在进行网络编程时,可能需要直接操作原始的IP数据报,例如编写网络嗅探器。此时要定义一个表示IP数据报首部的结构体来获取首部中的各个信息,问题也随之而来:平时我们使用的数据都是BYTE、WORD或者DWORD,但IP数据报首部的有些字段并不按照字节、字或双字对齐,字段的长度也不是一字节、两字节或四字节,这种不一致的现象使得结构体的定义很有难度。我见过几种IP数据报首部结构体的定义,虽然方法各异,但都是大量使用union,将几个字段塞进一个BYTE或WORD中,在代码中还要通过移位、按位与等操作获取实际的字段。其实,只要理解数据在内存中是如何摆放的,以及利用好结构体定义的特性,可以最大限度地使结构体的字段直接对应首部中的字段,避免在代码中使用大量的位操作。
位域
使用C/C++编程时我们都会大量定义和使用结构体,但可能有不少人还不知道定义结构体时可以使用“位域”这个特性。位域是指不需要占据整个字段长度,而只需要占据一个或多个位的字段。定义方法如下所示:
structByte {
BYTELow : 4;
BYTEHigh : 4;
};
上面的代码定义了一个名为Byte的结构体,它有两个字段Low和High,这两个字段的类型都是BYTE,而且都指定了只占用四个位,所以它们共用一个BYTE的空间。又因为Low定义在High之前,所以Low使用这个BYTE的低四位,High使用高四位。
位域的类型除了BYTE之外,还可以使用WORD和DWORD。要注意的是,在使用位域时,对于那些希望共用同一个BYTE、WORD或DWORD的字段,要始终使用相同的类型来定义,只有当BYTE、WORD或DWORD的位分配完毕时,才使用另一种类型。例如,不要出现下面的定义:
structBitFields {
WORDField1 : 8;
BYTEField2 : 8;
};
structBitFields {
BYTEField1 : 3;
WORDField2 : 5;
};
上面的定义令人难以理解(至少我是根本无法理解),而且也不知道编译器会如何处理这些定义。所以,为了程序的可理解性和正确性,应该中规中矩地使用位域:
structBitFields {
BYTEField1 : 5;
BYTEField2 : 3;
WORDField3 : 7;
WORDField4 : 3;
WORDField5 : 6;
};
有了位域,在访问这些字段时,编译器会自动进行位操作,还会自动进行截断,所以在代码中再也不需操心这些繁琐的操作了。
位序
字节序对大家来说都不会陌生,它表示字节在内存中的存放顺序。而位序与字节序的意义相近,它表示的是字节内每个位的存放顺序,也有大端和小端格式。我们通常只在字节级别上访问数据,几乎不会在位级别上访问数据,所以忽略了位序这个问题。现在我们用到了位域,已经深入到了位级别,因此很有必要了解一下Intel处理器的位序。遗憾的是,我没找到任何资料解析Intel处理器使用哪种位序,因此只能靠自己动手进行实验。
实验很简单,下面是实验的代码:
voidwmain() {
structByte {
BYTEZero : 1;
BYTEOne : 1;
BYTETwo : 1;
BYTEThree : 1;
BYTEFour : 1;
BYTEFive : 1;
BYTESix : 1;
BYTESeven : 1;
};
Byte b = { 0 };
b.Zero = 1;
b.Five = 1;
}
该代码将一个字节的第0位和第5位设置为1,其它位都是0。由于Visual Studio不能以二进制方式查看数据,因此我使用WinDbg进行查看:

左上角第一个字节就是变量b的数据,可以看到第0位和第5位已经设置为1。更重要的是,看到了位序是大端格式,即低地址存放高位,高地址存放低位。
了解了位域和位序之后,下面就开始定义IP数据报的首部了。
IP数据报首部的定义
首先来看一下IP数据报首部的格式:
对于那些占据整个BYTE、WORD或DWORD的字段,可以直接按照它们的先后顺序来定义而不会出现任何问题,而其它“不规则”的字段则需要进行特殊的设计。“不规则”的字段包括:版本、首部长度、片偏移以及三个标识位。
首先来看一下版本和首部长度,它们都是四字节长度,一开始我们会很自然地按照它们的先后顺序来定义:
structIPHeader {
BYTEVersion : 4;
BYTEHeaderLength : 4;
};
然而这样是错误的,你使用Version字段得到的是首部长度,使用HeaderLength得到的是版本,两者调转过来了!之所以会出现这样的错误,恰恰是位序的问题。上文说过,Intel处理器使用的是大端格式的位序,所以IPHeader结构的第一个字节是这样的:
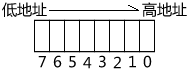
由于Version定义在前,所以Version使用0~3位,HeaderLength使用4~7位。很明显,这跟IP数据报首部的格式正好相反。所以,正确的定义应该是:
structIPHeader {
BYTEHeaderLength : 4;
BYTEVersion : 4;
};
接下来的区分服务、总长度和标识都占据了整个BYTE和WORD的长度,所以按顺序定义它们就行了:
structIPHeader {
BYTEHeaderLength : 4;
BYTEVersion : 4;
BYTEDS;
WORDTotalLength;
WORDID;
};
接下来的三个标识位和片偏移则有点复杂。首先来看一下一个WORD中的位是如何放置的(注意是小端字节序):
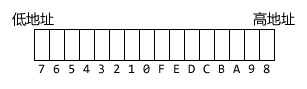
对照IP数据报首部的格式图,可以看到三个标识位分别占用了WORD的7、6和5位,剩下的位都是片偏移的。虽然从图中看上去片偏移的位都连接在一起,可是如果以位编号的顺序来看的话,片偏移实际上被标识位分割成了两部分,分别在两个BYTE中:第一部分是0~4位,第二部分是8~F位。所以,无论如何也不能仅仅使用位域把这两部分组合在一起,必须在代码中使用位操作来组合。这确实是一个遗憾。
将这两部分组合起来有多种方法,我使用的方法是:将这个WORD分成两个BYTE,第一个BYTE 的最后三个位作为标致位,前面5个位作为片偏移的第一部分,第二个BYTE全部作为片偏移的第二部分,如下所示:
structIPHeader {
BYTEHeaderLength : 4;
BYTEVersion : 4;
BYTEDS ;
WORDTotalLength;
WORDID;
BYTEFragmentOffset0 : 5;
BYTEMF : 1;
BYTEDF : 1;
BYTEReserved : 1;
BYTEFragmentOffset1;
};
注意第一个BYTE中的字段都按反顺序来定义,这也是位序的缘故,就不再解释了。为了得到完整的片偏移,要将第一部分左移8位,再加上第二部分:
FragmentOffset = (FragmentOffset0 << 8) + FragmentOffset1
好了,IP数据报首部中比较难搞的字段都已经解决了,剩下的都很容易解决,下面是完整的定义:
structIPHeader {
BYTEHeaderLength : 4; //首部长度
BYTEVersion : 4; //版本
BYTEDS; //区分服务
WORDTotalLength; //总长度
WORDID; //标识
BYTEFragmentOffset0 : 5; //片偏移
BYTEMF : 1; //MF标识
BYTEDF : 1; //DF标识
BYTEReserved : 1; //保留标识
BYTEFragmentOffset1; //片偏移
BYTETTL; //生存时间
BYTEProtocol; //协议
WORDChecksum; //检验和
DWORDSourceAddress; //源地址
DWORDDestinationAddress; //目的地址
};
TCP报文段首部的定义
既然说到了IP数据报首部,就不得不说一下TCP报文段的首部。下面是TCP报文段的首部格式:
上图中比较复杂的是数据偏移、保留字段以及一些标致位,不过有了上文的讲解,相信这不再是问题。下面直接给出完整的定义,不再详细解释了:
structTCPHeader {
WORDSourcePort; //源端口
WORDDestinationPort; //目的端口
DWORDSequenceNumber; //序号
DWORDAcknowledgmentNumber; //确认号
BYTEReserved0 : 4; //保留字段第一部分
BYTEDataOffset : 4; //数据偏移
BYTEFIN : 1; //FIN标识
BYTESYN : 1; //SYN标识
BYTERST : 1; //RST标识
BYTEPSH : 1; //PSH标识
BYTEACK : 1; //ACK标识
BYTEURG : 1; //URG标识
BYTEReserved1 : 2; //保留字段第二部分
WORDWindow; //窗口
WORDChecksum; //检验和
WORDUrgentPointer; //紧急指针
};
UDP报文段首部的定义
为了本文的完整性,这里也给出UDP报文段首部的格式以及定义。
structUDPHeader {
WORDSourcePort; //源端口
WORDDestinationPort; //目的端口
WORDLength; //长度
WORDChecksum; //检验和
};