搜索架构更换solrCloud总结
转贴请声明引用:http://blog.csdn.net/duck_genuine/article/details/8826572
新搜索架构是基于SolrCloud和indexing建索引框架技术的⼀一个分布式垂直搜索。
主要开源工具:zookeeper、ganglia、tcpcopy、nginx、haproxy、rsync
主要开源工具:zookeeper、ganglia、tcpcopy、nginx、haproxy、rsync
旧架构弊端

配置多,以前是全人工,麻烦
- 建索引配置提交目标,一般是本地提交给本地服务。
- 一般是提交给master,然后再由master同步给slave
- 主从同步配置
- 需要配置主从关系,并写好同步脚本,读取配置的从机ip对应的信息
- nginx代理配置
- 一般是提交从机的搜索服务,所有修改upstream配置从机目标
主从机器有改的时候,需要修改建索引配置,同步配置,nginx配置。
大数据切分:
简单切分视频索引:大索引+小索引
大索引太大,放到普通机器上时,搜索性能太慢,所以现在是放到共享内存提高性能,但这样的机器就两台,当并发高的时候,需要更好的cpu,由于搜索计算比较多,并发高的时候,即使现在有16线程cpu也顶不住,容易并发瓶颈,此时应急启用普通机器,由于没有大内存,并不能达到解救的问题,而且放共存内存还有个安全隐患:
- 索引同步时需要双倍大小的空间,共享内存有限,机器重启后索引会丢失。
- 数据集中一台机器,计算消耗大,单机cpu不能线性补足,所以需要分布式计算来补足,特别是搜索命中比较多结果的时候,现架构响应很慢。
搜索业务扩展:
需要知道哪些搜索业务布置在哪些机器,需要记录文档,但是服务的变更太多,文档更新也频繁。
升级
solr扩展包布署,需要逐个更替,停止nginx代理--》停止服务--》更换升级包——》重启服务--》启动nginx的代理
新架构解决了什么问题?
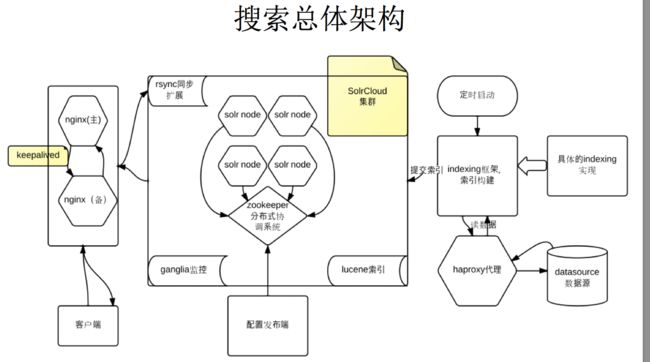
新架构引入zookeeper 开源项目
Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
Zookeeper 会维护一个具有层次关系的数据结构,它非常类似于一个标准的文件系统
Zookeeper 从设计模式角度来看,是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,
一旦这些数据的状态发生变化,Zookeeper 就将负责通知已经在 Zookeeper 上注册的那些观察者做出相应的反应,从而实现集群中类似 Master/Slave 管理模式
cloud做到了管理多个jvm 索引 ,配置方便:
- 配置集中化管理 ,全部提交到zookeeper上,在某一个node启动,所有solrcore会从zookeeper上下载相应的配置
- 没有主从关系的配置,只有leader 与follower关系 ,两者可自动切换,配置一样。
- 建索引只需要知道集群的位置,zk的根目录 ,提交的collection,其它不需要知道,中间是透明的。
- 建索引程序可以随意布置,不需要因为服务在集群里的迁移而改动
- nginx的代理也不需要改动,因为在这个集群里所有的请求都可以转发到目标solrcore处理
大数据切分多片解决性能问题:
- 纵向扩展,将大数据切分小数据:
- 视频collection 切分为8 shards:按照视频主键hash计算均匀分配到8个分片上,每个片大概是4百万的数据 。索引优化只有900m每个分片,可以不放在内存,放在磁盘上。
- 每一次的搜索可以并行分发到8 个分片计算再合并结果,即使单字搜索命中几百万也可以在几百毫秒内响应。
- 横向扩展:每个分片一个leader多个follower作replicate, 每一个分片再做拷贝replicate负载,横向扩展。
- follower与leader可自动切换。
- 并行建索引:提升建索引效率。建索引程序将数据提交到多个shards上并行建索引,提高重建索引效率,
视频索引重建只需要1小时(以前3小时左右,不稳定),客户搜索使用的视频完全重建也只需要1个半钟完成(以前5个小时左右,不稳定 )。
方便之处,建索引程序可以方便布置在集群里机器,当某机器资源紧张时迁移到其它比较闲的机器上,暂时放在内存比较充足的机器上。
同数据源提交给多server,
视频同源过滤提交到另一个collection,过滤掉的视频大概有几百万左右数据,但依然不影响建索引时间。而且还可以提供完整的视频数据搜索,例如在空间,或者开放平台上的视频搜索。
任意结点做更新与搜索:
数据可以提交到该集群里的任意结点,自动转发到目标solrcore更新
任意结点的搜索,结点上发现没有solrcore处理该请求时会抛给远程solrcore来处理,所以nginx上配置的代理 一般不用作变化
持久化更新:
每个更新都会先写入tlog日志,保证更新的持久化。以前写到内存的索引会因为机器挂掉的原因而导致数据丢失,现在有了持久化更新可以考虑做增量的更新,比如删除更新
准实时搜索
删除的更新可以及时可见,将已删除的视频从索引搜索去掉。暂时还没在新架构使用,这个需要测试与调优再上线。
业务变更与升级
扩展包集中管理 :
与war包分离,升级不重新打包war。暂时由rsync同步第三方包到集群里每一台机器的统一位置,每一个搜索服务可能的扩展包都不一样,所以需要在solrconfig.xml配置取对应的扩展包位置。
这个与以前的作法不同,以前是将扩展的包跟原生的solr打包在一起,这样升级需要停止原来的服务再切换。
热布署:
现在是将实现的扩展包通过rysnc同步到各个机器 ,然后reload 一下solrcore,这个过程是原子操作,可以无缝切换,一般不需要达到重启服务级别。
solr新版本升级
新起结点替换旧结点,不资源允许的情况下,可以保留两套,主要做升级切换 使用。
建索引框架变更,IndexBridge---->indexing
以前大部分搜索的建索引都是使用IndexBridge,那么为什么 要更换另一个框架呢:
以前所有搜索业务的预处理过滤器都写到IndexBridge框架上,经过这么多年的沉淀,这个框架已经变得很臃肿,特别是因为多人经手后,不同人的代码写法不同,它的维护性变更得更麻烦。
特别是版本的维护变得更难,因为引用的第三方包使用的是ivy管理 ,但如果版本号没更改就提交,所有人看到的都不一样,有时发布的时候发现比最新的版本号还最新,好像大家都没有提交版本的习惯了。
为了解决这个问题,重新启用indexing框架 ,将不同的建索引业务分离,每一个搜索业务都独立一个项目,继承indexing框架实现自己的业务需求,除了代码干净多了,即使写得再烂的代码也不会影响其它已有的项目的升级变更。
即使indexing框架的升级,也不会影响旧的建索引程序,因为它们都是引用可用的版本,只要做好indexing框架的版本控制与发布就可以了。
我们使用的是ant+ivy做第三方包版本管理与发布, 每一个项目都可以独立打包布置。实现统一的脚本 ,布置的时候看到的很清晰的规则。
#####################################build index#####indexing
#album builder index
0 * * * * (cd /diskb/solrSearch/indexing/indexing-album && sh indexing.sh )
#solr-town builder index
7 * * * * (cd /diskb/solrSearch/indexing/indexing-town && sh indexing.sh )
#solr_ad builder index
14 * * * * (cd /diskb/solrSearch/indexing/indexing-ad && sh indexing.sh )
启用了新的框架多读多写并行提交索引,现在建索引的时间都比以前提高 了几倍:
视频(千万级别) 一小时 ---------- 以前 3小时左右
专辑搜索 建索引 15分钟 --------以前一个多小时
--------------------------------------------------
后续的高级集群管理
数据自动化迁移,可以动态增加分片。
solrcore使用LRU策略管理,资源的利用由集群自动化管理 ,不需要手工去处理
转贴请声明引用:http://blog.csdn.net/duck_genuine/article/details/8826572