ICTCLAS分词系统研究(二)--词典结构
ICTCLAS的词典结构是理解分词的重要依据,通过这么一个数据结构设计合理访问速度高效的词典才能达到快速准备的分词的目的。
通过阅读和分析源代码,我们可以知道,是程序运行初,先把词典加载到内存中,以提高访问的速度。源代码在Result.cpp的构造函数CResult()内实现了词典和分词规则库的加载。如下代码所示:
CResult::CResult()
{
……
m_dictCore.Load("data//coreDict.dct");
m_POSTagger.LoadContext("data//lexical.ctx");
……
}
我们再跳进Load方法具体分析它是怎样读取数据词典的,看Load的源代码:
bool CDictionary::Load(char *sFilename,bool bReset)
{
FILE *fp;
int i,j,nBuffer[3];
//首先判断词典文件能否以二进制读取的方式打开
if((fp=fopen(sFilename,"rb"))==NULL)
return false;//fail while opening the file
//为新文件释放内存空间
for( i=0;i<CC_NUM;i++)
{//delete the memory of word item array in the dictionary
for( j=0;j<m_IndexTable[i].nCount;j++)
delete m_IndexTable[i].pWordItemHead[j].sWord;
delete [] m_IndexTable[i].pWordItemHead;
}
DelModified();//删除掉修改过的,可以先不管它
//CC_NUM:6768,应该是GB2312编码中常用汉字的数目6763个加上5个空位码
for(i=0;i<CC_NUM;i++)
{
//读取一个整形数字(词块的数目)
fread(&(m_IndexTable[i].nCount),sizeof(int),1,fp);
if(m_IndexTable[i].nCount>0)
m_IndexTable[i].pWordItemHead=new WORD_ITEM[m_IndexTable[i].nCount];
else
{
m_IndexTable[i].pWordItemHead=0;
continue;
}
j=0;
//根据前面读到的词块数目,循环读取一个个词块
while(j<m_IndexTable[i].nCount)
{
//读取三字整数,分别为频度(Frequency)/词内容长度(WordLen)/句柄(Handle)
fread(nBuffer,sizeof(int),3,fp);
m_IndexTable[i].pWordItemHead[j].sWord=new char[nBuffer[1]+1];
//读取词内容
if(nBuffer[1])//String length is more than 0
{
fread(m_IndexTable[i].pWordItemHead[j].sWord,sizeof(char),nBuffer[1],fp);
}
m_IndexTable[i].pWordItemHead[j].sWord[nBuffer[1]]=0;
if(bReset)//Reset the frequency
m_IndexTable[i].pWordItemHead[j].nFrequency=0;
else
m_IndexTable[i].pWordItemHead[j].nFrequency=nBuffer[0];
m_IndexTable[i].pWordItemHead[j].nWordLen=nBuffer[1];
m_IndexTable[i].pWordItemHead[j].nHandle=nBuffer[2];
j+=1;//Get next item in the original table.
}
}
fclose(fp);
return true;
}
看完上面的源代码,词典的结构也应该基本清楚了,如下图一所示:
图一
修改表的数据结构和上图差不多,但是在词块数目后面多了一个nDelete数目,即删除的数目,数据结构如下图二所示:
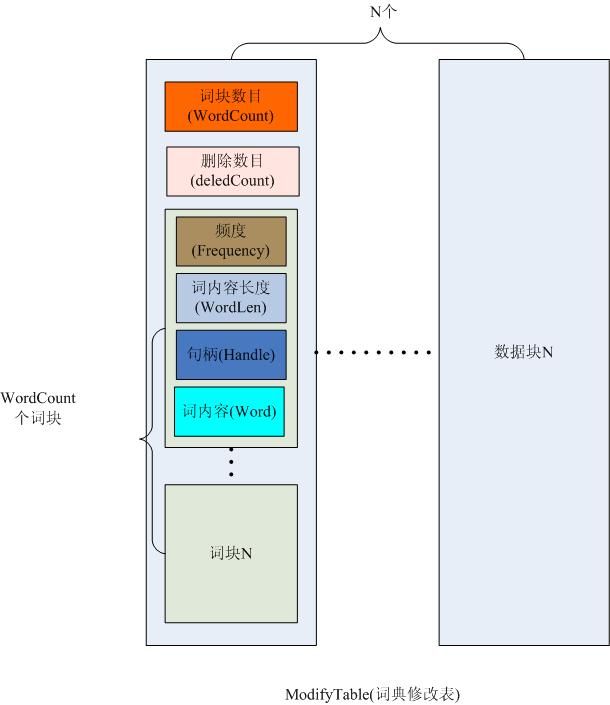
图二
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。词典库图一所示的6768个块即对应GB2312编码中的这个6768个区位.图一中每一个大块代表以该字开头的所有词组,括号内的字为区位码对应的汉字,词典表中并不存在,为了说明方便才添加上去的.如下所示:
块6759
count:5
wordLen:2 frequency:0 handle:24832 word:(黯)淡
wordLen:2 frequency:1 handle:24942 word:(黯)淡
wordLen:2 frequency:3 handle:31232 word:(黯)然
wordLen:6 frequency:0 handle:27648 word:(黯)然神伤
wordLen:6 frequency:0 handle:26880 word:(黯)然失色
块6760
count:1
wordLen:2 frequency:0 handle:28160 word:(鼢)鼠
块6761
count:2
wordLen:4 frequency:0 handle:28160 word:(鼬)鼠皮
wordLen:2 frequency:0 handle:28160 word:(鼬)獾
对修改后如何保存的源代码进行分析:
bool CDictionary::Save(char *sFilename)
{
FILE *fp;
int i,j,nCount,nBuffer[3];
PWORD_CHAIN pCur;
if((fp=fopen(sFilename,"wb"))==NULL)
return false;//fail while opening the file
//对图一中所示的6768个数据块进行遍历
for(i=0;i<CC_NUM;i++)
{
pCur=NULL;
if(m_pModifyTable)
{
//计算修改后有效词块的数目
nCount=m_IndexTable[i].nCount+m_pModifyTable[i].nCount-m_pModifyTable[i].nDelete;
fwrite(&nCount,sizeof(int),1,fp);
pCur=m_pModifyTable[i].pWordItemHead;
j=0;
//对原表中的词块和修改表中的词块进行遍历,并把修改后的添加到原表中
while(pCur!=NULL&&j<m_IndexTable[i].nCount)
{
//如果修改表中的词长度小于原表中对应位置的词的长度或者长度相等但nHandle值比原表中的小,则把修改表中的写入到词典文件当中.
if(strcmp(pCur->data.sWord,m_IndexTable[i].pWordItemHead[j].sWord)<0||(strcmp(pCur->data.sWord,m_IndexTable[i].pWordItemHead[j].sWord)==0&&pCur->data.nHandle<m_IndexTable[i].pWordItemHead[j].nHandle))
{//Output the modified data to the file
nBuffer[0]=pCur->data.nFrequency;
nBuffer[1]=pCur->data.nWordLen;
nBuffer[2]=pCur->data.nHandle;
fwrite(nBuffer,sizeof(int),3,fp);
if(nBuffer[1])//String length is more than 0
fwrite(pCur->data.sWord,sizeof(char),nBuffer[1],fp);
pCur=pCur->next;//Get next item in the modify table.
}
//频度nFrequecy等于-1说明该词已被删除,跳过它
else if(m_IndexTable[i].pWordItemHead[j].nFrequency==-1)
{
j+=1;
}
//如果修改表中的词长度比原表中的长度大或 长度相等但句柄值要多,就把原表的词写入的词典文件中
else if(strcmp(pCur->data.sWord,m_IndexTable[i].pWordItemHead[j].sWord)>0||(strcmp(pCur->data.sWord,m_IndexTable[i].pWordItemHead[j].sWord)==0&&pCur->data.nHandle>m_IndexTable[i].pWordItemHead[j].nHandle))
{//Output the index table data to the file
nBuffer[0]=m_IndexTable[i].pWordItemHead[j].nFrequency;
nBuffer[1]=m_IndexTable[i].pWordItemHead[j].nWordLen;
nBuffer[2]=m_IndexTable[i].pWordItemHead[j].nHandle;
fwrite(nBuffer,sizeof(int),3,fp);
if(nBuffer[1])//String length is more than 0
fwrite(m_IndexTable[i].pWordItemHead[j].sWord,sizeof(char),nBuffer[1],fp);
j+=1;//Get next item in the original table.
}
}
//把原表中剩余的词写入的词典文件当中
if(j<m_IndexTable[i].nCount)
{
while(j<m_IndexTable[i].nCount)
{
if(m_IndexTable[i].pWordItemHead[j].nFrequency!=-1)
{//Has been deleted
nBuffer[0]=m_IndexTable[i].pWordItemHead[j].nFrequency;
nBuffer[1]=m_IndexTable[i].pWordItemHead[j].nWordLen;
nBuffer[2]=m_IndexTable[i].pWordItemHead[j].nHandle;
fwrite(nBuffer,sizeof(int),3,fp);
if(nBuffer[1])//String length is more than 0
fwrite(m_IndexTable[i].pWordItemHead[j].sWord,sizeof(char),nBuffer[1],fp);
}
j+=1;//Get next item in the original table.
}
}
else////原表已到尾部但修改表还没有遍历完,把修改表中剩余的词写入到词典文件当中
while(pCur!=NULL)//Add the rest data to the file.
{
nBuffer[0]=pCur->data.nFrequency;
nBuffer[1]=pCur->data.nWordLen;
nBuffer[2]=pCur->data.nHandle;
fwrite(nBuffer,sizeof(int),3,fp);
if(nBuffer[1])//String length is more than 0
fwrite(pCur->data.sWord,sizeof(char),nBuffer[1],fp);
pCur=pCur->next;//Get next item in the modify table.
}
}
//不是修改标记,则把原表的数据全部写入到词典文件当中
else
{
fwrite(&m_IndexTable[i].nCount,sizeof(int),1,fp);
//write to the file
j=0;
while(j<m_IndexTable[i].nCount)
{
nBuffer[0]=m_IndexTable[i].pWordItemHead[j].nFrequency;
nBuffer[1]=m_IndexTable[i].pWordItemHead[j].nWordLen;
nBuffer[2]=m_IndexTable[i].pWordItemHead[j].nHandle;
fwrite(nBuffer,sizeof(int),3,fp);
if(nBuffer[1])//String length is more than 0
fwrite(m_IndexTable[i].pWordItemHead[j].sWord,sizeof(char),nBuffer[1],fp);
j+=1;//Get next item in the original table.
}
}
}
fclose(fp);
return true;
}
增加一个词条目:
bool CDictionary::AddItem(char *sWord, int nHandle,int nFrequency)
{
char sWordAdd[WORD_MAXLENGTH-2];
int nPos,nFoundPos;
PWORD_CHAIN pRet,pTemp,pNext;
int i=0;
//预处理,去掉词的前后的空格
if(!PreProcessing(sWord, &nPos,sWordAdd,true))
return false;
//查找词典原表中该词是否存在
if(FindInOriginalTable(nPos,sWordAdd,nHandle,&nFoundPos))
{//The word exists in the original table, so add the frequency
//Operation in the index table and its items
if(m_IndexTable[nPos].pWordItemHead[nFoundPos].nFrequency==-1)
{//The word item has been removed
m_IndexTable[nPos].pWordItemHead[nFoundPos].nFrequency=nFrequency;
if(!m_pModifyTable)//Not prepare the buffer
{
m_pModifyTable=new MODIFY_TABLE[CC_NUM];
memset(m_pModifyTable,0,CC_NUM*sizeof(MODIFY_TABLE));
}
m_pModifyTable[nPos].nDelete-=1;
}
else
m_IndexTable[nPos].pWordItemHead[nFoundPos].nFrequency+=nFrequency;
return true;
}
//如果修改表为空,为它初始化空间
if(!m_pModifyTable)//Not prepare the buffer
{
m_pModifyTable=new MODIFY_TABLE[CC_NUM];
memset(m_pModifyTable,0,CC_NUM*sizeof(MODIFY_TABLE));
}
//在修改表中查询该词是否存在,如果存在增加该词的频度
if(FindInModifyTable(nPos,sWordAdd,nHandle,&pRet))
{
if(pRet!=NULL)
pRet=pRet->next;
else
pRet=m_pModifyTable[nPos].pWordItemHead;
pRet->data.nFrequency+=nFrequency;
return true;
}
//如果没有在修改表中找到,则添加进去
pTemp=new WORD_CHAIN;//Allocate the word chain node
if(pTemp==NULL)//Allocate memory failure
return false;
memset(pTemp,0,sizeof(WORD_CHAIN));//init it with 0
pTemp->data.nHandle=nHandle;//store the handle
pTemp->data.nWordLen=strlen(sWordAdd);
pTemp->data.sWord=new char[1+pTemp->data.nWordLen];
strcpy(pTemp->data.sWord,sWordAdd);
pTemp->data.nFrequency=nFrequency;
pTemp->next=NULL;
//插入到修改表中
if(pRet!=NULL)
{
pNext=pRet->next;//Get the next item before the current item
pRet->next=pTemp;//link the node to the chain
}
else
{
pNext=m_pModifyTable[nPos].pWordItemHead;
m_pModifyTable[nPos].pWordItemHead=pTemp;//Set the pAdd as the head node
}
pTemp->next=pNext;//Very important!!!! or else it will lose some node
//把词块数目加一
m_pModifyTable[nPos].nCount++;//the number increase by one
return true;
}
删除修改过的词条
bool CDictionary::DelModified()
{
PWORD_CHAIN pTemp,pCur;
if(!m_pModifyTable)
return true;
for(int i=0;i<CC_NUM;i++)
{
pCur=m_pModifyTable[i].pWordItemHead;
//删除链表上的节点
while(pCur!=NULL)
{
pTemp=pCur;
pCur=pCur->next;
delete pTemp->data.sWord;
delete pTemp;
}
}
delete [] m_pModifyTable;
m_pModifyTable=NULL;
return true;
}
//采用二分法进行查找
bool CDictionary::FindInOriginalTable(int nInnerCode,char *sWord,int nHandle,int *nPosRet)
{
PWORD_ITEM pItems=m_IndexTable[nInnerCode].pWordItemHead;
int nStart=0,nEnd=m_IndexTable[nInnerCode].nCount-1,nMid=(nStart+nEnd)/2,nCount=0,nCmpValue;
while(nStart<=nEnd)//Binary search
{
nCmpValue=strcmp(pItems[nMid].sWord,sWord);
//如果中间那个正好是要查找的
if(nCmpValue==0&&(pItems[nMid].nHandle==nHandle||nHandle==-1))
{
if(nPosRet)
{
if(nHandle==-1)//Not very strict match
{//Add in 2002-1-28
nMid-=1;
//Get the first item which match the current word
while(nMid>=0&&strcmp(pItems[nMid].sWord,sWord)==0)
nMid--;
if(nMid<0||strcmp(pItems[nMid].sWord,sWord)!=0)
nMid++;
}
*nPosRet=nMid;
return true;
}
if(nPosRet)
*nPosRet=nMid;
return true;//find it
}
else if(nCmpValue<0||(nCmpValue==0&&pItems[nMid].nHandle<nHandle&&nHandle!=-1))
{
nStart=nMid+1;
}
else if(nCmpValue>0||(nCmpValue==0&&pItems[nMid].nHandle>nHandle&&nHandle!=-1))
{
nEnd=nMid-1;
}
nMid=(nStart+nEnd)/2;
}
if(nPosRet)
{
//Get the previous position
*nPosRet=nMid-1;
}
return false;
}
//在修改表中查询
bool CDictionary::FindInModifyTable(int nInnerCode,char *sWord,int nHandle,PWORD_CHAIN *pFindRet)
{
PWORD_CHAIN pCur,pPre;
if(m_pModifyTable==NULL)//empty
return false;
pCur=m_pModifyTable[nInnerCode].pWordItemHead;
pPre=NULL;
//sWord相等且句柄(nHandle)相等
while(pCur!=NULL&&(_stricmp(pCur->data.sWord,sWord)<0||(_stricmp(pCur->data.sWord,sWord)==0&&pCur->data.nHandle<nHandle)))
//sort the link chain as alphabet
{
pPre=pCur;
pCur=pCur->next;
}
if(pFindRet)
*pFindRet=pPre;
if(pCur!=NULL && _stricmp(pCur->data.sWord,sWord)==0&&(pCur->data.nHandle==nHandle||nHandle<0))
{//The node exists, delete the node and return
return true;
}
return false;
}
得到词的类型,共三种汉字、分隔符和其他
int CDictionary::GetWordType(char *sWord)
{
int nType=charType((unsigned char *)sWord),nLen=strlen(sWord);
if(nLen>0&&nType==CT_CHINESE&&IsAllChinese((unsigned char *)sWord))
return WT_CHINESE;//Chinese word
else if(nLen>0&&nType==CT_DELIMITER)
return WT_DELIMITER;//Delimiter
else
return WT_OTHER;//other invalid
}