C++深入体验之旅八:枚举类型和结构体
1.什么是枚举类型
在基本的数据类型中,无外乎就是些数字和字符。但是某些事物是较难用数字和字符来准确地表示的。比如一周有七天,分别是Sunday、Monday、Tuesday、Wednesday、Thursday、Friday和Saturday。如果我们用整数0、1、2、3、4、5、6来表示这七天,那么多下来的那些整数该怎么办?而且这样的设置很容易让数据出错,即取值超出范围。我们能否自创一个数据类型,而数据的取值范围就是这七天呢?
C++中有一种数据类型称为枚举(Enumeration)类型,它允许用户自己来定义一种数据类型,并且列出该数据类型的取值范围。
我们说变量就好像是一个箱子,而数据类型就好像是箱子的类型,所以我们在创建某个枚举类型的变量的时候,必须先把这个枚举类型设计好,即把箱子的类型设计好。定义枚举类型的语法格式为:
enum 类型名{常量1[,常量2,……常量n]};
定义枚举类型的位置应该在程序首次使用该类型名之前,否则程序无法识别该类型。枚举类型中我们列出的常量称为枚举常量。它并不是字符串也不是数值,而只是一些符号。
如果我们要定义一周七天的日期类型,可以这样写:
enum day{Sunday,Monday,Tuesday,Wednesday,Thursday,Friday,Saturday};
这时候,程序中就有了一种新的数据类型——day,它的取值范围就是Sunday到Saturday的那七天。我们已经把类型设计好,下面我们就能来创建一个day类型的变量了:
day today;
today=Sunday;
这样,day类型的变量today的值就是Tuesday了。
下面我们来写一段程序来运用一下枚举类型的数据:(程序9.1)
#include "iostream.h" enum day{Sunday,Monday,Tuesday,Wednesday,Thursday,Friday,Saturday}; void nextday(day &D);//向后一天是星期几,参数为day类型,是程序中首次使用该类型名 void display(day D);//显示某一天是星期几 int main() { day today=Sunday; for (int i=0;i<7;i++) { cout <<"Data in today=" <<today <<endl; display(today); nextday(today); } return 0; } void nextday(day &D) { switch(D) { case Sunday: D=Monday; break; case Monday: D=Tuesday; break; case Tuesday: D=Wednesday; break; case Wednesday: D=Thursday; break; case Thursday: D=Friday; break; case Friday: D=Saturday; break; case Saturday: D=Sunday; break; } } void display(day D) { switch(D) { case Sunday: cout <<"Sunday" <<endl; break; case Monday: cout <<"Monday" <<endl; break; case Tuesday: cout <<"Tuesday" <<endl; break; case Wednesday: cout <<"Wednesday" <<endl; break; case Thursday: cout <<"Thursday" <<endl; break; case Friday: cout <<"Friday" <<endl; break; case Saturday: cout <<"Saturday" <<endl; break; } }运行结果:
Data in today=0 Sunday Data in today=1 Monday Data in today=2 Tuesday Data in today=3 Wednesday Data in today=4 Thursday Data in today=5 Friday Data in today=6 Saturday根据运行结果,我们发现在day型变量today中保存的竟然是整数!也就是说,一个整数和一个枚举常量一一对应了起来,要注意是一一对应,而不是相等。但是如果我们把整数直接赋值给today变量,则会发生错误。虽然枚举类型的实质是整数,但是电脑还是会仔细检查数据类型,禁止不同数据类型的数据互相赋值。另外,在一般情况下,枚举类型是不能进行算术运算的。
2.什么是结构体(结构类型)
学校要统计学生情况,于是Tomato同学给出了一张自己的信息表:
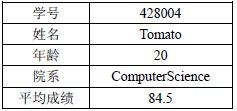
从上表来看,我们需要两个字符串分别用来存储姓名,需要两个整型变量分别来存储学号和年龄,还需要一个浮点型变量来存储平均成绩。一个学生已经需要至少5个存储空间,更何况一个学校有几千个学生,那将需要几万个存储空间。如果有这么多的变量,显然是很难管理的。
我们把变量比作为箱子。在现实生活中,如果小箱子太多太杂乱了,我们会拿一个大收纳箱来,把小箱子一个个有序地放到收纳箱里面。这样一来,在我们视线里的箱子就变少了,整理起来也会比较方便。那么,我们能否把这么多凌乱的变量整理到一个变量当中呢?
C++中有一种数据类型称为结构(Structure)类型,它允许用户自己定义一种数据类型,并且把描述该类型的各种数据类型一一整合到其中。

如上表所示,每个学生的信息成为了一个整体。一个学生拥有学号、姓名、年龄、院系和平均成绩这五项属性,我们把这些属性称为这个结构类型的成员数据(Data Member)。每项属性的数据类型也在旁边做了说明。这样一来,杂乱的数据和每个学生一一对应了起来,方便了我们管理。
定义一种结构类型的语法格式为:
struct 结构类型名 { 数据类型 成员数据1; 数据类型 成员数据2; …… 数据类型 成员数据n; };和定义枚举类型类似,定义结构类型的位置必须在首次使用该类型名之前,否则程序将无法正确识别该类型。要注意,定义完结构类型后的分号是必不可少的,否则将会引起错误。如果我们要创建前面的学生类型,可以写作:
struct student { int idNumber; char name[15]; int age; char department[20]; float gpa; };这时候,就有了一个新的数据类型,称为student。我们要用这种student类型来创建一个变量,并可以依次对它的成员数据进行初始化:
student s1={428004, "Tomato",20, "ComputerScience",84.5};这样就有了一个student类型的变量s1。s1有五项属性,它们应该怎么表达呢?如果用自然语言描述,我们会说s1的idNumber、s1的name等等。在C++中,我们用一个点“.”来表示“的”,这个“.”称为 成员操作符。
下面我们就来看一段程序,了解结构类型的基本使用:(程序9.2)
#include "iostream.h" struct student { int idNumber; char name[15]; int age; char department[20]; float gpa; }; int main() { student s1,s2;//首次使用student类型名,定义必须在这之前。 cout <<"输入学号:"; cin >>s1.idNumber;//成员数据可以被写入 cout <<"输入姓名:"; cin >>s1.name; cout <<"输入年龄:"; cin >>s1.age; cout <<"输入院系:"; cin >>s1.department; cout <<"输入成绩:"; cin >>s1.gpa; cout <<"学生s1信息:" <<endl <<"学号:" <<s1.idNumber <<"姓名:" <<s1.name <<"年龄:" <<s1.age <<endl <<"院系:" <<s1.department <<"成绩:" <<s1.gpa <<endl;//成员数据也能够被读出 s2=s1;//把s1的给各个成员数据值分别复制到s2中 cout <<"学生s2信息:" <<endl <<"学号:" <<s2.idNumber <<"姓名:" <<s2.name <<"年龄:" <<s2.age <<endl <<"院系:" <<s2.department <<"成绩:" <<s2.gpa <<endl; return 0; }运行结果:
输入学号:428004 输入姓名:Tomato 输入年龄:20 输入院系:ComputerScience 输入成绩:84.5 学生s1信息: 学号:428004姓名:Tomato年龄:20 院系:ComputerScience成绩:84.5 学生s2信息: 学号:428004姓名:Tomato年龄:20 院系:ComputerScience成绩:84.5我们看到,结构的成员数据是既可以被读出,也可以被写入的。而且,相同类型的结构变量还能够用一个赋值操作符“=”把一个变量的内容赋值给另一个变量。
3.结构体与函数
结构也可以用作函数参数或返回值。
结构作为参数
我们在前面的一些章节中知道,变量作为函数的参数,了解它是值传递还是地址传递是非常重要的。因为这意味着参数在函数体内的修改是否会影响到该变量本身。
不同于数组,结构是按值传递的。也就是说整个结构的内容都复制给了形参,即使某些成员数据是一个数组。
下面,我们就以一个实例来证明这一点:(程序9.3.1)
#include "iostream.h" struct student { int idNumber; char name[15]; int age; char department[20]; float gpa; }; void display(student arg);//结构作为参数 int main() { student s1={428004, "Tomato",20, "ComputerScience",84.5};//声明s1,并对s1初始化 cout <<"s1.name的地址" <<&s1.name <<endl; display(s1); cout <<"形参被修改后……" <<endl; display(s1); return 0; } void display(student arg) { cout <<"学号:" <<arg.idNumber <<"姓名:" <<arg.name <<"年龄:" <<arg.age <<endl <<"院系:" <<arg.department <<"成绩:" <<arg.gpa <<endl; cout <<"arg.name的地址" <<&arg.name <<endl; for (int i=0;i<6;i++)//企图修改参数的成员数据 { arg.name[i]='A'; } arg.age++; arg.gpa=99.9f; }运行结果:
s1.name的地址0x0012FF54 学号:428004姓名:Tomato年龄:20 院系:ComputerScience成绩:84.5 arg.name的地址0x0012FED8 形参被修改后…… 学号:428004姓名:Tomato年龄:20 院系:ComputerScience成绩:84.5 arg.name的地址0x0012FED8通过上面这个程序,我们发现在函数中修改形参的值对实参是没有影响的。并且通过输出变量s1和参数arg的成员数据name所在地址,我们可以知道两者是不相同的,即整个name数组也复制给了参数arg。
如果我们希望能在函数修改实参,则可以使用引用的方法。由于结构往往整合了许多的成员数据,它的数据量也绝对不可小觑。使用值传递虽然能够保护实参不被修改,但是却会或多或少地影响到程序的运行效率。所以,一般情况下,我们选择 引用传递的方法。
结构作为返回值
一般情况下,函数只能返回一个变量。如果要尝试返回多个变量,那么就要通过在参数中使用引用,再把实参作为返回值。然而,这种方法会导致一大堆参数,程序的可读性也较差。
当结构出现以后,我们可以把所有需要返回的变量整合到一个结构中来,问题就解决了。我们通过一段程序来了解如何让函数返回一个结构:(程序9.3.2)
#include "iostream.h" struct student { int idNumber; char name[15]; int age; char department[20]; float gpa; }; student initial();//初始化并返回一个结构 void display(student arg); int main() { display(initial());//输出返回的结构 return 0; } void display(student arg) { cout <<"学号:" <<arg.idNumber <<"姓名:" <<arg.name <<"年龄:" <<arg.age <<endl <<"院系:" <<arg.department <<"成绩:" <<arg.gpa <<endl; } student initial() { student s1={428004, "Tomato",20, "ComputerScience",84.5};//初始化结构变量 return s1;//返回结构 }运行结果:
学号:428004姓名:Tomato年龄:20 院系:ComputerScience成绩:84.5
4.结构数组与结构指针
结构是一种数据类型,因此它也有对应的结构数组和指向结构的指针。
结构数组
定义结构数组和定义其他类型的数组在语法上并无差别。需要注意的是,在定义结构数组之前,我们必须先定义好这个结构。比如:
struct student { int idNumber; char name[15]; int age; char department[20]; float gpa; }; …… student S[3]={ {428004, "Tomato",20, "ComputerScience",84.5}, {428005, "OOTTMA",20, "ComputerScience",85.0}, {428006, "OTA",20, "ComputerScience",89.8}}; ……使用结构数组只要遵循结构和数组使用时的各项规则即可,在此不作赘述。
结构指针
在上一章我们了解到指针的一个重要作用就是实现内存的动态分配(堆内存)。待我们学完了这一章,我们会发现结构指针也是一个非常有用的工具。
所谓结构指针就是指向结构的指针。定义好一个结构之后,定义一个结构指针变量的语法格式为:
结构类型名 *指针变量名;
我们知道一般的指针是通过间接引用操作符“*”来访问它指向的变量。那么我们如何访问结构指针所指向的变量的成员数据呢?这里要介绍箭头操作符“->”,我们用它可以访问到指针指向的变量的成员数据。它的格式为:
指针变量名->成员数据
需要注意的是,箭头操作符的左边一定是一个结构指针,而成员操作符的左边一定是一个结构变量,两者不能混淆使用。
下面我们来看一段程序,掌握如何使用结构指针:(程序9.4)
#include "iostream.h" struct student { int idNumber; char name[15]; int age; char department[20]; float gpa; }; void display(student *arg);//结构指针作为函数参数 int main() { student s1={428004, "Tomato",20, "ComputerScience",84.5};//初始化结构变量 student *s1ptr=&s1;//定义结构指针变量,并把s1的地址赋值给s1ptr display(s1ptr); return 0; } void display(student *arg) { cout <<"学号:" <<arg->idNumber <<"姓名:" <<arg->name <<"年龄:" <<arg->age <<endl <<"院系:" <<arg->department <<"成绩:" <<arg->gpa <<endl;//用箭头操作符访问成员数据 }运行结果:
学号:428004姓名:Tomato年龄:20 院系:ComputerScience成绩:84.5
5.链表
大家都知道自行车,可是你有没有仔细观察过自行车的链条呢?如下图9.5.1就是一段自行车链条的样子。
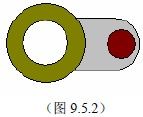
我们发现,自行车的链条虽然很长,却是由一个个相同的小环节连接而成的。如左下图9.5.2所示。每个环节又可以分成两部分:一部分是一个铁圈,让别的环节能够连接它;另一部分则是一个铁拴,可以去连接别的环节。于是,将这些环节一一连接起来,就形成了长长的链条。
这时候,我们想到了这样一种结构:
struct node { int data; node *next; };这个结构有两个成员数据,一个是整数data,另外一个是指向这种结构的指针next。那么如果有若干个这样的结构变量,就能像自行车链条一样,把这些变量连接成一条链子。如左下图9.5.3所示。
我们把这些利用结构指针连接起来的结构变量称为 链表(Link List),每一个结构变量(相当于链条中的每个环节)称为 链表的结点(Node)。如右上图9.5.4所示。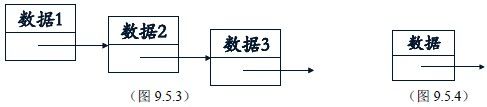
和数组一样,链表也可以用来存储一系列的数据,它也是电脑中存储数据的最基本的结构之一。然而,我们已经拥有了数组,也了解了数组的动态分配(堆内存),我们为什么还需要链表呢?
相信很多人都玩过即时战略游戏(RTS),比如时下流行的魔兽争霸、曾红极一时的红色警戒。可是大家有没有考虑过,每个战斗单位都有它们各自的属性,电脑又是如何为我们造出来的部队分配内存的呢?
显然,部队的数量在程序执行之前是未知的。如果用数组来存储这些数据,那么就会造成游戏前期浪费内存(没有那么多的部队),游戏后期存储空间不够(战斗单位数大大增加)的情况。
那么使用数组的动态分配行不行呢?还是不行。因为部队的数量在程序执行的时候仍然是未知的。甚至连玩家自己也不知道要造多少战斗单位,只是根据战斗的实际情况来发展自己的势力。所以,这时候最合理的内存分配方式就是每造一个战斗单位分配一个内存空间。
然而,新问题又出现了:建造各单位的时间一般不可能是完全连续的,根据不同时刻程序运行的实际情况,每个单位分配到的内存空间也不是连续的了。空间不连续就意味着没有了方便的数组下标。我们就很难把这些零零散散的内存空间集中起来管理。
链表的出现改变了这个情况。它可以在程序运行时根据实际需要一个个分配堆内存空间,并且用它的指针可以把一系列的空间串联起来,就像一条链子一样。这样一来,我们就能够利用指针对整个链表进行管理了。
6.链表的创建与遍历
上一节,我们介绍了链表的概念。在这一节,我们将介绍如何用程序来实现一个链表。在具体实现之前,我们先要明确一下我们有哪些任务:
- 能够创建一个具有若干个结点的链表。
- 能够访问到链表中的每一个结点,即输出每个结点的数据。这种操作称为遍历。
- 能够根据数据查找到结点所在的位置。
- 能够在链表的任意位置插入一个结点。
- 能够在链表的任意位置删除一个结点。
- 能够在程序结束前清除整个链表,释放内存空间。
我们知道链表也是动态分配的,虽然每次只分配一个结构变量(结点),但却少不了指向这个结构变量的指针。如果任何一个分配给我们的结构变量失去了指向它的指针,那么这个内存空间将无法释放,就造成了内存泄漏。由于指针还维系着各结点之间关系,指针的丢失造成了结点之间断开,整个链表就此被破坏。
所以,我们要保证每个结点都在我们的控制之内,即我们能够通过各种手段,利用指针访问到链表的任一个结点。这也是我们在所有对链表的操作过程中始终要注意的一点。
接下来,我们把链表的创建和遍历分析得更加具体化:
- 由于第一个结点也是动态分配的,因此一个链表始终要有一个指针指向它的表头,否则我们将无法找到这个链表。我们把这个表头指针称为head。
- 在创建一个多结点的链表时,新的结点总是连接在原链表的尾部的,所以我们必须要有一个指针始终指向链表的尾结点,方便我们操作。我们把这个表尾指针称为pEnd。
- 每个结点都是动态分配的,每分配好一个结点会返回一个指针。由于head和pEnd已经有了各自的岗位,我们还需要一个指针来接受刚分配好的新结点。我们把这个创建结点的指针称为pS。
- 在遍历的过程中,需要有一个指针能够灵活动作,指向链表中的任何一个结点,以读取各结点的数据。我们把这个访问指针称为pRead。
- 我们把创建链表和遍历各自写为一个函数,方便修改和维护。
做完了这些分析,我们可以开始着手写这个程序了:(程序9.6.1)
#include "iostream.h" struct node//定义结点结构类型 { char data;//用于存放字符数据 node *next;//用于指向下一个结点(后继结点) }; node * create();//创建链表的函数,返回表头 void showList(node *head);//遍历链表的函数,参数为表头 int main() { node *head; head=create();//以head为表头创建一个链表 showList(head);//遍历以head为表头的链表 return 0; } node * create() { node *head=NULL;//表头指针,一开始没有任何结点,所以为NULL node *pEnd=head;//表为指针,一开始没有任何结点,所以指向表头 node *pS;//创建新结点时使用的指针 char temp;//用于存放从键盘输入的字符 cout <<"Please input a string end with '#':" <<endl; do//循环至少运行一次 { cin >>temp; if (temp!='#')//如果输入的字符不是结尾符#,则建立新结点 { pS=new node;//创建新结点 pS->data=temp;//新结点的数据为temp pS->next=NULL;//新结点将成为表尾,所以next为NULL if (head==NULL)//如果链表还没有任何结点存在 { head=pS;//则表头指针指向这个新结点 } else//否则 { pEnd->next=pS;//把这个新结点连接在表尾 } pEnd=pS;//这个新结点成为了新的表尾 } } while (temp!='#');//一旦输入了结尾符,则跳出循环 return head;//返回表头指针 } void showList(node *head) { node *pRead=head;//访问指针一开始指向表头 cout <<"The data of the link list are:" <<endl; while (pRead!=NULL)//当访问指针存在时(即没有达到表尾之后) { cout <<pRead->data;//输出当前访问结点的数据 pRead=pRead->next;//访问指针向后移动 } cout <<endl; }运行结果:
Please input a string end with '#': Tomato# The data of the link list are: Tomato这个程序的功能是把输入的字符串保存到链表中,然后把它输出。从程序中我们可以看出,create函数的主要工作有:
①做好表头表尾等指针的初始化。
②反复测试输入的数据是否有效,如果有效则新建结点,并做好该结点的赋值工作。将新建结点与原来的链表连接,如果原链表没有结点,则与表头连接。
③返回表头指针。
下图9.6.1给出了create函数创建链表的过程。
程序中showList函数的主要工作有:
①初始化访问指针。
②如果访问指针不为空,则输出当前结点的数据,否则函数结束。
③访问指针向后移动,并重复第二项工作。
注意,虽然上述程序可以运行,但是它没有将内存释放,严格意义上来说,它是一个不完整的程序。
7.链表的查询
在对链表进行各种操作时,需要先对某一个结点进行查询定位。假设链表中没有数据相同的结点,我们可以编写这样一个函数,查找到链表中符合条件的结点:(程序9.6.2)
node * search(node *head,char keyWord)//返回结点的指针 { node *pRead=head; while (pRead!=NULL)//采用与遍历类似的方法,当访问指针没有到达表尾之后 { if (pRead->data==keyWord)//如果当前结点的数据和查找的数据相符 { return pRead;//则返回当前结点的指针 } pRead=pRead->next;//数据不匹配,pRead指针向后移动,准备查找下一个结点 } return NULL;//所有的结点都不匹配,返回NULL }
8.节点的插入和删除
插入结点
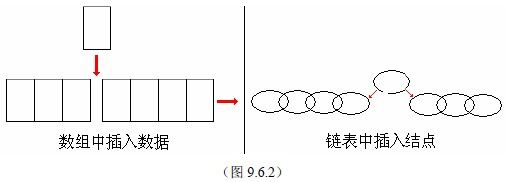
数组在内存中是顺序存储的,要在数组中插入一个数据就变得颇为麻烦。这就像是在一排麻将中插入一个牌,必须把后面的牌全部依次顺移。然而,链表中各结点的关系是由指针决定的,所以在链表中插入结点要显得方便一些。这就像是把一条链子先一分为二,然后用一个环节再把它们连接起来。如下图9.6.2所示。
下面我们先对插入结点这个功能具体分析一下:
- 我们必须知道对哪个链表进行操作,所以表头指针head是必须知道的。
- 为了确定插入位置,插入位置前的结点指针pGuard是必须是知道的。
- 用一个newnode指针来接受新建的结点。
- 如果要插入的位置是表头,由于操作的是表头指针而不是一个结点,所以要特殊处理。
- 在插入结点的过程中,始终要保持所有的结点都在我们的控制范围内,保证链表的完整性。为了达到这一点,我们采用先连后断的方式:先把新结点和它的后继结点连接,再把插入位置之前的结点与后继结点断开,并与新结点连接。如下图9.6.3所示。
做完了分析,我们可以开始编写插入函数了。为了简单起见,我们规定新结点插入位置为数据是关键字的结点之后,这样就可以使用刚才编写好的search函数了。如果该结点不存在,则插入在表头。则插入函数如下:(程序9.6.3)
void insert(node * &head,char keyWord,char newdata)//keyWord是查找关键字符 { node *newnode=new node;//新建结点 newnode->data=newdata;//newdata是新结点的数据 node *pGuard=search(head,keyWord);//pGuard是插入位置前的结点指针 if (head==NULL || pGuard==NULL)//如果链表没有结点或找不到关键字结点 {//则插入表头位置 newnode->next=head;//先连 head=newnode;//后断 } else//否则 {//插入在pGuard之后 newnode->next=pGuard->next;//先连 pGuard->next=newnode;//后断 } }
删除结点
与插入数据类似,数组为了保持其顺序存储的特性,在删除某个数据时,其后的数据都要依次前移。而链表中结点的删除仍然只要对结点周围小范围的操作就可以了,不必去修改其他的结点。
仍然我们先要来具体分析删除结点这个功能:
- 我们必须知道对哪个链表进行操作,所以表头指针head是必须知道的。
- 一般来说,待删除的结点是由结点的数据确定的。然而我们还要操作待删除结点之前的结点(或指针),以连接前后两段链表。之前所写的search函数只能找到待删除的结点,却无法找到这个结点的前趋结点。所以,我们只好放弃search函数,另起炉灶。
- 令pGuard指针为待删除结点的前趋结点指针。
- 由于要对待删除结点作内存释放,需要有一个指针p指向待删除结点。
- 如果待删除结点为头结点,则我们要操作表头head,作为特殊情况处理。
- 在删除结点的过程中,仍然要始终保持所有的结点都在我们的控制范围内,保证链表的完整性。为了达到这一点,我们还是采用先连后断的方式:先把待删除结点的前趋结点和它的后继结点连接,再把待删除结点与它的后继结点断开,并释放其空间。如下图9.6.4所示。
- 如果链表没有结点或找不到待删除结点,则给出提示信息。
由于delete是C++中的保留字,我们无法用它作为函数名,所以只好用Delete代替(C++是大小写敏感的,Delete和delete是不同的)。都准备好了,我们就可以开始写函数了:(程序9.6.4)
void Delete(node * &head,char keyWord)//可能要操作表头指针,所以head是引用 { if (head!=NULL)//如果链表没有结点,就直接输出提示 { node *p; node *pGuard=head;//初始化pGuard指针 if (head->data==keyWord)//如果头结点数据符合关键字 { p=head;//头结点是待删除结点 head=head->next;//先连 delete p;//后断 cout <<"The deleted node is " <<keyWord <<endl; return;//结束函数运行 } else//否则 { while (pGuard->next!=NULL)//当pGuard没有达到表尾 { if (pGuard->next->data==keyWord)//如果pGuard后继结点数据符合关键字 { p=pGuard->next;//pGuard后继结点是待删除结点 pGuard->next=p->next;//先连 delete p;//后断 cout <<"The deleted node is " <<keyWord <<endl; return;//结束函数运行 } pGuard=pGuard->next;//pGuard指针向后移动 } } } cout <<"The keyword node is not found or the link list is empty!" <<endl;//输出提示信息 }
9.清除链表
链表的结点也是动态分配的,如果在程序结束之前不释放内存,就会造成内存泄漏。因此,编写一个清除链表的函数就显得相当有必要。我们先来分析一下清除这个功能:
- 我们必须知道对哪个链表进行操作,所以表头指针head是必须知道的,并且清除整个链表后要将其改为NULL。
- 类似于删除结点,我们还需要一个指针p来指向待删除结点。
- 类似于删除表头结点的操作,我们仍然要先连后断:先把表头指向头结点的后继,再删除头结点。
下面我们来写一下这个函数:(程序9.6.5)
void destroy(node * &head) { node *p; while (head!=NULL)//当还有头结点存在时 { p=head;//头结点是待删除结点 head=head->next;//先连 delete p;//后断 } cout <<"The link list has been deleted!" <<endl; }至此,我们已经学习了链表的所有基本操作。下面来介绍一下数组存储和链表存储各自的优缺点。
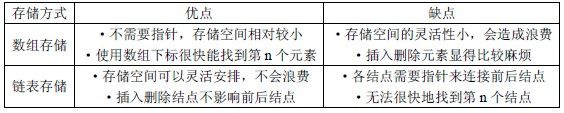
虽然很多初学者都认为链表非常难以理解,但是只要掌握了插入删除结点时“先连后断”的原则和如何遍历整个链表,所有的问题就迎刃而解了。