hadoop集群配置以及配置中遇到的问题详解
一、搭建hadoop集群环境,可以选择真实机器的搭建,也可以选择虚拟机的形式,作为练习,省的在好几个机子上跑来跑去,我选择了在三台虚拟机上搭建hadoop集群环境。
1、因为之前我已经搭建了hadoop单机模式,并且成功的运行了自带的wordcount例子,所以在搭建虚拟机集群模式的时候非常方便。
搭建好的单机模式,已经安装好了linux(CentOS)系统、JDK,配好了ssh,在该虚拟机(作为主机,名为master)power off的前提下,右击选择克隆,克隆出两个虚拟机,
作为分机,分别叫做slave1和slave2.现在三台机子已经准备好了,而且一些基本的配置也都OK。
单机配置模式具体步骤,可以查看下面的链接:
(一)配置hadoop-------vm虚拟机中安装CentOS5.5,并且安装和配置jdk1.6
(二)配置hadoop-------安装配置hadoop并且设置ssh
2、三台机子分别用root登录,输入ifconfig查看其IP地址。我的主机IP地址为:master:192.168.255130;分机IP地址为slave1:192.168.255.134,slave2:192.168.255.133
3、在三台机子上分别输入 vim /etc/hosts,添加主机名和IP地址还有两个分机的分机名和IP地址,我主机名命名为master,分机名命名为slave1和slave2:

注意:三台机子都要这么写!
保存后重启网络:输入:service network restart
二、ssh的配置
1、点击CentOS上方的”系统--管理--服务器设置--服务“,查看sshd服务是否运行。
2、在主机和两台分机上分别生成密码对:输入命令:ssh-keygen -t rsa
这时,在每个/home/hadoop目录下生成一个.ssh的文件夹(需要点击查看隐藏文件夹),里面产生了私钥和公钥:id_rsa和id_rsa.pub,更改.ssh的读写权限:输入命令:chmod 755 .ssh
3、在主机上,进入.ssh目录,输入命令:cp id_rsa.pub authorized_keys,将id_rsa.pub直接复制为authorized_keys(主机的公钥),
更改authorized_keys的读写权限:chmod 644 authorized_keys(这个不是必须,但保险起见,推荐使用)
4、将authorized_keys文件上传到两个分机上:输入命令:
scp authorized_keys hadoop@slave1:/home/hadoop/.ssh
scp authorized_keys hadoop@slave2:/home/hadoop/.ssh
输入cd,退出.ssh文件夹
输入命令:ssh slave1或者ssh slave2
这样,master主机就可以不需要密码登录到slave1和slave2了,退出分机,只需要输入exit就可以了。
5、在两个分机上,分别将之前产生的公钥id_rsa.pub复制到主机上的.ssh目录中,并且重命名为slave1.id_rsa.pub和slave2.id_rsa.pub为了好区分。
输入命令:scp -r id_rsa.pub hadoop@master:/home/hadoop/.ssh/slave1.id_rsa.pub,
scp -r id_rsa.pub hadoop@master:/home/hadoop/.ssh/slave2.id_rsa.pub
复制完毕后,此时,主机的/ssh文件夹中有authorized_keys,还有刚复制来的两个分机的公钥:slave1.id_rsa.pub和slave2.id_rsa.pub
现在对主机上已经存在的公钥信息authorized_keys进行追加:
在.ssh目录中,输入命令:cat slave1.id_rsa.pub >>authorized_keys,cat slave2.id_rsa.pub >>authorized_keys
这样,主机和两个分机之间就可以互相ssh而且不需要密码(同理,分机和分机之间也这样配置)。
6、hadoop集群部署
hadoop配置之前一定要先配置jdk,这点在单点配置中已经详细给出,此处不赘述。(略去jdk的配置和添加hadoop的路径)
配置主机master上hadoop/hadoop-0.20.0/conf文件夹中的4个文件:
(1)配置core-site.xml:

注意:需要先在/usr/java/hadoop目录下新建tmp文件夹(即:hadoop安装文件:hadoop-0.20.0.tar.gz文件存在的目录)
(2)配置mapred-site.xml:
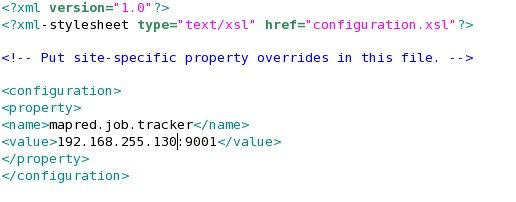
(3)配置hdfs-site.xml:

(4)配置masters文件:去掉原来的localhost,写:192.168.255.130
(5)配置slaves文件:去掉原来的localhost,写:192.168.255.134 192.168.255.133
7、将主机上的hadoop-0.20.0文件夹复制到两个分机对应的位置上。
至此,hadoop的配置结束。
8、在主机master上启动hadoop并且查看集群状态。
首先,格式化hadoop。

然后,启动hadoop,建议先启动dfs,输入命令:bin/start-dfs.sh,再启动mapred,输入命令:bin/start-mapred.sh,截图略。
(建议用bin/start-dfs.sh和bin/start-mapred.sh来代替start-all,同样,退出也是分别退出)
查看主机上的进程:

查看分机上的进程:
在主机上查看集群状态:输入命令:bin/hadoop dfsadmin -report
9、在hadoop上执行wordcount任务。(同单机的运行,不赘述)
可能出现的问题:
问题一:hadoop格式化失败:报错:cannot create directory /usr/java/hadoop/tmp/dfs/name/current
首先检查在/usr/java/hadoop/目录下是否建立了文件夹tmp,然后检查是以哪一个用户身份建立的,有可能tmp文件夹的建立是在root下建立的,因此hadoop普通用户没有权限进行读写。
解决方法:在/usr/java/hadoop/目录下,输入命令:chmod 777 -R /tmp
问题二:hadoop格式化成功,但是datanode启动失败(在分机上jps没有出现datanode)。
解决方法:删除所有的tmp文件和logs文件。tmp文件在/usr目录下有一个,另外一个就是问题一提到的那个tmp文件夹。logs文件夹在/usr/java/hadoop/hadoop-0.20.0目录下。
还有一种可能性就是,/usr/java/hadoop/tmp中的tmp文件夹是root下建立的,hadoop用户没有权限写入,也会出现datanode启动失败,我是在logs文件中查看到的。(出问题要看日志文件)。
解决办法:在/usr/java/hadoop/目录下,输入命令:chown -R hadoop:hadoop(用户名:用户组)tmp(文件夹)即可。
问题三:在如上的第8步骤中,在hadoop用户下格式化namenode,会报错权限不够,然后会打印出很多诸如,权限不足,无法打开文件,文件不存在之类之类,原因是因为我们在安装hadoop(其实也就是解压hadoop安装文件的过程)和新建文件夹是在root下执行的(这点需要非常小心),那么hadoop用户是没有权限使用的,这时,需要这个万能的命令(帮了我的大忙啊~~~~~~)
在/usr/java/hadoop/目录下,输入命令: chown -R hadoop:hadoop(用户名:用户组)hadoop-0.20.0(文件夹),然后一切问题OK。
此外,需要说明和强调的一点是,linux的权限问题是个很头疼的事情(我想,很多人觉得linux安全也是出于linux权限多多的情况吧),整个集群的配置(包括安装jdk,ssh的配置,hadoop安装配置那块),可以全部在root下完成,但是最后一定要记得将对应文件夹的权限给hadoop用户才可以!!!!!!!!!但是也许这时候就有人说,既然这么麻烦,为什么不所有的操作都让root用户完成呢,还要新建普通用户干嘛,是因为root用户可以修改系统的配置,如果大家都有权限修改,那么系统就会乱套而且也不安全!
此外可以参考下面的连接:http://wenku.baidu.com/view/20e9043a87c24028915fc368.html
http://developer.51cto.com/art/201206/344046_1.htm