Google Perftools简介与使用
一. 安装与简介
从主页http://code.google.com/p/google-perftools/downloads/list下载源码包,解压后使用命令序列./configure;make;make install安装。如果make报错,请使用./configure --enable-frame-pointers从新来过。默认安装路径为/usr/local/,头文件和库文件分别在/usr/local/inlcude/google/和/usr/local/lib/下。需要设置环境变量export LD_LIBRARAY_PATH=/usr/local/lib。跟valgrind的profiler工具的不同之处是,Google perftools使用在源程序中插入profiler代码的方式,而不是valgrind的虚拟机方式,所以Google perftools以库文件的形式提供了一系列函数接口。为了使用图形化结果还需要安装gv,可使用apt-get安装:sudo apt-get install gv。
Google Perftools包括三个工具(注:包括tcmalloc应该是4个),三个工具均支持多线程程序,以下分别介绍。
Google Perftools简介与使用
朱泓丞 2009-08-07
一. 安装与简介
从主页http://code.google.com/p/google-perftools/downloads/list下载源码包,解压后使用命令序列./configure;make;make install安装。如果make报错,请使用./configure --enable-frame-pointers从新来过。默认安装路径为/usr/local/,头文件和库文件分别在/usr/local/inlcude/google/和/usr/local/lib/下。需要设置环境变量export LD_LIBRARAY_PATH=/usr/local/lib。跟valgrind的profiler工具的不同之处是,Google perftools使用在源程序中插入profiler代码的方式,而不是valgrind的虚拟机方式,所以Google perftools以库文件的形式提供了一系列函数接口。为了使用图形化结果还需要安装gv,可使用apt-get安装:sudo apt-get install gv。
Google Perftools包括三个工具,三个工具均支持多线程程序,以下分别介绍。
二. CPU profiler
通过cpu中断采样的方式来统计每个函数被采样的次数,占总采样次数的百分比,调用的子函数的被采样次数等。通过这些信息来找到程序的cpu性能瓶颈,从而有针对性的进行优化。
在要检测的程序的源文件中包含头文件google/profiler.h(默认全路径为/usr/local/include),并在需要统计的代码段前后调用函数ProfilerStop(char*)和ProfilerStop(),其中ProfilerStart的参数是输出profile的文件路径。注意,可以对多个代码段作profile,但是如果使用同样的输出文件,后一次 profile的输出会完全覆盖前一次的输出。然后编译源程序并使用-lprofiler连接选项得到链接了cpu profiler代码的可执行程序,这里推荐使用-O0编译选项,否则可能无法得到函数调用关系图。以后每次运行可执行程序,都会生成 profile输出文件,输出文件是人不可识别的二进制文件。CPU profiler采样的频率是可调的,设置环境变量CPUPROFILE_FREQUENCY来确定每秒钟的采样次数,默认为100。
输出的profile文件可以用工具pprof(一个perl程序)来方便的生成各种人可读的形式。下面以一个随机生成1000000个整数插入一个红黑树中的程序来演示ppro的使用,可执行程序名为RBtree,生成的profile文件名为RBTree.prof,作profile的代码段主要调用了RBTree::insert,RBtree::insertFixup和rand等函数。
pprof的使用形式都是: pprof --option [ --focus=<regexp> ] [ --ignore=<regexp> ] [--line or addresses or functions] 可执行文件路径 对应的profile路径。方括号中的项目是可选项目。<regexp>表示正则表达式。
option可取的值有:text,gv,dot,ps,pdf,gif,list=<regexp>,disasm=<regexp>。表示不同的输出形式。其中list=<regexp>表示输出匹配正则表达式的函数的源代码,diasm=<regexp>表示输出匹配正则表达式的函数的反汇编代码。text是字符统计输出形式,其它的对应不同的图形文件格式。
--focus=<regexp>表示只统计函数名匹配正则表达式的函数的采样,--ignore=<regexp>表示不统计函数名匹配正则表达式的函数的采样。
[--line or addresses or functions]表示生成的统计是基于代码行,指令地址还是函数的,默认是函数。
pprof --text ./RBtree ./RBtree.prof 生成的字符统计结果如下。
501 62.2% 62.2% 714 88.6% RBTree::insert
84 10.4% 72.6% 84 10.4% RBTree::defaultCmp
80 9.9% 82.5% 154 19.1% RBTree::nodeCmp
61 7.6% 90.1% 73 9.1% RBTree::insertFixup
47 5.8% 95.9% 47 5.8% malloc_trim
9 1.1% 97.0% 746 92.6% main
6 0.7% 97.8% 6 0.7% RBTree::rightRotate
6 0.7% 98.5% 6 0.7% RBTree::leftRotate
5 0.6% 99.1% 5 0.6% malloc
3 0.4% 99.5% 3 0.4% operator new
3 0.4% 99.9% 3 0.4% random_r
1 0.1% 100.0% 1 0.1% rand
0 0.0% 100.0% 755 93.7% __libc_start_main
每行对应一个函数的统计。第一,二列是该函数的本地采样(不包括被该函数调用的函数中的采样次数)次数和比例,第三列是该函数本地采样次数占当前所有已统计函数的采样次数之和的比例。第四,五列是该函数的累计采样次数(包括其调用的函数中的采样次数)和比例。
pprof --gif ./RBtree ./RBtree.prof > graph.gif 生成的gif统计图如下。
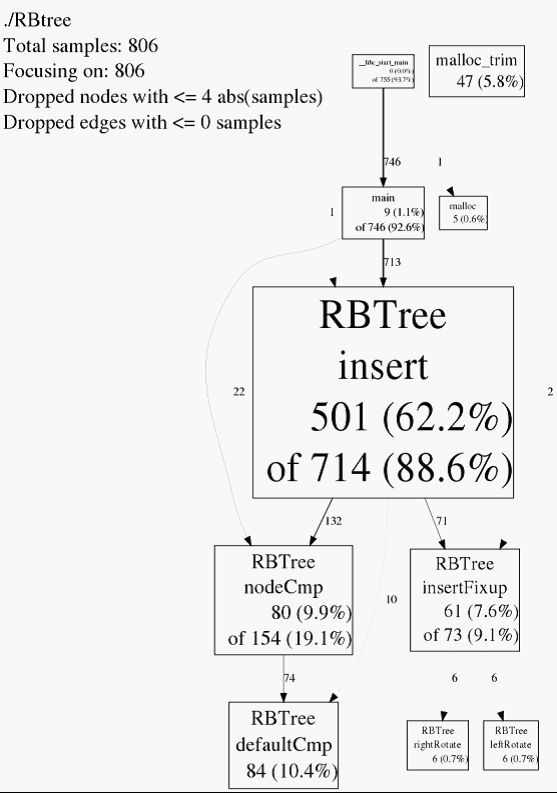
图中每个节点对应一个函数,节点中的文字分别为类名,函数明,本地采样次数比例和累计采样次数比例(如果跟本地相同则省略)。每条边表示一个函数调用关系:caller调用callee,边上的数字表示callee中因为caller调用而被采样的次数。
pprof如果不带任何选项调用(只有可执行文件路径和profile文件路径)则进入互动模式,在互动模式下可使用gv,gif,text等命令来替代前面介绍的带选项的pprof调用。
二. Heap Checker
堆内存泄漏检测工具。使用简单,先在链接被检查程序的时候用-ltcmalloc选项连接Goolge Perftools的堆内存管理库tcmalloc(tcmalloc会替代C的堆内存管理库),然后每次用命令行“env HEAPCHECK=normal 可执行程序路径”来进行检查,其中检查形式normal可以替换成其他值,检查的结果会以屏幕报告的形式给出。以下给出一个实例:
# cat test_heap_checker.cpp
#include <cstdio>
#include <cstdlib>
int* fun(int n)
{
int *p1=new int[n];
int *p2=new int[n];
return p2;
}
int main()
{
int n;
scanf("%d",&n);
int *p=fun(n);
delete [] p;
return 0;
}
# g++ -O0 -g test_heap_checker.cpp -ltcmalloc -o test_heap_checker
# env HEAPCHECK=normal /home/hongcheng/mycode/google-perftools-tests/test_heap_checker
WARNING: Perftools heap leak checker is active -- Performance may suffer
100
Have memory regions w/o callers: might report false leaks
Leak check _main_ detected leaks of 400 bytes in 1 objects
The 1 largest leaks:
Leak of 400 bytes in 1 objects allocated from:
If the preceding stack traces are not enough to find the leaks, try running THIS shell command:
pprof /home/hongcheng/mycode/google-perftools-tests/test_heap_checker "/tmp/test_heap_checker.13379._main_-end.heap" --inuse_objects --lines --heapcheck --edgefraction=1e-10 --nodefraction=1e-10 --gv
If you are still puzzled about why the leaks are there, try rerunning this program with HEAP_CHECK_TEST_POINTER_ALIGNMENT=1 and/or with HEAP_CHECK_MAX_POINTER_OFFSET=-1
Exiting with error code (instead of crashing) because of whole-program memory leaks
上面的报告显示有400个字节的内存泄漏,并提示使用pprof进一步跟踪泄漏来源的方法。
包括normal在内总共有4种泄漏检查方式:minimal,忽略进入main函数之前的初始化过程;normal,报告所有的无法再引用的内存对象;strick,在normal的基础上增加一些额外的检查;draconian,在程序退出的时候存在未释放的内存的情况下报错。
除了前面使用env命令行的全局内存泄漏检查方式外,还可以作对代码段的更加细粒度的泄漏检查。这里需要先在源代码中包含头文件google/heap-checker.h。下面是一个检查代码段的实例:
HeapLeakChecker heap_checker("test_foo");
{
code that exercises some foo functionality;
this code should preserve memory allocation state;
}
if (!heap_checker.SameHeap()) assert(NULL == "heap memory leak");
在进入代码段之前建立当前堆内存使用情况的snapshot,然后在结束代码段的时候通过与记录的snapshot对比检查是否有泄漏。方法NoLeaks()也可以用在这里。下面是一个实例:
#include <cstdio>
#include <cstdlib>
#include <cassert>
#include <google/heap-checker.h>
int* fun(int n)
{
int *p2;
HeapLeakChecker heap_checker("fun");
{
new int[n];
p2=new int[n];
//delete [] p1;
}
assert(!heap_checker.NoLeaks());
return p2;
}
int main(int argc,char* argv[])
{
int n;
scanf("%d",&n);
int *p=fun(n);
delete [] p;
return 0;
}
注意被检查程序的main函数形式必须为带2个参数的形式,否则会在编译时报告重复定义。运行env命令行将会报告assert失败。
另外,还可以跳过某些代码段的检查,方式如下:
{
HeapLeakChecker::Disabler disabler;
<leaky code>
}
<leaky code>处的代码将被heap-checker忽略。
三. Heap Profiler
堆内存使用情况统计工具。有两种使用方法。
1. 全局profile,在连接的时候使用-ltcmalloc选项,然后使用命令行“env HEAPPROFILE=prefix 可执行程序路径”来生成若干profile数据文件,这里的prefix是生成的profile文件的路径前缀。
2. 代码段profile,在源程序中包含头文件<google/heap-profiler.h>,然后调HeapProfilerStart(char* prefix),HeapProfilerStop(),
HeapProfilerDump(char* filename)和GetHeapProfile()函数来确定代码段,输出profile文件等。其中HeapProfilerStart的参数是周期性输出文件的前缀,HeapProfilerDump的参数是当前heap的profile输出文路径。
两种方式都会周期性生成 prefix.0000.heap, prefix.0001.heap一系列profile文件,用于进一步的分析。这里的周期性是指一旦一定数量的对内存被allocated就生成新的profile文件。环境变量HEAP_PROFILE_ALLOCATION_INTERVAL用于控制这一数量(单位为字节),默认为1GB。
可以用pprof程序处理生成的profile数据文件以身生成可读的文本或者图形统计文件,使用方法跟前面介绍的CPU profiler中的pprof几乎一样,除了采样次数被替换成申请的堆内存数量。