ucinet数据集格式
Datasets数据集下载
http://archive.ics.uci.edu/ml/datasets.html
在ucinet6数据组中有三件重要的事需要记住。
第一,数据是矩阵的集合。不管你把你的数据理解为图像,关系、超图还是其他的,在ucinet6中,你的数据就是矩阵集合。这并不是意味着ucinet不能读取不是矩阵格式的数据,而是说在程序系统中,他们都是被看作为矩阵的。网络分析人员一般把他们的数据理解为图,图就是一系列的节点和一系列连接这些点的线。图的信息可以用邻接矩阵表示,在邻接矩阵中给定元素X(i,j)的值为1代表节点i和j是连接着的,0代表这两者不是连接着的。
以下是用矩阵代表网络的一个示例:
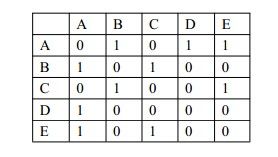
在这个网络中,参与者A和参与者B,D和E有联系,但和C以及他自己没有联系。参与者B和参与者A,C有联系,参与者C和参与者B,E有联系,参与者D只和A有联系,参与者E和参与者A,C有联系。
有向图是一系列点和连接这些点的圆弧(或者是箭头、有头尾的线)的集合。他们被用来表示节点间的不必是相互的关系,比如“爱上”或者“是……的老板”。有向图中的信息可以被记录为单模邻接矩阵(并不必须是对称的),在其中,如果i被连接到j则X(i,j)=1,否则X(i,j)=0.注意X(i,j)可以等于X(j,i),但这不是必须得。
赋值图可以用一个长方形单模矩阵表示,在其中X(i,j)给出了从i到j的连接的值,可以代表关系的强度,道路的长度,状态转换的可能性,联系的频繁性等。
超图是一系列节点的子集的集合。子集在概念上就像可能有两个末端的边界/连接。在超图可以用2模矩阵表示,在其中,假如i在子网j中,则Y(i,j)=1,否则Y(i,j)=0.。Ucinet中包含的矩阵可以有任何形状或者尺寸,而且并非都代表网络。比如,以下三个数字集合就都是矩阵。
Matrix#1: 1 3 2 5 1 5 7 2 1 2 7 2 2 4 5 2 9 6 5 1 Matrix#2: 1 3 8 9 2 3 5 1.7 Matrix#3: 3.1415
注意第二个矩阵有8列1行。第3个矩阵是1行1列。古怪的形状并不是问题。重要的是每一行包括了同样数目的列数,反之亦然。
Ucinet数据表的一个重要特征是他们可能包括了一个以上的矩阵,虽然每个矩阵的行列必然反映同一个物体。这使得你可以把一系列有关的网络数据放在同一个文件中。比如,你可能有一系列的家庭作为节点,并如此度量家庭间的关系:“嫁给了……中的一人”和“与……中的一人做生意”。这对于应用有一个或多个社会关系作为输入的网络技术非有用,比如大部分的位置方法(positionalmethods),(比如CONCOR,REGE).甚至把多种关系应用在没有多种关系的技术里面也会很有用,比如中心法(centralitymeasures)。在ucinet中,无论什么时候有可能,一个引入使用多关系
无效的技术的程序会基于每种关系挨个运行。比如在包含数百个随机网络的数据组中运行中心法时,程序会为文件中的每个网络计算和保存方法。结果可用于统计分析。
使用多矩阵数据组的另一种方法被引入到Tools>MatrixAlgebra(矩阵代数学)程序中。在此,程序把多矩阵数据组视为单个由行列级组成的3路矩阵,并允许用户同时在三个维度运行操作。
第二件重要的事情是理解ucinet数据组并不是文本文件。因此你不能使用文字处理软件来修改。只有ucinet(以及其他来自于AnalyticTechnologies的软件)可以读写他们。这会有所不便,但是这可以提升性能。当然,ucinet也提供了把文本文件转换为ucinet数据组的方法(参见Import命令),反之亦然(参见Export)。在这个方面ucinet和SYSTAT,SAS,SPSS,GRADAP以及其他致命的分析软件想象。
第三件重要的事是单个ucinet数据组实际上由两个文件组成。一个(后缀名为.##D)包括了实际数据,另一个(后缀名.##H)包含了数据的信息。当参考ucinet数据组的时候,你只能参考##H文件(或者同时只是忽略后缀名)。你应该正确使用文件名:像“sampson”或“sampson.##h”。文件名中可以包括空格,可以数字符号打头。然而,有时候你需要使用括号扩住有空格的文件名。UCINETIV 数据组在ucinet6.0中兼容并且无需转换。
导入数据
在使用ucinet做任何分析之前,必须先创建ucinet数据组。典型地,网络数据从问卷调查中或者书籍和采访中的数据表中来。在这两种情况下材料载体是纸张,你需要将对应数据输入到计算机文件中。最好最通用的方法是使用文件编辑器或者你喜欢的文字处理软件把数据保存为ASCII文件。
在本章中将会介绍输入数据的几种格式。一旦数据保存在了计算机磁盘中,你可以使用Data>Import/Export>Import命令来将这些数据装换为ucinet6.0的数据组。使用过SYSTAT等统计软件的用户对这一部肯定不陌生。在SYSTAT中,你可以使用DATA命令来读取ASCII文件、创建SYSTAT系统文件,读取SPSS和SAS程序文件,虽然他们不需要像SYSTAT和UCINET6.0一样需要永久的系统文件。
Import可以处理许多格式的ASCII数据。最普遍RAW,DL,EXCEL和UCINET3.0(ucinet6.0和UCINETIV 使用相同的数据格式所以不需要导入)。RAW文件只包含数字,比如一个由问题答案数字编码组成的变量矩阵。DL文件包括了和RAW一样的文件,另外还包括了数据的信息,比如行列的数目,变量的名字,研究的名字,以及其他。Ucinet3文件与DL文件相似,但是在数据信息方面有更多的限制。EXCEL则是标准的EXCEL数据表文件,这些文件格式将会在下面的部分详细讨论。
如果你通过抓取输入数据,我们强烈建议你是用DL格式(你可以在任何时候通过Export把数据输出为其他格式。)这种格式在接受数据方面是最可靠的。
无论你导入的文件格式是怎样的,输出总是一样的:即一个可以被应用于任何数值程序输入的ucinet6.0数据组。但是,必须注意,在保存数据方面你只有几种选择:Byte(字节),Smallint(短整型),和Real(实数). 当从ASCII文件中导入数据时,可以选择三种之一。除非你有很大的数据量,否则默认的Real(实数)应该是最好的选择。
Real(实数)数据格式是最强大的,可以包括从-1E36t到+1E36当中的值,他们也能包含缺失值,这些值在内部被存为1E38.,Real型的缺点是每个值需要4个字节存储,这会使得文件偏大,比如,一个150*150的矩阵需要176kb的磁盘空间(译者说,现在看来好小)。
Smallint(短整型)的每个值需要两个字节的存储空间,但只能代表从-32000到+32000之间的数,不允许缺失值。
Byte(比特)型是最节省的,每个值只需要1个字节,可以表示0到255之间的数,没有缺失值。
如果你需要缺失值,则必须使用Real型,当然,大部分网络分析技术不允许缺失值,只有少数ucinet子程序知道如何处理他们,不支持缺失值的程序自动把其转化为0或者其他合理值。
在选择数据型的时候,了解选型对存储空间的影响很重要,但是这对程序处理时所需要的内存空间并没有影响。不管数据时如何存储在磁盘中的,类似于MIDS之类的用来处理Real型数值的程序都是将其看做Real型。类似的,像Clique之类只处理整数的程序会在读入内存中时自动将Real型的数据转换为整数。关于缺失值需要注意一点:所有的大于1E37的值都被认为是缺失值,包括在ASCII数据文件中的非数字符号,比如,以下的矩阵中存在3个缺失值(1E38/na/a3??):
0 9.7 1E38 . 16. 0 3.1 na 18.1 1e9 0 -1.2 a3 12 .013 0
与SYSTAT不同,ucinet6.0把一个单独的句号(loneperiod)看做0,而不是缺失,如果你要导入包含了缺失值的SYSTAT数据,你应该用文本编辑器改变所有的单独句号,比如使用'NA'.
3.1RawFiletype
Raw文件全都由数字构成,以矩阵形式输入。以下就是一个raw文件的例子:0 1 1 0 1 0 1 1 1 1 0 0 0 1 0 0
程序通过读取第一行有几个数来确定有几列,通过计数来确定有多少行。虽然这种文件很方便,但我们并不推荐使用,一个原因是电脑不会检查数据。如果第一行正好丢失了一个数字,程序就读不懂这个文件了,程序会认定该文件中的矩阵列数比实际列数少1,另一个原因是在数据文件中你不能把矩阵中的一行的数据扩散为多个记录。而且,你没法使用标签来辨别节点。
3.2ExcelFiletype
目前ucinet支持的excel版本是4.0,5.0和7.0(office97)(这个东东是指导手册上说的,实际操作……)。如果你想使用其他版本的excel,那你必须在保存数据(SAVEAS)时将他们保存为支持的格式。注意excel最多只支持255列,所以不能被用来建立大型的网络数据表。3.3DLFiletype
典型的DL文件由一系列的数字以及一系列的描述数据的关键词,这些关键词被称为meta-data。当然,DL文件也可以只有meta-data和一个指向存储实际数据所在文件的指针。3.4FullMatrixFormat全矩阵
一个有四个参与者的DL文件如下:dl n=4format=fullmatrix data: 0 1 1 0 1 0 1 1 1 1 0 0 0 1 0 0
关键词“dl”说明这是DL文件类型,必须是文件的第一个词。“n=4”意即矩阵是4行4列,等号也可以换为空格或者逗号,形如"n=4","n 4","n,4"。"format=fullmatrix" 说明数据是以一个普通的矩阵格式输入的(这个值还可以使linkedlist,lowerhalfmatrix等)。因为默认的就是fullmatrix,所以这一短句可以省略。
“data”已经没有其他关于数据的信息了,以下的就是数据。关键词的顺序是很重要的,如果是"dl data: n=4",整个过程就毁了。虽然我们加入了一些其他关键词,但是我们始终要保证dl放在第一位,然后是与矩阵维度有关的关键句,然后是其他关键词句,最后是"data"。
标点的注意事项:一般情况下,冒号表示后面有内容,比如数据集合或者标签集合。
分号或者回车表示短句的结束。
每个数据值之间必须用一个以上的空格或者回车符号间隔开。所有的非数字值,除了单独的句号‘.’(loneperiods),都被认为是缺失值。数据格式中行列不需要相等,只要所有的值按从左到右,从上到下的顺序排列就行,示例如下:
dl n=4 data: 0 1 1 0 1 0 1 1 1 1 0 0 0 1 0 0
3.5RectangularMatrices
长方形矩阵可以参照下面输入dl nr=6,nc=4 data: 0 1 1 0 1 0 1 1 1 1 0 0 0 1 0 0 1 0 1 1 1 1 0 0
"nr=6"说明矩阵有6行,"nc=4"说明矩阵有4列
3.6Labels
DL文件可能也包含参与者标签,比如:dl n=4 labels: Sanders,Skvoretz,S.Smith,T.Smith data: 0 1 1 0 1 0 1 1 1 1 0 0 0 1 0 0
"labels:"表示以下四项是行列标签,标签名至多可有18个字符(当longlabels 选项为off的情况下)或者255个字符(当longlabels选项为on的时候),标签名可以由空格,逗号或者回车(或者两者一起使用)来分开。 标签内不能存在空格,除非你用引号将其包住,比如"Tom Smith"。
"lable"这个词之后必须跟有冒号。
标签可以被分开为行标和列标,事实上,当矩阵不是方形的时候这是必须的,比如:
dl nr=6,nc=4 col labels: hook,canyon,silence,rosencrantz data: 0 1 1 0 1 0 1 1 1 1 0 0 0 1 0 0 1 0 1 1 1 1 0 0
另一种输入标签的方法是将其当做数据矩阵的一部分:
dl nr=6,nc=4 row label sembedded col label sembedded data: Dian Norm Coach Sam Mon 0 1 1 0 Tue 1 0 1 1 Wed 1 1 0 0 Thu 0 1 0 0 Fri 1 0 1 1 Sat 1 1 0 0
"row labels embedded" 和"column labels embedded" 说明行标和列标都嵌入在数据中,也可以简单用"labels embedded" 来表示行列表企鹅都在数据中。
3.7MultipleMatrices
有时在一个数据文件中存放几个相关的矩阵会比较方便。比如,我们可以度量给定的 一系列参与者的多种社会关系,以下展示如何操作:
d ln = 4, nm = 2 labels: GroupA,GroupB,GroupC,GroupD matrix labels: Marriage,Business data: 0 1 0 1 1 0 0 0 0 0 1 0 1 0 0 1 0 1 1 1 1 0 0 0 1 0 0 1 1 0 1 0
"nm=2" 说明文件中包含了两个矩阵。"matrix labels:"说明下两个词("marriage" 和"business")是每个矩阵的标签,大致说明了每个矩阵度量的社会联系。
3.8ExternalDataFile
有时将数据从DL的描述文件中分开出来会显得方便,这可以使得其他程序也可以读取 数据文件(比如SYSTAT,STRUCTURE,和NEGOPY)以及ucinet,以下是示例:dl n=16 labels: ACCIAIUOL,ALBIZZI,BARBADORI,BISCHERI,CASTELLAN,GINORI GUADAGNI,LAMBERTES,MEDICI,PAZZI,PERUZZI,PUCCI,RIDOLFI, SALVIATI,STROZZI,TORNABUON datafile C:\DATA\PADGM.DAT
"datafile=c:\data\padgm.dat"说明了包含实际数据的文件,该文件只能包含数据。使用datafile命令的缺点在于必须跟踪众多的文件。
当使用一个单独的数据文件时,ucinet检查第一行,查看是否存在NEGOPY和STRUCTURE等所要求的FORTRAN格式声明。假如存在,ucinet将从第二行开始读取,否则,就从第一行开始读取,这使得你可以在使用STRUCTURE和NEGOPY文件时中途改换为ucinet文件,只需确保文件中的每个值之间都有一个以上的空格。
3.9DiagonalAbsent
默认情况下,程序认为数据有一整个完整的矩阵组成,技术上我们称之为"full matrix format" ,可以通过如下所示方法明确之:
dl n=4 format=fullmatrix data: 0 1 1 0 1 0 1 1 1 1 0 0 0 1 0 0
在方形矩阵的情况下,省略一些值有时候显得更为方便,比如,可以省略掉对角线。
dl n=4 diagonal=absent labels: Sanders,Skvoretz S.Smith,T.Smith data: 1 1 0 1 1 1 1 1 0 0 1 0
程序会自动以缺失值编码填入空缺的位置中。
3.10LowerhalfandUpperhalfMatrices
一种做法是只输入对称矩阵的下半部分:d ln=4 format=lowerhalf diagonal=absent labels: Sanders,Skvoretz S.Smith,T.Smith data: 1 1 1 0 1 0
Ucinet会自动把上半部分补齐,并以缺失值填入对角线。同样,也可以输入对症矩阵的上半部分以关键词"upperhalf" 代替"lowerhalf"即可。注意如果"diagonal absent" 语句被省略了,程序展示出缺失值(expect a diagonal value tobe present.)
d ln=4
format=lowerhalf
labels:
Sanders,Skvoretz
S.Smith,T.Smith
data:
2
1 2
1 1 2
0 1 0 2
3.11BlockmatrixFormat
另一种在建立模型矩阵时很有用的格式是“blockmatrix”(分块矩阵)。在这种格式中,
你可以输入方向来创建数据而不是逐一输入。比如要输入如下矩阵:
2 1 1 1 1 0 0 0 0 0 1 2 1 1 1 0 0 0 0 0 1 1 2 1 1 0 0 0 0 0 1 1 1 2 1 0 0 0 0 0 1 1 1 1 2 0 0 0 0 0 0 0 0 0 0 2 1 1 1 1 0 0 0 0 0 1 2 1 1 1 0 0 0 0 0 1 1 2 1 1 0 0 0 0 0 1 1 1 2 1 0 0 0 0 0 1 1 1 1 2
使用blockmatrix格式你可以这样创建:
dl n = 10 format=blockmatrix data: rows 1 to 10 cols 1 to 10 value = 0 rows 1 to 5 cols 1 to 5 value = 1 rows 5 6 7 8 9 10 cols 5 to 10 value = 1 diagonal 0 value = 2
在blockmatrix格式中,你区分出一系列单元,并给他们赋值。在示例中,前三行语句给所有单元赋0,次三行(忽略空格)给左上角的矩阵赋值为1,再后三行作用类似,
最后两行将主对角线上的所有值赋为2.考虑一下另一个矩阵:
100 0 0 0 0 0 90 100 0 0 0 0 80 90 100 0 0 0 70 80 90 100 0 0 60 70 80 90 100 0 50 60 70 80 90 100
根据如下示例用blockmatrix格式输入这个矩阵:
dl n=10 format=blockmatrix data: rows all cols all value 0 diag 0 val = 100 diag -1 val =90 diag -2 val=80 d -3 v = 70 d -4 v = 60 d -5 v = 50
3.12LinkedListFormats
网络分析中的一系列重要格式就是被称为linkedlist (链表)的格式,这种格式中参与者只保留数据之间实际发生的联系,忽略那些不发生的联系,这些格式的特别之处在于接受字符型数据。There are two basic types of linked list formats: "nodelists"and"edgelists".Each of these types in turn has two variants,one for 1-mode data and one for 2-modedata.Only the edgelists allow valued data.有两种基本的链表格式类型:"nodelists" (节点列表)and"edgelists"(边界列表)。这两种类型各有两种变式,一种用于单模数据,另一种用于2模数据,只有"edgelists"允许赋值数据。