org.w3c.dom(java dom)解析XML文档
位于org.w3c.dom操作XML会比较简单,就是将XML看做是一颗树,DOM就是对这颗树的一个数据结构的描述,但对大型XML文件效果可能会不理想
首先来了解点Java DOM 的 API:
1.解析器工厂类:DocumentBuilderFactory
创建的方法:DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
2.解析器:DocumentBuilder
创建方法:通过解析器工厂类来获得 DocumentBuilder db = dbf.newDocumentBuilder();
3.文档树模型Document
创建方法:a.通过xml文档 Document doc = db.parse("bean.xml"); b.将需要解析的xml文档转化为输入流 InputStream is = new FileInputStream("bean.xml");
Document doc = db.parse(is);
Document对象代表了一个XML文档的模型树,所有的其他Node都以一定的顺序包含在Document对象之内,排列成一个树状结构,以后对XML文档的所有操作都与解析器无关,
直接在这个Document对象上进行操作即可;
包含的方法:



4.节点列表类NodeList
NodeList代表了一个包含一个或者多个Node的列表,根据操作可以将其简化的看做为数组

5.节点类Node
Node对象是DOM中最基本的对象,代表了文档树中的抽象节点。但在实际使用中很少会直接使用Node对象,而是使用Node对象的子对象Element,Attr,Text等
6.元素类Element
是Node类最主要的子对象,在元素中可以包含属性,因而Element中有存取其属性的方法


7.属性类Attr
代表某个元素的属性,虽然Attr继承自Node接口,但因为Attr是包含在Element中的,但并不能将其看做是Element的子对象,因为Attr并不是DOM树的一部分
基本的知识就到此结束,更加具体的大家可以参阅JDK API文档
实战:
1.使用DOM来遍历XML文档中的全部内容并且插入元素:
school.xml文档:
<?xml version = "1.0" encoding = "utf-8"?> <School> <Student> <Name>沈浪</Name> <Num>1006010022</Num> <Classes>信管2</Classes> <Address>浙江杭州3</Address> <Tel>123456</Tel> </Student> <Student> <Name>沈1</Name> <Num>1006010033</Num> <Classes>信管1</Classes> <Address>浙江杭州4</Address> <Tel>234567</Tel> </Student> <Student> <Name>沈2</Name> <Num>1006010044</Num> <Classes>生工2</Classes> <Address>浙江杭州1</Address> <Tel>345678</Tel> </Student> <Student> <Name>沈3</Name> <Num>1006010055</Num> <Classes>电子2</Classes> <Address>浙江杭州2</Address> <Tel>456789</Tel> </Student> </School>
DomDemo.java
package xidian.sl.dom; import java.io.FileOutputStream; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import org.apache.crimson.tree.XmlDocument; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.NodeList; public class DomDemo { /** * 遍历xml文档 * */ public static void queryXml(){ try{ //得到DOM解析器的工厂实例 DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance(); //从DOM工厂中获得DOM解析器 DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder(); //把要解析的xml文档读入DOM解析器 Document doc = dbBuilder.parse("src/xidian/sl/dom/school.xml"); System.out.println("处理该文档的DomImplementation对象 = "+ doc.getImplementation()); //得到文档名称为Student的元素的节点列表 NodeList nList = doc.getElementsByTagName("Student"); //遍历该集合,显示结合中的元素及其子元素的名字 for(int i = 0; i< nList.getLength() ; i ++){ Element node = (Element)nList.item(i); System.out.println("Name: "+ node.getElementsByTagName("Name").item(0).getFirstChild().getNodeValue()); System.out.println("Num: "+ node.getElementsByTagName("Num").item(0).getFirstChild().getNodeValue()); System.out.println("Classes: "+ node.getElementsByTagName("Classes").item(0).getFirstChild().getNodeValue()); System.out.println("Address: "+ node.getElementsByTagName("Address").item(0).getFirstChild().getNodeValue()); System.out.println("Tel: "+ node.getElementsByTagName("Tel").item(0).getFirstChild().getNodeValue()); } }catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } /** * 向已存在的xml文件中插入元素 * */ public static void insertXml(){ Element school = null; Element student = null; Element name = null; Element num = null; Element classes = null; Element address = null; Element tel = null; try{ //得到DOM解析器的工厂实例 DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance(); //从DOM工厂中获得DOM解析器 DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder(); //把要解析的xml文档读入DOM解析器 Document doc = dbBuilder.parse("src/xidian/sl/dom/school.xml"); //得到文档名称为Student的元素的节点列表 NodeList nList = doc.getElementsByTagName("School"); school = (Element)nList.item(0); //创建名称为Student的元素 student = doc.createElement("Student"); //设置元素Student的属性值为231 student.setAttribute("examId", "23"); //创建名称为Name的元素 name = doc.createElement("Name"); //创建名称为 香香 的文本节点并作为子节点添加到name元素中 name.appendChild(doc.createTextNode("香香")); //将name子元素添加到student中 student.appendChild(name); /** * 下面的元素依次加入即可 * */ num = doc.createElement("Num"); num.appendChild(doc.createTextNode("1006010066")); student.appendChild(num); classes = doc.createElement("Classes"); classes.appendChild(doc.createTextNode("眼视光5")); student.appendChild(classes); address = doc.createElement("Address"); address.appendChild(doc.createTextNode("浙江温州")); student.appendChild(address); tel = doc.createElement("Tel"); tel.appendChild(doc.createTextNode("123890")); student.appendChild(tel); //将student作为子元素添加到树的根节点school school.appendChild(student); //将内存中的文档通过文件流生成insertSchool.xml,XmlDocument位于crison.jar下 ((XmlDocument)doc).write(new FileOutputStream("src/xidian/sl/dom/insertSchool.xml")); System.out.println("成功"); }catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } public static void main(String[] args){ //读取 DomDemo.queryXml(); //插入 DomDemo.insertXml(); } }
运行后结果:

然后到目录下查看生成的xml文件:

打开查看内容:
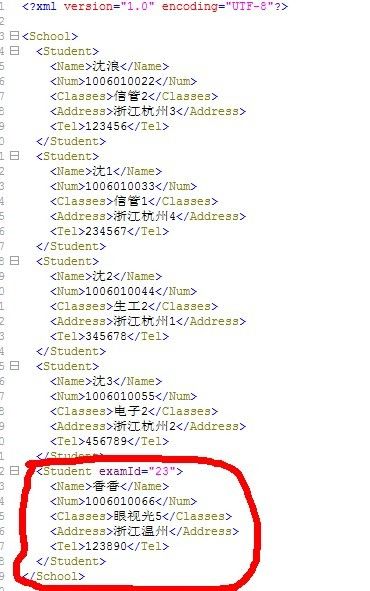
上面添加元素后输出的文件与之前的文件不是同一个文件,如果需要输出到原文件中,那么只要将路径改为原文间路径即可:src/xidian/sl/dom/school.xml
2.创建XML过程与插入过程相似,就是Document需要创建
package xidian.sl.dom; import java.io.FileOutputStream; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import org.apache.crimson.tree.XmlDocument; import org.w3c.dom.Document; import org.w3c.dom.Element; public class CreateNewDom { /** * 创建xml文档 * */ public static void createDom(){ Document doc; Element school,student; Element name = null; Element num = null; Element classes = null; Element address = null; Element tel = null; try{ //得到DOM解析器的工厂实例 DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance(); //从DOM工厂中获得DOM解析器 DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder(); //创建文档树模型对象 doc = dbBuilder.newDocument(); if(doc != null){ //创建school元素 school = doc.createElement("School"); //创建student元素 student = doc.createElement("Student"); //设置元素Student的属性值为231 student.setAttribute("examId", "23"); //创建名称为Name的元素 name = doc.createElement("Name"); //创建名称为 香香 的文本节点并作为子节点添加到name元素中 name.appendChild(doc.createTextNode("香香")); //将name子元素添加到student中 student.appendChild(name); /** * 下面的元素依次加入即可 * */ num = doc.createElement("Num"); num.appendChild(doc.createTextNode("1006010066")); student.appendChild(num); classes = doc.createElement("Classes"); classes.appendChild(doc.createTextNode("眼视光5")); student.appendChild(classes); address = doc.createElement("Address"); address.appendChild(doc.createTextNode("浙江温州")); student.appendChild(address); tel = doc.createElement("Tel"); tel.appendChild(doc.createTextNode("123890")); student.appendChild(tel); //将student作为子元素添加到树的根节点school school.appendChild(student); //添加到文档树中 doc.appendChild(school); //将内存中的文档通过文件流生成insertSchool.xml,XmlDocument位于crison.jar下 ((XmlDocument)doc).write(new FileOutputStream("src/xidian/sl/dom/createSchool.xml")); System.out.println("创建成功"); } }catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } public static void main(String[] args) { CreateNewDom.createDom(); } }
运行结果:

DOM的操作应该还是非常简单明了的,掌握了没哦。