ARM嵌入式软件编程经验谈
ARM嵌入式软件编程经验谈
ARM 编译程序通常将全局变量对齐到自然尺寸边界上,以便通过使用 LDR和 STR 指令有效地存取这些变量。这种内存访问方式与多数 CISC (Complex Instruction Set Computing)体系结构不同,在CISC体系结构下,指令直接存取未对齐的数据。因而,当需要将代码从CISC 体系结构向 arm 处理器移植时,内存访问的地址对齐问题必须予以注意。在RISC体系结构下,存取未对齐数据无论在代码尺寸或是程序执行效率上,都将付出非常大的代价。
本文将从以下几个方面讨论在 arm体系结构下的程序设计问题。
未对齐的数据指针
C和 C++编程标准规定,指向某一数据类型的指针,必须和该类型的数据地址对齐方式一致,所以 arm 编译器期望程序中的 C 指针指向 存储器中字对齐地址,因为这可使编译器生成更高效的代码。
比如,如果定义一个指向 int 数据类型的指针,用该指针读取一个字,ARM 编译器将使用LDR 指令来完成此操作。如果读取的地址为四的倍数(即在一个字的边界)即能正确读取。但是,如果该地址不是四的倍数,那么,一条 LDR 指令返回一个循环移位结果,而不是执行真正的未对齐字载入。循环移位结果取决于该地址向对于字的边界的偏移量和系统所使用的端序(Endianness)。例如,如果代码要求从指针指向的地址 0x8006 载入数据,即要载入 0x8006、0x8007、0x8008 和 0x8009 四字节的内容。但是,在 arm 处理器上,这个存取操作载入了0x8004、0x8005、0x8006 和 0x8007 字节的内容。这就是在未对齐的地址上使用指针存取所得到的循环移位结果。
因而,如果想将指针定义到一个指定地址(即该地址为非自然边界对齐),那么在定义该指针时,必须使用 __packed 限定符来定义指针: 例如,
__packed int *pi; // 指针指向一个非字对其内存地址
使用了_packed限定符限定之后, arm 编译器将产生字节存取命令(LDRB或STRB指令)来存取内存,这样就不必考虑指针对齐问题。所生成的代码是字节存取的一个序列,或者取决于编译选项、跟变量对齐相关的移位和屏蔽。但这会导致系统性能和代码密度的损失。
值得注意的是,不能使用 __packed 限定的指针来存取 存储器映射的外围寄存器,因为 ARM 编译程序可使用多个存储器存取来获取数据。因而,可能对实际存取地址附近的位置进行存取,而这些附近的位置可能对应于其它外部寄存器。当使用了位字段(Bitfield)时, arm 程序将访问整个结构体,而非指定字段。
编译器的缺省行为
多数 嵌入式应用程序最初都是在原型环境下开发的。无论什么样的原型环境的资源与最终产品环境都是有差异的。因此,考虑如何将 嵌入式应用程序从其所依赖的开发工具或调试环境中移植到在目标硬件上独立运行是非常重要的。
开始编写嵌入式应用程序时,开发者可能并不清楚目标硬件的具体规格。如,目标系统使用了什么样的外围设备、存储器映射情况甚至不能确定处理器的型号。 为在了解这些详细信息前能够继续软件的开发,RVCT 工具提供了很多默认的操作,使用户能编译和调试与目标系统无关的应用程序代码。下面详细介绍介绍这些编译选项,只有深入了解这些编译选项设置,才能使开发更顺利的进行。
调整 C 库使其适应目标硬件
默认情况下,C 库利用semihostig机制来提供设备驱动级的功能,使得主机主机能够用作输入和输出设备。这种机制对于嵌入式开发十分有用,因为用于开发的硬件系统通常没有最终系统的输入和输出设备。
最简单的函数重定向的例子就是用户希望fputc()函数能够将字符从目标系统的串口输出而不是在调试时,将字符从调试器的控制台输出。这时就需要重新实现该函数。下面的例子将fputc() 的输入字符参数重新指向一连续输出函数 sendchar(),将定该例在一个独立的源文件中实现的。这样,fputc() 在依目标而定的输出和 C 库标准输出函数之间充当一个抽象层。
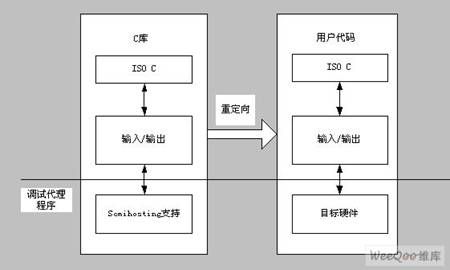
图1 C库函数重定向
例子程序的代码如下所示。
extern void sendchar(char *ch);
int fputc(int ch, FILE *f)
{?? /* e.g. write a character to an UART */
char tempch = ch;
sendchar(&tempch);
return ch;
}
映象文件存储器映射调整
映像由域(Regions)和输出段(Output Sections)组成。每个域可以有不同的加载地址和执行地址。
分散加载可以更加方便准确的指定映像存储器映射,为映像组件分组和布局提供了全面控制。它能够描述由载入时和执行时分散在存储器映射中的多个区组成的复杂映像映射。虽然,分散加载可以用于简单映像,但它通常仅用于具有复杂存储器映射的映像。
要构建映像的存储器映射,必须向armlink 提供以下信息:
·? 分组信息? 决定如何将各输入段组织成相应的输出段和域;
·? 定位信息? 决定各域在存储空间的起始地址。
有两种方法可以实现指定映像文件的分组和定位信息:如果映像文件中地址映射关系比较简单,可以使用命令行选项;如果映像文件中地址映射关系比较复杂的情况,可以使用一个配置文件。使用该配置文件可以高速链接器相关的地址映射关系。配置文件又叫Scatter文件,是一个文本文件,通过下面的链接选项来实现。
-scatter? filename
复位和初始化
arm嵌入式系统的初始化序列如图2所示。系统启动时立即执行复位处理程序,然后进入$Sub$main()的代码执行。
复位处理程序是用汇编语言编写的代码块,它在系统复位时执行,完成系统必须初始化操作。对于具有局部存储器的内核,如Caches、紧密藕荷存储器 (TCM)、存储管理单元 (MMU) 和存储器保护单元 (MPU) 等,在初始化过程这一阶段完成必要的配置。复位处理程序在执行之后,通常跳转到 __main 以开始 C 库的初始化序列。
一般情况下,系统初始化代码和主应用程序是分开的。系统初始化要在主应用程序启动前完成。但部分与硬件相关的系统初始化过程,如启用Cache和中断,必须在C库初始化代码执行完成后才能执行。
为了在进入主应用程序之前,完成系统初始化,可以使用$sub和$super函数标识符在进入主程序之前插入一个例程。这一机制可以在不改变源代码的情况下扩展函数的功能。
下面的例子说明了如何使用$sub和$super函数标识。链接程序通过调用$sub$$main()函数取代对main()的调用。所以用户可以在自己编写的$sub$$main()例程中启用Cache或使能中断。
extern void $Super$$main(void);
void $Sub$$main(void)
{
cache_enable();??? // enables caches
int_enable();????? // enables interrupts
$Super$$main();??? // calls original main()
}
在$Sub$$main(void)函数中,链接程序通过调用$Super$$main(),是代码跳转到实际的main()函数。
[nextpgae]
在完成硬件初始化之后,必须考虑主应用程序运行在何种模式。如果应用程序运行在特权模式(Privileged mode),只需在退出复位处理程序前切换到适当的模式;如果应用程序运行在用户模式下,要在完成系统初始化之后,再切换到用户模式。模式的切换工作,一般在$Sub$$main(void)函数中完成。
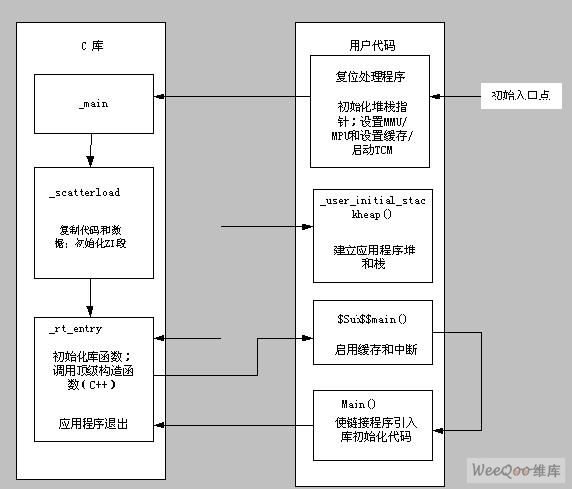
图2 arm嵌入式系统的初始化序列