用scrapy框架爬取js交互式表格数据
0. 问题背景
前段时间,我有个朋友让我帮他从网页上自动下载些表格数据。像这个网站http://wszw.hzs.mofcom.gov.cn/fecp/fem/corp/fem_cert_stat_view_list.jsp的表格数据。其难点在于每页的url地址是不变的,有一个交互的过程,需要用户选择第几页,网页才返回数据。要是没有这个过程,用普通的wget也可以解决。
1. scrapy是一个很好的爬虫框架
我花了点时间研究scrapy怎样爬取数据,我后来发现有人已经在github上做过类似的项目,像这个http://rnp.fas.gov.ru/Default.aspx网站的表格数据,它由AmbientLighter已经实现,源代码见rnp项目。pluskid同学有篇博文介绍scrapy的,我觉得很好,链接。
2. 找到相应XPath
基于以上基础,打开Firefox的Firebug插件,找到相应的表单项,如下:
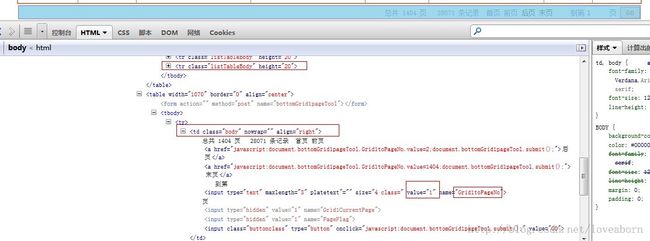
找到Grid1toPageNo这行,里面有个value变量,这样的话,每次向网页提交requests表单的时候修改这个数据就行了。
3. Python代码实现
这个代码可以在我的github的spaceweb项目里找到,链接 ,这里我把下载的每个网页内容保存在一个文件里名字为result.txt.x 要运行它,你得先安装scrapy,进入项目目录下,再使用命令 scrapy crawl table
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
from spaceweb.items import SpacewebItem
from scrapy.http import Request
from scrapy.http import FormRequest
from scrapy.utils.response import get_base_url
class TableSpider(BaseSpider):
name="table"
allowed_domains = ["wszw.hzs.mofcom.gov.cn"]
start_urls = [
"http://wszw.hzs.mofcom.gov.cn/fecp/fem/corp/fem_cert_stat_view_list.jsp"
]
def parse(self, response):
response = response.replace(body=response.body.replace("disabled",""))
hxs=HtmlXPathSelector(response)
requests = []
start_index = 2
end_index = 4 # total page number is 1367
if start_index < end_index: # request next pages
el = hxs.select('//input[@name="Grid1toPageNo"]/@value')[0]
val=int(el.extract()) # the current page number
newval=val+1
print "------------- the current page is %d ------------------" % val
print "(val=%d)---(newval=%d)" % (val,newval)
if newval <= end_index:
requests.append(FormRequest.from_response(response, \
formdata={"Grid1toPageNo":str(newval)}, \
dont_click=True,callback=self.parse))
#requests.append(FormRequest.from_response(response, \
# formdata={"CHECK_DTE":"2006-09-14"}, \
# dont_click=True,callback=self.parse))
#requests.append(FormRequest.from_response(response, \
# formdata={"Grid1toPageNo":newval}, \
# dont_click=True))
for request in requests:
yield request
sites=hxs.select('//td[contains(@class,"listTableBodyTD")]/div')
items = []
for site in sites:
item = SpacewebItem()
item['desc'] = site.select('text()').extract()
items.append(item) # items means each page's content
dataSaveName="result.txt."+str(val) # save the data to this file
file_each=open(dataSaveName, 'w');
for gis in items:
if len(gis['desc']) > 0:
file_each.write(gis['desc'][0].encode('utf8'))
file_each.write(" # ")
else:
file_each.write('\n') # next line
file_each.close()
start_index=start_index + 1
print "------------ finished page %d, left %d pages ------------" \
% (val, end_index-val)
SPIDER = TableSpider()

5. 参考链接
http://scrapy.readthedocs.org/en/latest/topics/request-response.html#passing-additional-data-to-callback-functions
http://doc.scrapy.org/en/latest/faq.html#what-s-this-huge-cryptic-viewstate-parameter-used-in-some-forms
http://doc.scrapy.org/en/latest/topics/request-response.html
https://github.com/AmbientLighter/rpn-fas/blob/master/fas/spiders/rnp.py
http://stackoverflow.com/questions/2454998/how-to-use-crawlspider-from-scrapy-to-click-a-link-with-javascript-onclick
http://www.harman-clarke.co.uk/answers/javascript-links-in-scrapy.php
http://wszw.hzs.mofcom.gov.cn/fecp/fem/corp/fem_cert_stat_view_list.jsp
http://rnp.fas.gov.ru/Default.aspx