字符编码比较熟悉的人来说,这方面就比较简单了,但对于接触时间不长、初学者来说,简直就是噩梦一般,非常烦人。
之前自己在C++程序读取txt文件时遇到了乱码问题,主要涉及到两个函数:fgetws和fread,文本文件的编码主要涉及ANSI,unicode,utf-16,utf-8,下面结合自己的测试用例进行较详细的说明,如果有错误或者不严谨的地方,还请网友和读者在评论中指出,我好改过来。
一、有关文件编码的问题
字符集编码的资料有很多,这里不做详细介绍。本文涉及的主要有以下几个:
1、ANSI:GB2312,GBK
2、unicode:UTF-16,UTF-8
二、读取文本的函数主要有两个:fgetws和fgetws_ex,其代码如下所示:
fgetws的实现代码如下:
int getFileContent(const UChar* filename, wstringEx &content) //UChar和wstringEx都是定义的别名,在此可暂时理解为wchar_t和wstring
{
content = L"";
if (filename == NULL || u_strlen(filename) == 0) {
return -1;
}
FILE *fpSource;
if((fpSource=_wfopen(filename,ICUPub::TransUtf8ToUtf16("rt")))==NULL) //读物文本内容,ICU为平台无关的开源库,感兴趣的可以自己去查资料
return -1;
wchar_t* sParagraph = new wchar_t[4*1024];
wstring contentTmp;
while(!feof(fpSource))
{
if(fgetws(sParagraph,4*1024,fpSource)==NULL)//fgetws函数使用的关键地方
{
printf("\n fgetws_ex can not read \n");
getchar();
continue;
}
contentTmp.append(sParagraph);
}
content=wstringEx(contentTmp);
delete [] sParagraph;
fclose(fpSource);
printf("\n fileCONTENT:%s--fileEND \n",ICUPub::ws2s(content).c_str());
return 0;
}
fgetws_ex的完整代码如下(其本质是读取文本的函数fread):
UChar* fgetws_ex(UChar* string, int n, FILE* stream)
{
if (!string || !stream || feof(stream) || n <= 0)
{
return NULL;
}
int i = 0;
while (i < n-1 && !feof(stream))
{
if (fread(&string[i], sizeof(UChar), 1, stream) != 1)
break;
// Check the character readed, break if it's '\n'
if (string[i] == L'\n')
{
i++;
break;
}
i++;
}
string[i] = 0x0;
return string;
}
int getFileContent(const UChar* filename, wstringEx &content)
{
content = (const UChar*)L"";
if (filename == NULL || u_strlen(filename) == 0)
{
return -1;
}
FILE *fpSource;
<span style="white-space:pre"> </span>if((fpSource=_wfopen(filename,(const UChar*)L"rt"))==NULL)
return -1;
UChar *sParagraph=new UChar[4*1024];
while(!feof(fpSource))
{
if(fgetws_ex(sParagraph,4*1024,fpSource)==0)//Get a paragrah
{
printf("\n fgetws_ex can not read \n");
getchar();
continue;
}
// 读取的是GBK编码(windows下ANSI格式),将其转换为unicode的UTF-16编码
UChar *sParagraphUTF16 = ICUPub::TransGbkToUtf16((char *)sParagraph,strlen(ICUPub::TransUtf16ToUtf8(sParagraph)));
content.append(sParagraphUTF16);
}
delete [] sParagraph;
fclose(fpSource);
printf("\n fileCONTENT:%s--fileEND \n",ICUPub::ws2s(content).c_str());
return 0;
}
三、利用上面的两个函数,读取本地不同编码的txt文件(本人测试时用的文本很长,但前面几个字是:“继家电、汽车下乡")
对于这几个字,我们先给出区位码(GB2312)、GBK、UTF-16、UTF-8的编码结果
这里附上一个小软件,可以查询汉子的区位码、GBK、UTF-16三种编码或者通过编码查询汉子(UTF-8的编码可以网上查),如下所示:
然后的工作就是用我们的函数测试txt文件的读取结果,这里待读取的文件总共有几种编码格式:ANSI、unicode、UTF-16、UTF-8四种。
具体的格式转换,直接使用文本工具的另存为即可实现:
使用记事本打开txt,另存为:
使用UltraEdit-32打开文本后,另存为:
这几种编码又涉及到几个概念:BOM(Byte Order Mark)、大端模式(Big Endian)、小端模式(Small Endian)。
这几个概念都是用来表示数据的字节存储顺序的,网上非常多的资料,大家可自行百度,不难理解,这里仅做一个简单的说明:
我们认为在存储空间里,数据都是从低字节地址开始存储,那么对于 “ABCD”这一个2字节的数据,先存储高字节AB呢?还是先存储低字节CD呢?若先存储AB则称为大端模式,即低地址存储高字节;若先存储CD,则为小端模式,即低地址存储低字节;
所谓BOM,即 字节顺序标记,这几种编码又固定的数值来表示字节的存储顺序,如下所示:
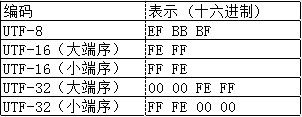
其中UTF-8不需要使用BOM,若开始字节为“EF BB BF”,则表明为UTF-8编码方式。
我们的测试中,只使用四种编码方式进行测试:ANSI、unicode、UTF-16、UTF-8。
测试结果如下表所示:

具体的分析未完、待续