数据挖掘系列之一(数据仓库之一):数据仓库概述
数据仓库是一个从多个数据源收集的信息储存库,存放在一个一致的模式下,并且通常驻留在单个站点。数据仓库通过数据清理、数据变换、数据集成、数据装入和定期数据刷新过程来构造。
数据仓库收集了整个组织的主题信息,因此它是企业范围的。数据集市(data mart)是数据仓库的一个部门子集,它聚焦在选定的主题上,是部门范围的。
数据仓库非常适合联机分析处理(OLAP)。OLAP操作包括下钻(drill-down)和上卷(roll-up),允许用户在不同的汇总级别观察数据。
数据仓库最早是Inmon W H于1992年提出:数据仓库是Subject-Oriented(面向主题的)、Integrated(集成的)、Time-Variant(随时间变化的,时间变异的)、Non-Volatile(非易失的)一系列用于管理和决策制定的数据集。(参考原文:Building the data bridge: the ten critical success factors of building a data warehouse和EIS and the data warehouse: a simple approach to building an effective foundation for EIS)
1 数据仓库特征
1.1 面向主题的
1.2 集成的
使用数据清理和数据集成技术,确保命名约定, 编码结构, 属性度量等的一致性。
1.3 时变的
数据仓库的时间跨度显著地比操作数据库长:操作数据库数据: 当前值数据;数据仓库数据: 从历史的角度提供数据 (例如, 过去 5-10 年)。数据仓库中的 每个键结构显式或隐式地包含时间元素,但是, 操作数据的键可能包含, 也可能不包含“时间元素”。
时变性是指数据仓库的数据是随时间不断变化的。这个特征表现在以下三个方面:
(1)数据仓库随时间变化不断增加新的数据内容。
(2)数据仓库随时间变化不断删去旧的数据内容。数据仓库的数据也有存储期限,只不过这个期限远远长于操作型环境的数据时限。
(3)数据仓库中包含大量的综合数据,这些数据很多与时间有关,因而要随着时间的变化不断地进行重新综合。
时变性是从宏观角度的变化,而非易失性是微观角度的不变化。
1.4 非易失的(非易变的,不可更新的)
从操作环境转换过来的数据物理地分离存放。数据的更新不在数据仓库环境中出现。
-不需要事务处理, 恢复, 和并发控制机制
-只需要两种数据存取操作: 数据的初始化装入 和 数据访问(多为读操作,无增删改操作).
2 数据仓库体系结构
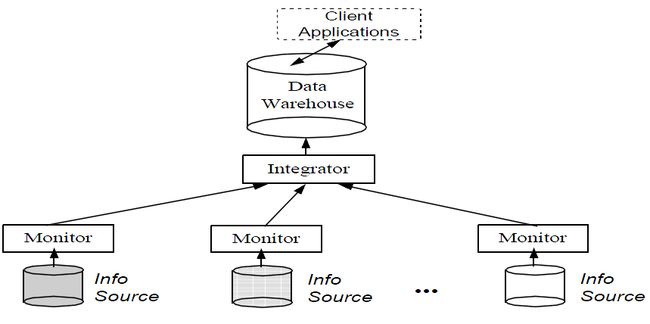
Stanford大学的WHIPS(WareHouse Information Prototype at Stanford)[2]提出的数据仓库体系结构(如下图)中,底层是多个信息源,信息源可以是关系型数据或者其他数据,如Flat Files,HTML Docs,Knowledge base,Legacy Data等。包装器部件将信息整理成数据仓库中使用的数据模型,监视器部件负责对本地信息源中需要提取的数据及其变化做自动探测,并把它们报告给集成器。
当一个新的信息源连接到数据仓库或者某信息源状态发生变化,Monitor将新数据或者修改过的数据发给Integrator。Integrator负责把信息installing到DW中,其间可能还需要Filtering,Summary,Merging等操作。
数据仓库中包含大量的历史性信息,而底层的数据源一般不维护这些信息。因此,传统视图反映底层数据,而数据仓库反映底层数据的历史。
2.1 数据库体系化环境
数据库体系化环境是在一个企业或组织内,由各个面向应用的OLTP数据库及各级面向主题的数据仓库所组成的完整的数据环境,在这个数据环境上建立和进行一个企业或部门的从OLTP到企业管理决策的所有应用。这个数据环境分为两部分:操作型环境和分析型环境,分别为操作型处理和分析型处理这两类数据处理服务。
体系化环境如下:
操作型环境→数据仓库(全局级)→局部仓库(部门级)→个人仓库
箭头表示数据的抽取方向,这种数据仓库的实现采用“自顶向下”的方法,也就是,首先建立一个全局的数据仓库,然后在此基础上建立部门级和个人级数据仓库,这种方法有利于各级数据仓库的一致性。这类似于(八)中讨论的“从属数据集市”。但是,这种方法必然导致实施周期长,见效慢,费用高等问题。
另一种做法是“自底向上”地建立多级数据仓库,类似于(八)中的“独立数据集市”。这种思想的核心是:从最关心的部分开始,先以最少的投资,完成当前需求,然后再不断扩充完善。
2.2 三种数据仓库体系结构的比较[3]
(1)企业信息化工厂(CIF)
支持者:Bill Inmon
其他称谓:原子数据仓库、企业数据仓库
描述:
- 企业数据仓库是原子数据的一种集成仓库
- 不能被直接访问
- 数据集市为部门使用/分析而重新组织数据
维度设计的角色:维度设计只应用于数据集市
(2)维度数据仓库
支持者:Ralph Kimball
其他称谓:企业数据仓库、总线体系结构、结构化数据集市、虚拟数据集市
描述:
- 维度数据仓库是原子数据的一种集成仓库
- 可以被直接访问
- 包含在维度数据仓库的主题区域,有时称为数据集市
- 数据集市不要求是独立的数据库
维度设计的角色:所有数据按维度组织
(3)独立数据集市
支持者:(无倡导者但很常见)
其他称谓:数据集市、竖井式、烟筒型、孤岛型
描述:
- 主题区域的实现不需要企业环境
维度设计的角色:可以使用维度设计
3 OLAP简介
OLAP分为基于多维数据库(MDDB)的OLAP(MD-OLAP)和基于关系数据库的OLAP(ROLAP)。
关系数据库采用关系表的数据组织形式,而多维数据库中采用二维矩阵的形式。二维矩阵比关系表表达更清晰且占用存储少,综合速度快。
| 产品名称 | 地区 | 销售量 |
| 冰箱 | 东北 | 50 |
| 冰箱 | 西北 | 60 |
| 彩电 | 东北 | 70 |
| 彩电 | 西北 | 80 |
| 空调 | 东北 | 90 |
| 空调 | 西北 | 100 |
| ... | ... | ... |
| 东北 | 西北 | |
| 冰箱 | 50 | 60 |
| 彩电 | 70 | 80 |
| 空调 | 90 | 100 |
3.1 多维分析的基本动作
(1)切片(Slice)在多维数组的某一维上选定一个维成员的动作称为切片(定义一)。即在多维数组(维1,维2,……,维n,变量)中选一维,如维i,指定其值Vi,所得到的多维数组的一个子集(维1,维2,……维成员Vi,……维n,变量)。其中维成员是维的一个取值。
定义二:选定多维数组的一个二维子集的动作叫做切片。选定两个维,指定这两个维的值分别取某个区间,其余维都取定一个值(或维成员),得到的就是多维数组在两个维上的一个二维子集。注意:定义一中,选一个维,指定一个值,而非指定取值区间。
(2)切块(Dice)
定义一:在多维数组的某一维上选定某一区间的维成员的动作称为切块,即限制多维数组的某一维的取值区间。
定义二:选定多维数组的一个三维子集的动作称为切块。即选定3个维,这三个维度上取某一区间或任意的维成员,而其余的维都取定一个维成员,则得到在三个维上的一个三维子集。
(3)旋转
(4)上卷
(5)下钻
3.2 Codd关于OLAP产品的12条评价准则
E.F. Codd是关系型数据库之父。
准则1 OLAP模型必须提供多维概念视图
准则2 透明性准则
准则3 存取能力准则
准则4 稳定的报表性能
准则5 C/S体系结构
准则6 维的等同性准则
准则7 动态的稀疏矩阵处理准则
准则8 多用户支持能力准则
准则9 非受限的跨维操作
准则10 直观的数据操纵
准则11 灵活的报表生成
准则12 不受限维与聚集层次
之后Gartner和IRI有做了补充:(13)多维数组(14)OLAP连接操作(15)数据库管理工具(16)对象存储(17)子集选择(18)细节深入(19)局部数据支持(20)递增数据库刷新(21)SQL接口(22)时间序列分析(23)过程语言和开发工具(24)功能的集成化
参考资料:
[1]王珊.数据仓库技术与联机分析处理.1998
[2]基于大型数据仓库的数据采掘:研究综述
[3]Star Schema完全参考手册——数据仓库维度设计权威指南