CamShift、MeanShift运动追踪
以下内容参考:
http://www.cnblogs.com/liqizhou/archive/2012/05/12/2497220.html
http://hi.baidu.com/gilbertjuly/item/985693cf8dc0430cad092f15
Mean Shift算法,一般是指一个迭代的步骤,即先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束.
1. Meanshift推导
给定d维空间Rd的n个样本点 ,i=1,…,n,在空间中任选一点x,那么Mean Shift向量的基本形式定义为:

Sk是一个半径为h的高维球区域,满足以下关系的y点的集合,
![]()
k表示在这n个样本点xi中,有k个点落入Sk区域中.
以上是官方的说法,即书上的定义,我的理解就是,在d维空间中,任选一个点,然后以这个点为圆心,h为半径做一个高维球,因为有d维,d可能大于2,所以是高维球。落在这个球内的所有点和圆心都会产生一个向量,向量是以圆心为起点落在球内的点位终点。然后把这些向量都相加。相加的结果就是Meanshift向量。
如图所以。其中黄色箭头就是Mh(meanshift向量)。
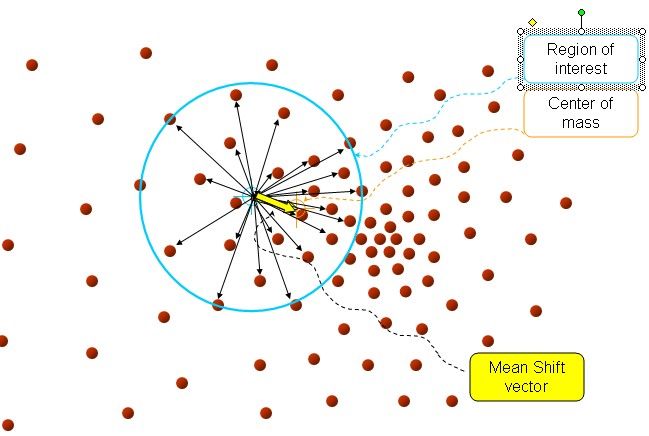
再以meanshift向量的终点为圆心,再做一个高维的球。如下图所以,重复以上步骤,就可得到一个meanshift向量。如此重复下去,meanshift算法可以收敛到概率密度最大得地方。也就是最稠密的地方。
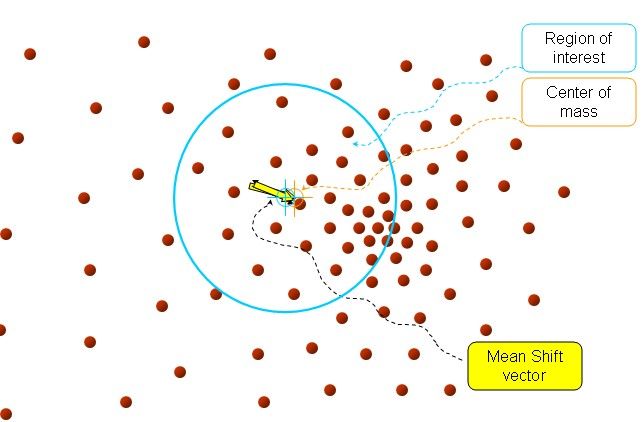
最终的结果如下:

Meanshift推导:
把基本的meanshift向量加入核函数,那么,meanshift算法变

(1)
解释一下K()核函数,h为半径,Ck,d/nhd 为单位密度,要使得上式f得到最大,最容易想到的就是对上式进行求导,的确meanshift就是对上式进行求导.
(2)
令:

K(x)叫做g(x)的影子核,名字听上去听深奥的,也就是求导的负方向,那么上式可以表示

对于上式,如果才用高斯核,那么,第一项就等于fh,k
第二项就相当于一个meanshift向量的式子:

那么(2)就可以表示为
下图分析![]() 的构成,如图所以,可以很清晰的表达其构成。(参见《学习opencv》 P373图10-11)
的构成,如图所以,可以很清晰的表达其构成。(参见《学习opencv》 P373图10-11)

要使得![]() =0,当且仅当
=0,当且仅当![]() =0,可以得出新的圆心坐标:
=0,可以得出新的圆心坐标:
(3)
上面介绍了meanshift的流程,但是比较散,下面具体给出它的算法流程。
- 选择空间中x为圆心,以h为半径为半径,做一个高维球,落在所有球内的所有点xi
- 计算
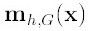 ,如果<ε(人工设定),推出程序。如果>ε, 则利用(3)计算x,返回1.
,如果<ε(人工设定),推出程序。如果>ε, 则利用(3)计算x,返回1.
2.meanshift在图像上的聚类:
真正大牛的人就能创造算法,例如像meanshift,em这个样的算法,这样的创新才能推动整个学科的发展。还有的人就是把算法运用的实际的运用中,推动整个工业进步,也就是技术的进步。下面介绍meashift算法怎样运用到图像上的聚类核跟踪。
一般一个图像就是个矩阵,像素点均匀的分布在图像上,就没有点的稠密性。所以怎样来定义点的概率密度,这才是最关键的。
如果我们就算点x的概率密度,采用的方法如下:以x为圆心,以h为半径。落在球内的点位xi 定义二个模式规则。
(1)x像素点的颜色与xi像素点颜色越相近,我们定义概率密度越高。
(2)离x的位置越近的像素点xi,定义概率密度越高。
所以定义总的概率密度,是二个规则概率密度乘积的结果,可以(4)表示

(4)
其中:![]() 代表空间位置的信息,离远点越近,其值就越大,
代表空间位置的信息,离远点越近,其值就越大,![]() 表示颜色信息,颜色越相似,其值越大。如图左上角图片,按照(4)计算的概率密度如图右上。利用meanshift对其聚类,可得到左下角的图。
表示颜色信息,颜色越相似,其值越大。如图左上角图片,按照(4)计算的概率密度如图右上。利用meanshift对其聚类,可得到左下角的图。

meanShift算法用于视频目标跟踪时,采用目标的颜色直方图作为搜索特征,通过不断迭代meanShift向量使得算法收敛于目标的真实位置,从而达到跟踪的目的。
传统的meanShift算法在跟踪中有几个优势:
(1)算法计算量不大,在目标区域已知的情况下完全可以做到实时跟踪;
(2)采用核函数直方图模型,对边缘遮挡、目标旋转、变形和背景运动不敏感。
同时,meanShift算法也存在着以下一些缺点:
(1)缺乏必要的模板更新;
(2)跟踪过程中由于窗口宽度大小保持不变,当目标尺度有所变化时,跟踪就会失败;
(3)当目标速度较快时,跟踪效果不好;
(4)直方图特征在目标颜色特征描述方面略显匮乏,缺少空间信息;
由于其计算速度快,对目标变形和遮挡有一定的鲁棒性,所以,在目标跟踪领域,meanShift算法目前依然受到大家的重视。但考虑到其缺点,在工程实际中也可以对其作出一些改进和调整;例如:
(1)引入一定的目标位置变化的预测机制,从而更进一步减少meanShift跟踪的搜索时间,降低计算量;
(2)可以采用一定的方式来增加用于目标匹配的“特征”;
(3)将传统meanShift算法中的核函数固定带宽改为动态变化的带宽;
(4)采用一定的方式对整体模板进行学习和更新;
CamShitf算法,即Continuously Apative Mean-Shift算法,基本思想就是对视频图像的多帧进行MeanShift运算,将上一帧结果作为下一帧的初始值,迭代下去。与mean-shift不同的是,CamShitf会自动调整搜索窗口的大小。如果有一个易于分割的区域(如保持紧密的人脸特征),此算法可以根据人在走进或者远离相机时脸的尺寸而自动调整窗口的大小。
基本步骤为:
1.选取关键区域
2.计算该区域的颜色概率分布--反向投影图
3.用MeanShift算法找到下一帧的特征区域
4.标记并重复上述步骤
该算法的关键就是可以在目标大小发生改变的时候,可以自适应的调整目标区域继续跟踪
在进行CamShitf和MeanShift算法的时候,需要输入反向投影图,这就要求有个很重要的预处理过程是计算反向投影图。对应的函数为calcBackProject。所谓反向投影图就是一个概率密度图。calcBackProject的输入通常为目标区域的直方图和待跟踪图像的直方图,输出与待跟踪图像大小相同,每一个像素点表示该点为目标区域的概率。这个点越亮,该点属于物体的概率越大。这样的输入参数太适合做MeanS算法了。
Camshift原理
camshift利用目标的颜色直方图模型将图像转换为颜色概率分布图,初始化一个搜索窗的大小和位置,并根据上一帧得到的结果自适应调整搜索窗口的位置和大小,从而定位出当前图像中目标的中心位置。
分为三个部分:
1--色彩投影图(反向投影):
(1).RGB颜色空间对光照亮度变化较为敏感,为了减少此变化对跟踪效果的影响,首先将图像从RGB空间转换到HSV空间。(2).然后对其中的H分量作直方图,在直方图中代表了不同H分量值出现的概率或者像素个数,就是说可以查找出H分量大小为h的概率或者像素个数,即得到了颜色概率查找表。(3).将图像中每个像素的值用其颜色出现的概率对替换,就得到了颜色概率分布图。这个过程就叫反向投影,颜色概率分布图是一个灰度图像。
2--meanshift
meanshift算法是一种密度函数梯度估计的非参数方法,通过迭代寻优找到概率分布的极值来定位目标。
算法过程为:
(1).在颜色概率分布图中选取搜索窗W
(2).计算零阶距:
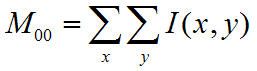
计算一阶距:
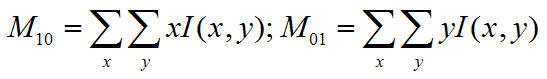
计算搜索窗的质心:

(3).调整搜索窗大小
宽度为 ;长度为1.2s;
;长度为1.2s;
(4).移动搜索窗的中心到质心,如果移动距离大于预设的固定阈值,则重复2)3)4),直到搜索窗的中心与质心间的移动距离小于预设的固定阈值,或者循环运算的次数达到某一最大值,停止计算。关于meanshift的收敛性证明可以google相关文献。
3--camshift
将meanshift算法扩展到连续图像序列,就是camshift算法。它将视频的所有帧做meanshift运算,并将上一帧的结果,即搜索窗的大小和中心,作为下一帧meanshift算法搜索窗的初始值。如此迭代下去,就可以实现对目标的跟踪。
算法过程为:
(1).初始化搜索窗
(2).计算搜索窗的颜色概率分布(反向投影)
(3).运行meanshift算法,获得搜索窗新的大小和位置。
(4).在下一帧视频图像中用(3)中的值重新初始化搜索窗的大小和位置,再跳转到(2)继续进行。
camshift能有效解决目标变形和遮挡的问题,对系统资源要求不高,时间复杂度低,在简单背景下能够取得良好的跟踪效果。但当背景较为复杂,或者有许多与目标颜色相似像素干扰的情况下,会导致跟踪失败。因为它单纯的考虑颜色直方图,忽略了目标的空间分布特性,所以这种情况下需加入对跟踪目标的预测算法。
Camshift的opencv实现
原文http://blog.csdn.net/houdy/archive/2004/11/10/175739.aspx
1--Back Projection
计算Back Projection的OpenCV代码。
(1).准备一张只包含被跟踪目标的图片,将色彩空间转化到HSI空间,获得其中的H分量:
IplImage* target=cvLoadImage("target.bmp",-1); //装载图片
IplImage* target_hsv=cvCreateImage( cvGetSize(target), IPL_DEPTH_8U, 3 );
IplImage* target_hue=cvCreateImage( cvGetSize(target), IPL_DEPTH_8U, 3 );
cvCvtColor(target,target_hsv,CV_BGR2HSV); //转化到HSV空间
cvSplit( target_hsv, target_hue, NULL, NULL, NULL ); //获得H分量
(2).计算H分量的直方图,即1D直方图:
IplImage* h_plane=cvCreateImage( cvGetSize(target_hsv),IPL_DEPTH_8U,1 );
int hist_size[]={255}; //将H分量的值量化到[0,255]
float* ranges[]={ {0,360} }; //H分量的取值范围是[0,360)
CvHistogram* hist=cvCreateHist(1, hist_size, ranges, 1);
cvCalcHist(&target_hue, hist, 0, NULL);
在这里需要考虑H分量的取值范围的问题,H分量的取值范围是[0,360),这个取值范围的值不能用一个byte来表示,为了能用一个byte表示,需要将H值做适当的量化处理,在这里我们将H分量的范围量化到[0,255]。
(3).计算Back Projection:
IplImage* rawImage;
//get from video frame,unsigned byte,one channel
IplImage* result=cvCreateImage(cvGetSize(rawImage),IPL_DEPTH_8U,1);
cvCalcBackProject(&rawImage,result,hist);
(4). result即为我们需要的.
2--Mean Shift算法
质心可以通过以下公式来计算:
(1).计算区域内0阶矩
for(int i=0;i< height;i++)
for(int j=0;j< width;j++)
M00+=I(i,j)
(2).区域内1阶矩:
for(int i=0;i< height;i++)
for(int j=0;j< width;j++)
{
M10+=i*I(i,j);
M01+=j*I(i,j);
}
(3).则Mass Center为:
Xc=M10/M00; Yc=M01/M00
在OpenCV中,提供Mean Shift算法的函数,函数的原型是:
int cvMeanShift(IplImage* imgprob,CvRect windowIn,
CvTermCriteria criteria,CvConnectedComp* out);
需要的参数为:
(1).IplImage* imgprob:2D概率分布图像,传入;
(2).CvRect windowIn:初始的窗口,传入;
(3).CvTermCriteria criteria:停止迭代的标准,传入;
(4).CvConnectedComp* out:查询结果,传出。
注:构造CvTermCriteria变量需要三个参数,一个是类型,另一个是迭代的最大次数,最后一个表示特定的阈值。例如可以这样构造 criteria:
criteria=cvTermCriteria(CV_TERMCRIT_ITER|CV_TERMCRIT_EPS,10,0.1)。
3--CamShift算法
整个算法的具体步骤分5步:
Step 1:将整个图像设为搜寻区域。
Step 2:初始话Search Window的大小和位置。
Step 3:计算Search Window内的彩色概率分布,此区域的大小比Search Window要稍微大一点。
Step 4:运行MeanShift。获得Search Window新的位置和大小。
Step 5:在下一帧视频图像中,用Step 3获得的值初始化Search Window的位置和大小。跳转到Step 3继续运行。
OpenCV代码:
在OpenCV中,有实现CamShift算法的函数,此函数的原型是:
cvCamShift(IplImage* imgprob, CvRect windowIn,
CvTermCriteria criteria,
CvConnectedComp* out, CvBox2D* box=0);
其中:
imgprob:色彩概率分布图像。
windowIn:Search Window的初始值。
Criteria:用来判断搜寻是否停止的一个标准。
out:保存运算结果,包括新的Search Window的位置和面积。
box:包含被跟踪物体的最小矩形。