Linux网络协议栈(四)——链路层(1)
原文地址:http://www.cnblogs.com/hustcat/archive/2009/09/26/1574371.html
1、接收帧
当网络适配器接收到数据帧时,就会触发一个中断,中断处理程序执行一些需要及时处理的任务,然后在下半部进行其它可以延迟的处理。中断处理程序主要进行以下一些操作:(1) 分配sk_buff数据结构,并将接收到的数据帧从网络适配器I/O端口拷贝到sk_buff缓冲区中;
(2) 从数据帧中提取出一些信息,并设置sk_buff相应的参数,这些参数将被上层的网络协议使用,例如skb->protocol;
(3) 通过软中断NET_RX_SOFTIRQ通知内核接收到新的数据帧。
内核2.5中引入一组新的API来处理接收的数据帧,即NAPI。所以,当网络适配器接收到数据帧时,驱动有两种方式通知内核:(1)通过以前的函数netif_rx;(2)通过NAPI机制,但是只有很少的驱动使用它。
1.1、softnet_data数据结构
struct softnet_data
{
int throttle;
int cng_level;
int avg_blog;
struct sk_buff_head input_pkt_queue;
struct list_head poll_list;
struct net_device * output_queue;
struct sk_buff * completion_queue;
struct net_device backlog_dev; /* Sorry. 8) */
};
throttle、avg_blog和cng_level
这三个参数主要用于阻塞管理(congestion management)。throttle非0时,表示CPU负荷过载,它的值取决于input_pkt_queue,当throttle设置时,CPU接收到的所有数据帧都被丢弃。avg_blog表示输入队列input_pkt_queue的平均长度,它的范围从0到netdev_max_backlog(最大值),它用来计算cng_level。cng_level表示阻塞的程度. avg_blog 和 cng_level与CPU处理的input_pkt_queue相关联,仅用于non_NAPI设备。
struct net_device *output_queue;
struct sk_buff *completion_queue;
这两个域用于发送数据。
struct sk_buff_head input_pkt_queue;
struct list_head poll_list;
struct net_device backlog_dev;
这三个域用于接收数据,其中input_pkt_queue与backlog_dev仅用于non-NAPI的 NIC,input_pkt_queue是接收到的数据队列头,它用于netif_rx()中,并最终由虚拟的poll函数 process_backlog()处理这个SKB队列。
poll_list则是有数据包等待处理的NIC设备队列。对于non-NAPI驱动来说,它始终是backlog_dev。
Softnet_data的初始化:
每个CPU的softnet_data是在net_dev_init中初始化的,代码如下:
struct softnet_data * queue;
queue = & per_cpu(softnet_data,i);
skb_queue_head_init( & queue -> input_pkt_queue);
queue -> throttle = 0 ;
queue -> cng_level = 0 ;
queue -> avg_blog = 10 ; /* arbitrary non-zero */
queue -> completion_queue = NULL;
INIT_LIST_HEAD( & queue -> poll_list);
set_bit(_ _LINK_STATE_START, & queue -> backlog_dev.state);
queue -> backlog_dev.weight = weight_p;
queue -> backlog_dev.poll = process_backlog;
atomic_set( & queue -> backlog_dev.refcnt, 1 );
}
来看看vortex_rx是怎么调用netif_rx的,大部分的网络设备驱动使用方式与其相似:
{
// …
struct sk_buff * skb;
skb = dev_alloc_skb(pkt_len + 5 ); // 分配缓冲区
if (skb != NULL) {
skb -> dev = dev; // 设置接收包的网络设备
// 将data和tail指针下移2个字节,使得IP头在缓冲区存储时可以16字节的边界上对齐
skb_reserve(skb, 2 ); /* Align IP on 16 byte boundaries */
// 将数据帧从I/O端口拷贝到sk_buff缓冲区
skb -> protocol = eth_type_trans(skb, dev);
netif_rx(skb);
dev -> last_rx = jiffies; // 接收到数据的时间
vp -> stats.rx_packets ++ ;
// …
}
}
netif_rx( )函数
netif_rx通常在驱动的中断处理程序(严格意义来说,应该是中断服务例程,ISR)中被调用,但是也有例外,那就是回环设备。
int netif_rx(struct sk_buff *skb)
{
int this_cpu;
struct softnet_data *queue;
unsigned long flags;
#ifdef CONFIG_NETPOLL
if (skb->dev->netpoll_rx && netpoll_rx(skb)) {
kfree_skb(skb);
return NET_RX_DROP;
}
#endif
//设置接收到的帧的时间,注意与dev->last_rx相区别;前者是针对sb_buff,后者是
//针对net_device。
if (!skb->stamp.tv_sec)
net_timestamp(&skb->stamp);
/*
* The code is rearranged so that the path is the most
* short when CPU is congested, but is still operating.
*/
//关闭中断
local_irq_save(flags);
this_cpu = smp_processor_id();
//取得当前CPU的输入队列
queue = &__get_cpu_var(softnet_data);
//更新当前CPU接收到的帧的数量,包括接收的和丢弃的
__get_cpu_var(netdev_rx_stat).total++;
//每个CPU输入队列的最大长度为300,如果超过,则丢弃该数据帧
if (queue->input_pkt_queue.qlen <= netdev_max_backlog) {
if (queue->input_pkt_queue.qlen) {
if (queue->throttle)
goto drop;
enqueue: //增加设备的引用计数,防止处理sb_buff时,设备被移除;
//dev_put减引用计数,它在net_rx_action被调用
dev_hold(skb->dev);
//将sb_buff加入到当前CPU的输入队列
__skb_queue_tail(&queue->input_pkt_queue, skb);
#ifndef OFFLINE_SAMPLE
get_sample_stats(this_cpu);
#endif
local_irq_restore(flags);
return queue->cng_level;
}
if (queue->throttle)
queue->throttle = 0;
//调度NET_RX_SOFTIRQ软中断,仅当新的sb_buff加入空队列时才调用.
netif_rx_schedule(&queue->backlog_dev);
goto enqueue;
}
//如果CPU输入队列已满,表明CPU进入throttle状态
if (!queue->throttle) {
queue->throttle = 1;
__get_cpu_var(netdev_rx_stat).throttled++;
}
drop:
//更新当前CPU的丢弃的帧数
__get_cpu_var(netdev_rx_stat).dropped++;
//恢复寄存器状态
local_irq_restore(flags);
kfree_skb(skb);
return NET_RX_DROP;
}
1.3、NAPI方式
net_device中与NAPI相关的字段:
poll
从设备的输入队列取缓冲区的虚拟函数。对于NAPI,输入队列是私有的;对于NON_API设备,输入队列为softnet_data->input_pkt_queue。
poll_list
输入队列有新的数据帧需要处理的设备的链表,这些设备此时处于polling状态,表头为softnet_data->poll_list。位于链表中的设备关闭中断,正被内核查询。
quota
weight
quota表示poll每次可以从输入队列中取的最大缓冲区数。weight 成员描述接口的相对重要性:当资源紧张时,有多少流量可以从接口收到。如何设置 weight 参数没有严格的规则;依照惯例, 10 MBps 以太网接口设置 weight 为 16, 而快一些的接口使用 64. 你不能设置 weight 为一个超过你的接口能够存储的报文数目的值。quota值以weight为基础进行更新。
使用NAPI:
//drivers/net/e100.c
static irqreturn_t e100_intr(int irq, void *dev_id, struct pt_regs *regs)
{
struct net_device *netdev = dev_id;
struct nic *nic = netdev_priv(netdev);
//…
e100_disable_irq(nic);
netif_rx_schedule(netdev);
return IRQ_HANDLED;
}
netif_rx_schedule函数
//include/linux/netdevice.h
static inline void netif_rx_schedule(struct net_device *dev)
{
if (netif_rx_schedule_prep(dev))
__netif_rx_schedule(dev);
}
//检查设备已经运行且软中断没有被调度
static inline int netif_rx_schedule_prep(struct net_device *dev)
{
return netif_running(dev) &&
!test_and_set_bit(__LINK_STATE_RX_SCHED, &dev->state);
}
static inline void __netif_rx_schedule(struct net_device *dev)
{
unsigned long flags;
local_irq_save(flags);
//增加设备引用计数
dev_hold(dev);
//将dev加入到poll_list中
list_add_tail(&dev->poll_list, &__get_cpu_var(softnet_data).poll_list);
if (dev->quota < 0)
dev->quota += dev->weight;
else
dev->quota = dev->weight;
//挂起软中断
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
local_irq_restore(flags);
}
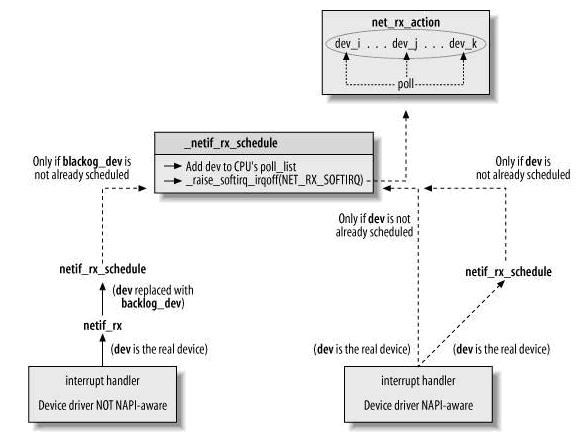
1.4、net_rx_action( )函数
net_rx_action为处理接收数据帧的下半部函数,输入的数据帧在两个地方等待net_rx_action来处理:
(1) CPU的输入队列。这是针对NON-NAPI方式的,它调用netif_rx,将数据帧加入到CPU的输入队列softnet_data->input_pkt_queue。
(2) 设备缓存。对于NAPI方式,poll函数从设备缓存读取数据帧。
static void net_rx_action(struct softirq_action *h)
{
struct softnet_data *queue = &__get_cpu_var(softnet_data);
unsigned long start_time = jiffies;
int budget = netdev_max_backlog;
local_irq_disable();
//处理CPU输入队列中的所有待处理的设备
while (!list_empty(&queue->poll_list)) {
struct net_device *dev;
if (budget <= 0 || jiffies - start_time > 1)
goto softnet_break;
local_irq_enable();
dev = list_entry(queue->poll_list.next,
struct net_device, poll_list);
//调用查询函数处理接收到的数据帧,对于non-api方式为process_backlog;
//对于NAPI,由设备驱动提供相应的poll函数
if (dev->quota <= 0 || dev->poll(dev, &budget)) {
//将设备从poll_list中删除,并将其加到poll_list的尾部
local_irq_disable();
list_del(&dev->poll_list);
list_add_tail(&dev->poll_list, &queue->poll_list);
if (dev->quota < 0)
dev->quota += dev->weight;
else
dev->quota = dev->weight;
} else {
dev_put(dev);//减设备的引用计数
local_irq_disable();
}
}
out:
local_irq_enable();
return;
softnet_break:
__get_cpu_var(netdev_rx_stat).time_squeeze++;
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
goto out;
}
1.5、process_backlog函数
对于non-API方式,poll函数为process_backlog:
static int process_backlog(struct net_device *backlog_dev, int *budget)
{
int work = 0;
int quota = min(backlog_dev->quota, *budget);
struct softnet_data *queue = &__get_cpu_var(softnet_data);
unsigned long start_time = jiffies;
for (;;) {
struct sk_buff *skb;
struct net_device *dev;
local_irq_disable();
skb = __skb_dequeue(&queue->input_pkt_queue);
if (!skb)
goto job_done;
local_irq_enable();
dev = skb->dev;
netif_receive_skb(skb);
dev_put(dev);
work++;
if (work >= quota || jiffies - start_time > 1)
break;
}
backlog_dev->quota -= work;
*budget -= work;
return -1;
job_done:
backlog_dev->quota -= work;
*budget -= work;
list_del(&backlog_dev->poll_list);
smp_mb__before_clear_bit();
netif_poll_enable(backlog_dev);
if (queue->throttle)
queue->throttle = 0;
local_irq_enable();
return 0;
}
1.6 NAPI的poll函数
这种方式下,NIC驱动程序会提供自己的poll函数和私有接收队列。
如intel 8255x系列网卡程序e100,它有在初始化的时候首先分配一个接收队列,而不像以上那种方式在接收到数据帧的时候再为其分配数据空间。这样,NAPI的poll函数在处理接收的时候,它遍历的是自己的私有队列:
//derivers/net/e100.c
static int e100_poll(struct net_device *netdev, int *budget)
{
e100_rx_clean(nic, &work_done, work_to_do);
……
}
static void e100_rx_clean(struct nic *nic, unsigned int *work_done,
unsigned int work_to_do)
{
…….
/* Indicate newly arrived packets */
for(rx = nic->rx_to_clean; rx->skb; rx = nic->rx_to_clean = rx->next) {
int err = e100_rx_indicate(nic, rx, work_done, work_to_do);
if(-EAGAIN == err) {
……
}
……
}
static int e100_rx_indicate(struct nic *nic, struct rx *rx,
unsigned int *work_done, unsigned int work_to_do)
{
struct sk_buff *skb = rx->skb;
struct rfd *rfd = (struct rfd *)skb->data;
rfd_status = le16_to_cpu(rfd->status);
/* Get actual data size */
actual_size = le16_to_cpu(rfd->actual_size) & 0x3FFF;
/* Pull off the RFD and put the actual data (minus eth hdr) */
skb_reserve(skb, sizeof(struct rfd));
skb_put(skb, actual_size);
skb->protocol = eth_type_trans(skb, nic->netdev);
netif_receive_skb(skb);
return 0;
}
1.7 netif_receive_skb函数
netif_receive_skb是链路层接收数据报的最后一站。它根据注册在全局数组ptype_all和ptype_base里的网络层数据报类型,把数据报递交给不同的网络层协议的接收函数(INET域中主要是ip_rcv和arp_rcv)。
//net/core/dev.c
int netif_receive_skb(struct sk_buff *skb)
{
struct packet_type *ptype, *pt_prev;
int ret = NET_RX_DROP;
unsigned short type;
#ifdef CONFIG_NETPOLL
if (skb->dev->netpoll_rx && skb->dev->poll && netpoll_rx(skb)) {
kfree_skb(skb);
return NET_RX_DROP;
}
#endif
if (!skb->stamp.tv_sec)
net_timestamp(&skb->stamp);
//将一组接口作为一个单独的接口对待
skb_bond(skb);
__get_cpu_var(netdev_rx_stat).total++;
skb->h.raw = skb->nh.raw = skb->data;
skb->mac_len = skb->nh.raw - skb->mac.raw;
pt_prev = NULL;
rcu_read_lock();
#ifdef CONFIG_NET_CLS_ACT
if (skb->tc_verd & TC_NCLS) {
skb->tc_verd = CLR_TC_NCLS(skb->tc_verd);
goto ncls;
}
#endif
//ptype_all保存了将要接收所有输入sb_buff的三层协议
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (!ptype->dev || ptype->dev == skb->dev) {
if (pt_prev)
//该函数就是调用协议的接收函数处理该skb包,进入第三层网络层处理
ret = deliver_skb(skb, pt_prev);
pt_prev = ptype;
}
}
#ifdef CONFIG_NET_CLS_ACT
if (pt_prev) {
ret = deliver_skb(skb, pt_prev);
pt_prev = NULL; /* noone else should process this after*/
} else {
skb->tc_verd = SET_TC_OK2MUNGE(skb->tc_verd);
}
ret = ing_filter(skb);
if (ret == TC_ACT_SHOT || (ret == TC_ACT_STOLEN)) {
kfree_skb(skb);
goto out;
}
skb->tc_verd = 0;
ncls:
#endif
handle_diverter(skb);
if (handle_bridge(&skb, &pt_prev, &ret))
goto out;
type = skb->protocol;
//将帧传递给skb->protocol协议处理,ptype_base管理所有的正常的第3层协议
list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type)&15], list) {
if (ptype->type == type &&
(!ptype->dev || ptype->dev == skb->dev)) {
if (pt_prev)
//该函数就是调用协议的接收函数处理该skb包,进入第三层网络层处理
ret = deliver_skb(skb, pt_prev);
pt_prev = ptype;
}
}
if (pt_prev) {
ret = pt_prev->func(skb, skb->dev, pt_prev);
} else {
kfree_skb(skb);
/* Jamal, now you will not able to escape explaining
* me how you were going to use this. :-)
*/
ret = NET_RX_DROP;
}
out:
rcu_read_unlock();
return ret;
}
static __inline__ int deliver_skb(struct sk_buff *skb,
struct packet_type *pt_prev)
{
atomic_inc(&skb->users);
return pt_prev->func(skb, skb->dev, pt_prev);//调用3层协议的处理函数
}