最简单的网络爬虫(用到了htmlparser,httpClient)
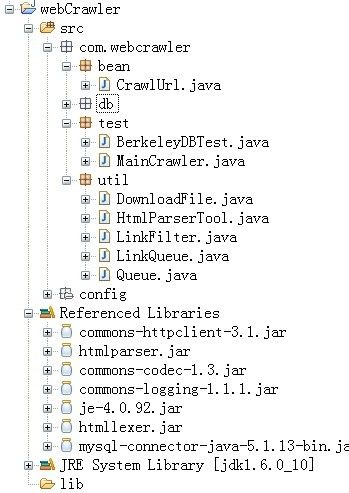
目录结构
第一步:
com.webcrawler.util.Queue.java
package com.webcrawler.util; import java.util.LinkedList; @SuppressWarnings("unchecked") public class Queue { private LinkedList queue = new LinkedList(); public void enQueue(Object t) { queue.add(t); } public Object deQueue() { return queue.removeFirst(); } public boolean contains(Object t) { return queue.contains(t); } public boolean empty() { return queue.isEmpty(); } }
第二步:
com.webcrawler.util.LinkQueue.java
package com.webcrawler.util; import java.util.HashSet; import java.util.Set; public class LinkQueue { @SuppressWarnings("unchecked") private static Set visitedUrl = new HashSet(); private static Queue unVisitedUrl = new Queue(); public static Queue getUnVisitedUrl() { return unVisitedUrl; } public static void addVisitedUrl(String url) { visitedUrl.remove(url); } public static void removeVisitedUrl(String url) { visitedUrl.remove(url); } public static Object unVisitedUrlDeQueue() { return unVisitedUrl.deQueue(); } public static void addUnvisitedUrl(String url) { if(url != null && !url.trim().equals("") && !visitedUrl.contains(url) && !unVisitedUrl.contains(url)) { unVisitedUrl.enQueue(url); } } public static int getVisitedUrlNum() { return visitedUrl.size(); } public static boolean unVisitedUrlsEmpty() { return unVisitedUrl.empty(); } }
第三步:
com.webcrawler.util.LinkFilter.java
package com.webcrawler.util; public interface LinkFilter { public boolean accept(String url); }
第四步:
com.webcrawler.util.HtmlParserTool.java
package com.webcrawler.util; import java.util.HashSet; import java.util.Set; import org.htmlparser.Node; import org.htmlparser.NodeFilter; import org.htmlparser.Parser; import org.htmlparser.filters.NodeClassFilter; import org.htmlparser.filters.OrFilter; import org.htmlparser.tags.LinkTag; import org.htmlparser.util.NodeList; import org.htmlparser.util.ParserException; public class HtmlParserTool { @SuppressWarnings("serial") public static Set<String> extracLinks(String url, LinkFilter filter) { Set<String> links = new HashSet<String> (); try { Parser parser = new Parser(url); parser.setEncoding("UTF-8"); NodeFilter frameFilter = new NodeFilter() { @Override public boolean accept(Node node) { if(node.getText().startsWith("frame src=")) { return true; } return false; } }; OrFilter linkFilter = new OrFilter(new NodeClassFilter(LinkTag.class), frameFilter); NodeList list = parser.extractAllNodesThatMatch(linkFilter); for(int i=0; i<list.size(); i++) { Node tag = list.elementAt(i); if( tag instanceof LinkTag) { LinkTag link = (LinkTag) tag; String linkUrl = link.getLink(); if(filter.accept(url)) { links.add(linkUrl); } else { String frame = tag.getText(); int start = frame.indexOf("src="); if( start != -1) { frame = frame.substring(start); } int end = frame.indexOf(" "); String frameUrl = ""; if(end == -1) { end = frame.indexOf(">"); if(end-1 > 5) { frameUrl = frame.substring(5, end - 1); } } if(filter.accept(frameUrl)) { links.add(frameUrl); } } } } } catch (ParserException e) { e.printStackTrace(); } return links; } }
第五步:
com.webcrawler.util.DownloadFile.java
package com.webcrawler.util; import java.io.DataOutputStream; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import org.apache.commons.httpclient.DefaultHttpMethodRetryHandler; import org.apache.commons.httpclient.HttpClient; import org.apache.commons.httpclient.HttpException; import org.apache.commons.httpclient.HttpStatus; import org.apache.commons.httpclient.methods.GetMethod; import org.apache.commons.httpclient.params.HttpMethodParams; public class DownloadFile { public String getFileNameByUrl(String url, String contentType) { url = url.substring(7); if(contentType.indexOf("html") != -1) { url = url.replaceAll("[//?/:*|<>/"]", "_") + ".html"; return url; } else { return url.replaceAll("[//?/:*|<>/"]","_") + "." + contentType.substring(contentType.lastIndexOf("/") + 1); } } private void saveToLocal(byte[] data, String filePath) { try { DataOutputStream out = new DataOutputStream(new FileOutputStream(new File(filePath))); for(int i=0; i<data.length; i++) { out.write(data[i]); } out.flush(); out.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } public String downLoadFile(String url) { String filePath = null; HttpClient httpClient = new HttpClient(); //set time out httpClient.getHttpConnectionManager() .getParams() .setConnectionTimeout(5000); GetMethod getMethod = new GetMethod(url); getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000); getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler()); //retry //execute HTTP GET request try { getMethod.addRequestHeader("Content-Type", "text/html; charset=UTF-8"); int statusCode = httpClient.executeMethod(getMethod); if(statusCode != HttpStatus.SC_OK) { System.out.println("Method failed:" + getMethod.getStatusLine()); filePath = null; } //execute HTTP content byte[] responseBody = getMethod.getResponseBody(); File file = new File("temp"); if(!file.exists()) { file.mkdir(); } filePath = "temp//" + getFileNameByUrl(url, getMethod.getResponseHeader("Content-Type").getValue()); System.out.println("---------"+url+"-------"); saveToLocal(responseBody, filePath); } catch (HttpException e) { System.out.println("Please check you provided http address!"); } catch (IOException e) { } catch (RuntimeException e) { System.out.println("error"); }finally { getMethod.releaseConnection(); } return filePath; } }
第六步:
com.webcrawler.test.MainCrawler.java
package com.webcrawler.test; import java.util.Set; import com.webcrawler.util.DownloadFile; import com.webcrawler.util.HtmlParserTool; import com.webcrawler.util.LinkFilter; import com.webcrawler.util.LinkQueue; public class MainCrawler { private void initCrawlerWithSeeds(String[] seeds) { for(int i=0; i<seeds.length; i++) { LinkQueue.addUnvisitedUrl(seeds[i]); } } public void crawling(String[] seeds) { LinkFilter filter = new LinkFilter() { @Override public boolean accept(String url) { if(url.startsWith("http://www.zcib.edu.cn")) { return true; } return false; } }; initCrawlerWithSeeds(seeds); while(!LinkQueue.unVisitedUrlsEmpty() && LinkQueue.getVisitedUrlNum()<=1000) { String visitUrl = (String) LinkQueue.unVisitedUrlDeQueue(); if(visitUrl == null) { continue; } DownloadFile downLoader = new DownloadFile(); downLoader.downLoadFile(visitUrl); LinkQueue.addVisitedUrl(visitUrl); Set<String> links = HtmlParserTool.extracLinks(visitUrl, filter); for(String link:links) { LinkQueue.addUnvisitedUrl(link); } } } public static void main(String[] args) { MainCrawler crawler = new MainCrawler(); crawler.crawling(new String[]{"http://www.zcib.edu.cn"}); } }
That's all.
所有jar包在
http://download.csdn.net/source/3136181