OpenCV源码解析之动态内存管理CvMemStorage与CvSeq
1. CvMemStorage
一个对象性不强的结构体,它的作用还是在和CvSeq、文件读取等配合中体现出的。
1.1 CvMemStorage结构图
1.2CvMemStorage
定义于core模块下的types_c.h:
typedef struct CvMemStorage
{
int signature;
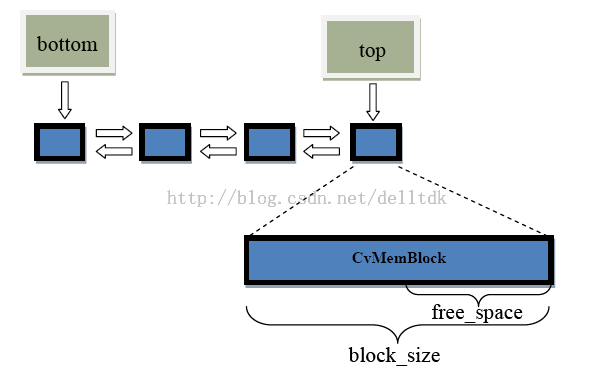
CvMemBlock* bottom; /* First allocatedblock. */
CvMemBlock* top; /* Current memory block -top of the stack. */
struct CvMemStorage* parent; /* We get new blocks from parent as needed. */
int block_size; /* Block size. */
int free_space; /* Remaining free space in current block. */
}
CvMemStorage;
内存存储器是一个可用来存储诸如序列,轮廓,图形,子划分等动态增长数据结构的底层结构。它是由一系列以同等大小的内存块构成,呈列表型---bottom 域指的是列首,top域指的是当前指向的块但未必是列尾.在bottom和top之间所有的块(包括bottom,不包括top)被完全占据了空间;在top和列尾之间所有的块(包括块尾,不包括top)则是空的;而top块本身则被占据了部分空间--free_space指的是top块剩余的空字节数。新分配的内存缓冲区(或显示的通过cvMemStorageAlloc 函数分配,或隐示的通过cvSeqPush,cvGraphAddEdge等高级函数分配)总是起始于当前块(即top块)的剩余那部分,如果剩余那部分能满足要求(够分配的大小)。分配后,free_space就减少了新分配的那部分内存大小,外加一些用来保存适当列型的附加大小。当top块的剩余空间无法满足被分配的块(缓冲区)大小时,top块的下一个存储块被置为当前块(新的top块)-- free_space被置为先前分配的整个块的大小。如果已经不存在空的存储块(即:top块已是列尾),则必须再分配一个新的块(或从parent那继承,见cvCreateChildMemStorage)并将该块加到列尾上去。于是,存储器(memorystorage)就如同栈(Stack)那样,bottom指向栈底,(top,free_space)对指向栈顶。栈顶可通过cvSaveMemStoragePos保存,通过cvRestoreMemStoragePos恢复指向,通过 cvClearStorage重置。
1.3 CvMemBlock
内存存储块结构
typedef struct CvMemBlock
{
struct CvMemBlock* prev;
struct CvMemBlock* next;
}
CvMemBlock;CvMemBlock 代表一个单独的内存存储块结构。内存存储块中的实际数据存储在header块之后(即:存在一个头指针 head指向的块 header ,该块不存储数据),于是,内存块的第i 个字节可以通过表达式 ((char*)(mem_block_ptr+1))[i]获得。然而,通常没必要直接去获得存储结构的域。
1.4 CvMemStoragePos
内存存储块地址
typedef struct CvMemStoragePos
{
CvMemBlock* top;
int free_space;
}
CvMemStoragePos;
该结构(如以下所说)保存栈顶的地址,栈顶可以通过 cvSaveMemStoragePos保存,也可以通过 cvRestoreMemStoragePos 恢复。
CvMemStorage的相关函数定义在core模块下的datastructs.cpp中。接下来一一分析。
1.5 cvCreateMemStorage
这里仅仅生成一个CvMemStorage类指针并初始化。
/* Initialize allocated storage: */
static void
icvInitMemStorage( CvMemStorage* storage, int block_size )
{
if( !storage )
CV_Error(CV_StsNullPtr, "");
if( block_size <= 0 )
block_size= CV_STORAGE_BLOCK_SIZE; // (1 << 16) – 128 = 65408
block_size = cvAlign(block_size, CV_STRUCT_ALIGN); // CV_STRUCT_ALIGN = //sizeof(double) = 8
// 此处cvAlign以(align & (align-1)) == 0检验align,并以(size + align -1)&-align返回对齐//后的size,值得学习的是size&-align为对align的左对齐
assert( sizeof(CvMemBlock)% CV_STRUCT_ALIGN == 0 );
memset( storage, 0, sizeof(*storage )); // core初始化为0
storage->signature = CV_STORAGE_MAGIC_VAL;
storage->block_size= block_size;
}
但在这里要着重分析下cvAlloc,这和下面cvReleaseMemStorage中的cvFree是相呼应的。
CV_IMPL void* cvAlloc( size_t size )
{
returncv::fastMalloc( size );
}
void* fastMalloc(size_t size)
{
uchar* udata = (uchar*)malloc(size + sizeof(void*) + CV_MALLOC_ALIGN);
// 此处多分配了sizeof(void*)+CV_MALLOC_ALIGN的空间,毫无疑问后者//是为了对齐而预留的部分空间(在后面也证实了);前者的用意是为了保存一//个指向这片内存空间的地址
if(!udata)
return OutOfMemoryError(size);
uchar** adata = alignPtr((uchar**)udata +1, CV_MALLOC_ALIGN);
adata[-1]= udata;// 分配的空间地址被保存在这段内存的起始位置
return adata;// 返回的是可用的空间地址
}
1.6 cvReleaseMemStorage
代码如下:
/*Release memory storage: */
CV_IMPL void
cvReleaseMemStorage( CvMemStorage**storage )
{
if( !storage )
CV_Error(CV_StsNullPtr, "");
CvMemStorage*st = *storage;
*storage= 0;
if( st )
{
icvDestroyMemStorage(st );
cvFree(&st );
}
}
/*Release all blocks of the storage (or return them to parent, if any): */
static void
icvDestroyMemStorage( CvMemStorage*storage )
{
int k = 0;
CvMemBlock*block;
CvMemBlock*dst_top = 0;
if( !storage )
CV_Error(CV_StsNullPtr, "");
if( storage->parent)
dst_top= storage->parent->top;
for( block = storage->bottom; block!= 0; k++ )
{
CvMemBlock *temp= block;
block= block->next;
if( storage->parent)
{
if(dst_top )
{
temp->prev = dst_top;
temp->next = dst_top->next;
if(temp->next)
temp->next->prev =temp;
dst_top= dst_top->next= temp;// 以上部分将block插入到parent的top之后
}
else
{
dst_top= storage->parent->bottom = storage->parent->top= temp;
temp->prev = temp->next = 0;
storage->free_space = storage->block_size - sizeof(*temp );// 上面没有修正free_space的原因是这个值没有变
}
}
else
{
cvFree(&temp );
}
}
storage->top = storage->bottom = 0;
storage->free_space = 0;
}
最终都调用到cvFree宏函数。其中的关系是cvFree->cvFree_->cv::fastFree:
void fastFree(void* ptr) // 与fastAlloc对应
{
if(ptr)
{
uchar*udata = ((uchar**)ptr)[-1]; // 取出在fastAlloc中多分配的存储内存地址的指针
CV_DbgAssert(udata< (uchar*)ptr&&
((uchar*)ptr - udata)<= (ptrdiff_t)(sizeof(void*)+CV_MALLOC_ALIGN));
free(udata); // 调用free释放这段分配的内存
}
}
没有直接使用ptr,而是用ptr[-1]来存储分配内存的地址,这样的机制使得通过cvAlloc分配的空间只能使用cvFree来释放,如果直接free就会造成内存泄露;而如果malloc之后使用cvFree,ptr与ptr-1不连续,调用就会失败,抛出警告。
1.7 cvClearMemStorage
修改top和free_space指向bottom
1.8 cvMemStorageAlloc
/*Allocate continuous buffer of the specified size in the storage: */
CV_IMPL void*
cvMemStorageAlloc( CvMemStorage*storage, size_tsize )
{
schar *ptr = 0;
if( !storage )
CV_Error(CV_StsNullPtr, "NULLstorage pointer" );
if( size > INT_MAX)
CV_Error(CV_StsOutOfRange, "Toolarge memory block is requested" );
assert( storage->free_space% CV_STRUCT_ALIGN == 0 );
if( (size_t)storage->free_space < size) //当前topMemBlock中的自由空间不足时
{
size_tmax_free_space = cvAlignLeft(storage->block_size- sizeof(CvMemBlock),CV_STRUCT_ALIGN);// 计算对齐后的剩余空间最多能够有多大
if( max_free_space < size) // 如果要分配的空间很大或者参数错误是个负数
CV_Error(CV_StsOutOfRange, "requestedsize is negative or too big" );
icvGoNextMemBlock(storage ); // 创建一个新的MemBlock
}
ptr = ICV_FREE_PTR(storage);// 宏函数找到当前free space的首地址
assert((size_t)ptr% CV_STRUCT_ALIGN == 0 );
storage->free_space = cvAlignLeft(storage->free_space- (int)size,CV_STRUCT_ALIGN );//不需要再做内存分配,只要更新free_space即可
return ptr;
}
其中的icvGoNextMemBlock是在top之后添加一个MemBlock,并更新top至新添加的MemBlock,更新free_space,维护一个MemBlock的双向链表
1.9 cvMemStorageAllocString
调用cvMemStorageAlloc分配存储字符串的空间(len+1),+1是为了储存字符串结束符,然后将字符串copy进该段空间
1.10 cvSaveMemStoragePos
将top和free_space保存至CvMemStoragePos结构中
1.11 cvRestoreMemStoragePos
将CvMemStoragePos中的信息恢复进MemStorage,如果Pos中保存的是top地址为空,相当于将MemStorage进行clear操作
2. CvSeq
2.1 CvSeq结构图
CvSeq的定义同样出现在types_c.h中:
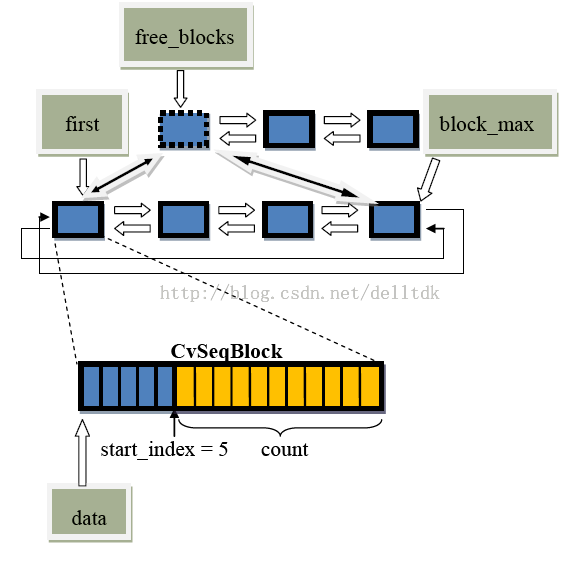
typedef struct CvSeqBlock
{
struct CvSeqBlock* prev; /*Previous sequence block. */
struct CvSeqBlock* next; /*Next sequence block. */
int start_index; /* Index ofthe first element in the block + */
/* sequence->first->start_index.*/
int count; /*Number of elements in the block. */
schar* data; /* Pointer to the first element of the block.*/
}
CvSeqBlock;
#define CV_TREE_NODE_FIELDS(node_type) \
int flags; /*Miscellaneous flags. */ \
int header_size; /* Size ofsequence header. */ \
struct node_type*h_prev; /*Previous sequence. */ \
struct node_type*h_next; /* Nextsequence. */ \
struct node_type*v_prev; /* 2ndprevious sequence. */ \
struct node_type*v_next /* 2nd next sequence. */
/*
Read/Write sequence.
Elements can be dynamically inserted to ordeleted from the sequence.
*/
#define CV_SEQUENCE_FIELDS() \
CV_TREE_NODE_FIELDS(CvSeq); \
int total; /* Totalnumber of elements. */ \
int elem_size; /* Size ofsequence element in bytes. */ \
schar* block_max; /* Maximalbound of the last block. */ \
schar* ptr; /*Current write pointer. */ \
int delta_elems; /* Grow seq thismany at a time. */ \
CvMemStorage*storage; /* Where the seq is stored. */ \
CvSeqBlock*free_blocks; /* Free blocks list. */ \
CvSeqBlock*first; /* Pointer to the first sequence block. */
typedef struct CvSeq
{
CV_SEQUENCE_FIELDS()
}CvSeq;
仅仅从结构上理解这个struct是不准确的,因为主要是CvSeq在使用中的内存管理才是关键。以下方法多定义在datastructs.cpp内。
2.2 cvCreateSeq
/*Create empty sequence: */
CV_IMPL CvSeq*
cvCreateSeq( int seq_flags, size_theader_size, size_telem_size, CvMemStorage*storage )
{
CvSeq *seq = 0;
if( !storage )
CV_Error(CV_StsNullPtr, "");
if( header_size < sizeof(CvSeq ) || elem_size<= 0 )
CV_Error(CV_StsBadSize, "");
/* allocatesequence header */
seq = (CvSeq*)cvMemStorageAlloc(storage, header_size);
memset( seq, 0, header_size);
seq->header_size = (int)header_size;
seq->flags = (seq_flags& ~CV_MAGIC_MASK) | CV_SEQ_MAGIC_VAL;
{
int elemtype = CV_MAT_TYPE(seq_flags);
int typesize = CV_ELEM_SIZE(elemtype);
if( elemtype != CV_SEQ_ELTYPE_GENERIC&& elemtype != CV_USRTYPE1 &&
typesize!= 0 && typesize != (int)elem_size )
CV_Error(CV_StsBadSize,
"Specifiedelement size doesn't match to the size of the specified element type "
"(tryto use 0 for element type)" );
}
seq->elem_size = (int)elem_size;
seq->storage = storage;
cvSetSeqBlockSize(seq, (int)((1<< 10)/elem_size) );// 设定delta_elems,表示当Seq中的空间不足时,增加多大空间,这里设定的delta_elems是((1<< 10)/elem_size)和cvAlignLeft(seq->storage->block_size- sizeof(CvMemBlock) -sizeof(CvSeqBlock), CV_STRUCT_ALIGN)的最小值,此处保留一个疑问:难道CvSeq在CvMemStorage中的保存位置是在每一个CvMemBlock的MemBlock之外?
return seq;
}
2.3 cvCloneSeq
clone函数调用cvSeqSlice函数,该函数是根据CvSlice中给出的起始index以及是否copy数据,取出CvSeq的一部分作为CvSeq结构返回。而clone在调用时将结束位置设置到最大,将起始位置设置为0,并且永远进行数据copy。
CV_INLINE CvSeq*cvCloneSeq( constCvSeq* seq,CvMemStorage* storageCV_DEFAULT(NULL))
{
return cvSeqSlice( seq, CV_WHOLE_SEQ,storage, 1 );
}
通过cvSeqSlice的代码梳理,可以看出CvSeq中的CvSeqBlock所形成的双向链表是一个封闭的环形,也就是说first->prev保存的是最后一个CvSeqBlock的地址
CV_IMPL CvSeq*
cvSeqSlice( const CvSeq* seq, CvSlice slice, CvMemStorage* storage,int copy_data)
{
CvSeq* subseq = 0;
int elem_size, count,length;
CvSeqReaderreader;
CvSeqBlock*block, *first_block= 0, *last_block = 0;
if( !CV_IS_SEQ(seq))
CV_Error(CV_StsBadArg, "Invalidsequence header" );
if( !storage )
{
storage= seq->storage;
if( !storage )
CV_Error(CV_StsNullPtr, "NULLstorage pointer" );
}
elem_size= seq->elem_size;
length =cvSliceLength( slice,seq );// 此处在length的计算中同样可以看出cvseq内部的环形结构,因为index=index+cvSeq->total
if( slice.start_index< 0 )
slice.start_index += seq->total;
else if( slice.start_index >= seq->total )
slice.start_index -= seq->total;
if( (unsigned)length> (unsigned)seq->total ||
((unsigned)slice.start_index>= (unsigned)seq->total && length!= 0) )
CV_Error(CV_StsOutOfRange, "Badsequence slice" );
subseq =cvCreateSeq( seq->flags, seq->header_size, elem_size,storage );//创建一个新的CvSeq
if( length > 0 )
{
cvStartReadSeq(seq, &reader,0 );//初始化CvSeqReader
cvSetSeqReaderPos(&reader, slice.start_index, 0 );//根据给出的起始index将CvSeqReader更新到当前的index下
count= (int)((reader.block_max - reader.ptr)/elem_size);//当前block中剩余的元素数
do
{
intbl = MIN(count, length);
if(!copy_data )
{//仅copy了CvSeq中的结构,而没有数据
block= (CvSeqBlock*)cvMemStorageAlloc(storage, sizeof(*block) );
if(!first_block )
{
first_block= subseq->first= block->prev= block->next= block;
block->start_index = 0;//构建仅有一个seqBlock的环
}
else
{
block->prev = last_block;
block->next = first_block;
last_block->next = first_block->prev = block;
block->start_index = last_block->start_index + last_block->count;//在最后加入新建的seqBlock并更新指针构成新的环路
}
last_block= block;
block->data = reader.ptr;
block->count = bl;
subseq->total += bl;
}
else
cvSeqPushMulti(subseq, reader.ptr, bl, 0 );//需要copy数据时,用reader在CvSeq中读取并附加到subseq队尾
length-= bl;
reader.block = reader.block->next;
reader.ptr = reader.block->data;
count= reader.block->count;//更新reader的位置
}
while( length > 0 );
}
return subseq;
}
为了进一步理解CvSeq中的CvSeqBlock的环形结构,可以看到cvSetSeqReaderPos函数中有这样一段:
if( index+ index <= total)// 如果index处于所有element的前半部分,block向后移动
{
do
{
block= block->next;
index-= count;
}
while( index >= (count= block->count));
}
else// 如果index处于所有element的后半部分,block向前移动
{
do
{
block= block->prev;
total-= block->count;
}
while( index < total);
index -= total;
}
2.4 cvSeqInvert
在CvSeq中在before_index之前插入一个元素,当before_index处于序列后半部分时,如果空间不足在队尾增加一个block,并移动befor_index之后的元素后移;如果处于序列的前半部分,遇到空间不足时,在队首增加一个block,更新所有block的start_index,并将before_index的前面的元素前移来保持队形。
/*Insert new element in middle of sequence: */
CV_IMPL schar*
cvSeqInsert( CvSeq*seq, int before_index, constvoid *element)
{
int elem_size;
int block_size;
CvSeqBlock*block;
int delta_index;
int total;
schar* ret_ptr = 0;
if( !seq )
CV_Error(CV_StsNullPtr, "");
total = seq->total;
before_index+= before_index < 0 ? total : 0;
before_index-= before_index > total ? total : 0;// 以total为周期纠正befor_index
if( (unsigned)before_index> (unsigned)total)
CV_Error(CV_StsOutOfRange, "");
if( before_index == total)
{
ret_ptr= cvSeqPush( seq,element );
}
else if( before_index== 0 )
{
ret_ptr= cvSeqPushFront( seq,element );
}
else // 在序列中间插入一个元素
{
elem_size= seq->elem_size;
if( before_index >= total>> 1 ) // 要插入的元素位置在序列后半部分时
{
schar*ptr = seq->ptr + elem_size;
if(ptr > seq->block_max )//如果在当前写入点向后移动一个元素位置后会超出seq的边界,就要增加一个block并且写入点后移
{
icvGrowSeq(seq, 0 );
ptr= seq->ptr+ elem_size;
assert(ptr <= seq->block_max );
}
delta_index= seq->first->start_index;
block= seq->first->prev;
block->count++;
block_size= (int)(ptr- block->data);
while(before_index < block->start_index - delta_index)
{// 由block从后向前,每一个写入位置之后的block中,将自己的前n-1个元素向后移动一个元素位置,并从前一个block中取出最后一个元素copy至自己的第一个元素位置
CvSeqBlock*prev_block = block->prev;
memmove(block->data+ elem_size, block->data, block_size- elem_size );
block_size= prev_block->count* elem_size;
memcpy(block->data,prev_block->data+ block_size - elem_size,elem_size );
block= prev_block;
/*Check that we don't fall into an infinite loop: */
assert(block != seq->first->prev);
}
before_index= (before_index - block->start_index + delta_index)* elem_size;
memmove(block->data+ before_index + elem_size,block->data+ before_index,
block_size- before_index - elem_size); // 将当前block中before_index本身及之后的元素向后移动
ret_ptr= block->data+ before_index;
if(element )
memcpy(ret_ptr, element,elem_size );// 将要插入的元素放入更新后的当前位置,并且更新写入点
seq->ptr = ptr;
}
else
{
block= seq->first;
if(block->start_index== 0 )
{
icvGrowSeq(seq, 1 );
block= seq->first;
}
//当要插入元素位于序列前半部分时,直接先在队首增加一个block,增加之后first->start_index为这个新增block能够保存的元素数
delta_index= block->start_index;
block->count++;
block->start_index--;
block->data -= elem_size;// 移出保存新元素的空间
while(before_index > block->start_index - delta_index+ block->count)
{// 此处与前面向后移动是相似的
CvSeqBlock*next_block = block->next;
block_size= block->count* elem_size;
memmove(block->data,block->data+ elem_size, block_size- elem_size );
memcpy(block->data+ block_size - elem_size,next_block->data,elem_size );
block= next_block;
/*Check that we don't fall into an infinite loop: */
assert(block != seq->first );
}
before_index= (before_index - block->start_index + delta_index)* elem_size;
memmove(block->data,block->data+ elem_size, before_index- elem_size );
ret_ptr= block->data+ before_index - elem_size;
if(element )
memcpy(ret_ptr, element,elem_size );
}
seq->total = total +1;
}
return ret_ptr;
}
2.5 cvSeqSort
该函数通过传递的比较函数指针,对其中的元素进行排序
2.6 cvSeqSearch
在序列中查找特定元素:如果给出了cmp_func,将按照cmp_func将元素与elem对比,如果没有给出对比函数,则在序列中查找完全等于elem内容的元素。idx中存储的是元素id,userdata是为了协助cmp_func作为传入参数,is_sorted指明当前的序列是否已经经过排序,如果已经排序,使用二分查找;如果没有排序,则通过遍历查找。
2.7 cvSeqInvert
顾名思义,将CvSeq中的元素倒置,本质就是一个循环双向链表的倒置
2.8 cvClearSeq
这里仅仅调用了cvSeqPopMulti将所有元素弹出,具体的内存空间仍存在于seq的storage中,并没有被释放。当cvClearMemStorage和cvRestoreMemStoragePos均没有被调用时,这段空间仍可以被当前名称的CvSeq使用。
2.9 cvSeqPush
该部分代码比较简单,可以直接看下面的代码,唯一注意的是它会返回一个指向已经插入了的元素的指针
/*Push element onto the sequence: */
CV_IMPL schar*
cvSeqPush( CvSeq*seq, const void *element )
{
schar *ptr = 0;
size_t elem_size;
if( !seq )
CV_Error(CV_StsNullPtr, "");
elem_size= seq->elem_size;
ptr = seq->ptr;
if( ptr >= seq->block_max )
{
icvGrowSeq(seq, 0 );
ptr= seq->ptr;
assert(ptr + elem_size<= seq->block_max/*&& ptr == seq->block_min */ );
}
if( element )
memcpy(ptr, element,elem_size );
seq->first->prev->count++;
seq->total++;
seq->ptr = ptr + elem_size;
return ptr;
}
2.10 cvSeqPop
弹出一个序列尾部的元素至element中,弹出后如果最后一个block中不包含元素时将被CvSeq释放,但该空间仍在storage中,并没有真正释放
/*Pop last element off of the sequence: */
CV_IMPL void
cvSeqPop( CvSeq*seq, void *element )
{
schar *ptr;
int elem_size;
if( !seq )
CV_Error(CV_StsNullPtr, "");
if( seq->total<= 0 )
CV_Error(CV_StsBadSize, "");
elem_size= seq->elem_size;
seq->ptr = ptr = seq->ptr - elem_size;
if( element )
memcpy(element, ptr,elem_size );
seq->ptr = ptr;
seq->total--;
if( --(seq->first->prev->count)== 0 )
{
icvFreeSeqBlock(seq, 0 );
assert(seq->ptr== seq->block_max);
}
}
2.11 cvSeqPushFront
在序列首增加一个元素,这里的处理上与cvSeqInsert有很大相似,主要的关注点是在队首的start_index的维护上
/*Push element onto the front of the sequence: */
CV_IMPL schar*
cvSeqPushFront( CvSeq*seq, const void *element )
{
schar* ptr = 0;
int elem_size;
CvSeqBlock*block;
if( !seq )
CV_Error(CV_StsNullPtr, "");
elem_size= seq->elem_size;
block = seq->first;
if( !block || block->start_index == 0 )
{
icvGrowSeq(seq, 1 );
block= seq->first;
assert(block->start_index> 0 );
}
ptr = block->data-= elem_size;
if( element )
memcpy(ptr, element,elem_size );
block->count++;
block->start_index--;
seq->total++;
return ptr;
}
2.12 cvSeqPopFront
这里与cvSeqPop的区别是两个地方:一是通过first->start_index来pop第一个元素;二是pop后检查的是第一个block是否不再包含元素,是否需要被CvSeq释放
/*Shift out first element of the sequence: */
CV_IMPL void
cvSeqPopFront( CvSeq*seq, void *element )
{
int elem_size;
CvSeqBlock*block;
if( !seq )
CV_Error(CV_StsNullPtr, "");
if( seq->total<= 0 )
CV_Error(CV_StsBadSize, "");
elem_size= seq->elem_size;
block = seq->first;
if( element )
memcpy(element, block->data, elem_size);
block->data += elem_size;
block->start_index++;
seq->total--;
if( --(block->count)== 0 )
icvFreeSeqBlock(seq, 1 );
}
2.13 cvSeqPushMulti
/*Add several elements to the beginning or end of a sequence: */
//front 表示累加的元素是在sequence的队首还是队尾
CV_IMPL void
cvSeqPushMulti( CvSeq*seq, const void *_elements, int count, int front )
{
char *elements = (char*) _elements;
if( !seq )
CV_Error(CV_StsNullPtr, "NULLsequence pointer" );
if( count < 0 )
CV_Error(CV_StsBadSize, "numberof removed elements is negative" );
int elem_size = seq->elem_size;
if( !front )
{ // 叠加到队尾
while( count > 0 )
{
intdelta = (int)((seq->block_max- seq->ptr)/ elem_size);// 当前sequence block还能存储多少element
delta= MIN( delta,count );
if(delta > 0 )
{
seq->first->prev->count += delta;// 最后一个block内的count增加delta
seq->total += delta;// 整体增加delta个元素
count-= delta;
delta*= elem_size;
if(elements )
{
memcpy(seq->ptr,elements, delta);// 将数据copy进新增元素内
elements+= delta;
}
seq->ptr += delta;
}
if(count > 0 )
icvGrowSeq(seq, 0 );// 在队尾的自由空间中新增一个sequence block,如果不足就分配新的空间
}
}
else
{
CvSeqBlock*block = seq->first;
while( count > 0 )
{
intdelta;
if(!block || block->start_index == 0 )
{
icvGrowSeq(seq, 1 );
block= seq->first;
assert(block->start_index> 0 );
}
delta= MIN( block->start_index, count);
count-= delta;
block->start_index -= delta;
block->count += delta;
seq->total += delta;
delta*= elem_size;
block->data -= delta;
if(elements )
memcpy(block->data,elements + count*elem_size, delta);
}
}
}
2.14 cvSeqPopMulti
该部分不做讨论,作用就是在CvSeq的末尾弹出需要的n个元素至传入的地址空间内。需要展开的是其中的icvFreeSeqBlock函数,因为这其中涉及到CvSeq的内存是如何被回收的。回收过程分为三种情况:只有一个CvSeqBlock/有多个block回收最后一个/有多个block回收第一个。
/* Recycle a sequence block: */
static void
icvFreeSeqBlock( CvSeq *seq, int in_front_of )
{
CvSeqBlock*block = seq->first;
assert((in_front_of ? block: block->prev)->count == 0 );
if( block == block->prev ) /* single block case 仅包含一个CvSeqBlock*/
{
block->count = (int)(seq->block_max- block->data)+ block->start_index* seq->elem_size;
block->data = seq->block_max - block->count;
seq->first = 0;
seq->ptr = seq->block_max = 0;
seq->total = 0;// 更新一个block的data/count以及seq的first/ptr/total
}
else
{
if( !in_front_of )
{
block= block->prev;
assert(seq->ptr== block->data);
block->count = (int)(seq->block_max- seq->ptr);
seq->block_max = seq->ptr = block->prev->data +
block->prev->count* seq->elem_size;// 仅更新末尾block的count和seq的ptr/block_max
}
else
{
intdelta = block->start_index;
block->count = delta *seq->elem_size;
block->data -= block->count;// first block的data置为其首地址
/* Updatestart indices of sequence blocks: */
for(;; )
{
block->start_index -= delta;
block= block->next;
if(block == seq->first )
break;
}
seq->first = block->next;
}
block->prev->next =block->next;
block->next->prev =block->prev;// 在循环列表中去掉first block
}
assert( block->count> 0 && block->count % seq->elem_size == 0 );
block->next = seq->free_blocks;
seq->free_blocks = block;// 将回收的block添加到seq下free_blocks的队首
}
通过以上回收一个CvSeqBlock可以看出,CvSeq虽然做了很多内存管理的工作,但究其根本,仍然是在CvMemStorage分配的空间里维护着自己的一个CvSeqBlock的双向循环列表。它只是在内存不足时会要求CvMemStorage为他继续分配内存,而其他时候内存空间既不会释放也不会再增加。
2.15 cvSeqRemove
此处与cvSeqInsert只是一个逆过程,并在最后做是否需要CvSeq需要释放空block的检查
2.16 cvGetSeqElem
这个函数对于理解CvSeq的结构有所帮助,所以也将代码拿来:
/*Find a sequence element by its index: */
CV_IMPL schar*
cvGetSeqElem( const CvSeq *seq, int index )
{
CvSeqBlock*block;
int count, total = seq->total;
if( (unsigned)index>= (unsigned)total)
{
index+= index < 0 ? total: 0;
index-= index >= total? total : 0;
if( (unsigned)index>= (unsigned)total)
return0;
}
block = seq->first;
if( index + index<= total )
{
while( index >= (count= block->count))
{
block= block->next;
index-= count;
}
}
else
{
do
{
block= block->prev;
total-= block->count;
}
while( index < total);
index-= total;
}
return block->data+ index * seq->elem_size;
}
2.17 cvSeqElemIdx
该函数给出元素的指针element然后返回其在CvSeq中的id以及所在block的指针。
2.18 cvStartAppendToSeq、cvStartWriteSeq、cvEndWirteSeq
cvStartWriteSeq将调用cvStartAppendToSeq,就是先初始化创建一个CvSeq结构,然后将writer初始化。之后可以通过宏CV_WRITE_SEQ_ELEM来将数据写入序列。cvEndWriteSeq则作为这一写入过程的结束操作。
1. CvMemStorage* storage = cvCreateMemStorage(0);
2. CvSeq* seq = cvCreateSeq(CV_32SC1,sizeof(CvSeq),sizeof(int),storage);
3. CvSeqWriter writer;
4. CvSeqReader reader;
5. int i;
6. cvStartAppendToSeq(seq,&writer);
7. for (i=0;i<10;i++)
8. {
9. int val = rand() % 100;
10. CV_WRITE_SEQ_ELEM(val,writer);
11. printf("%d is written\n",val);
12. }
13. cvEndWriteSeq(&writer);
cvStartWriteSeq相当于其中的先cvCreateSeq然后再cvStartAppendToSeq。
2.19 cvStartReadSeq
首先来看CvSeqReader的定义:
#define CV_SEQ_READER_FIELDS() \
int header_size; \
CvSeq* seq; /* sequence,beign read */ \
CvSeqBlock* block; /* currentblock */ \
schar* ptr; /* pointer toelement be read next */ \
schar* block_min; /* pointer to thebeginning of block */\
schar* block_max; /* pointer to theend of block */ \
int delta_index;/* = seq->first->start_index */ \
schar* prev_elem; /* pointer toprevious element */
typedef struct CvSeqReader
{
CV_SEQ_READER_FIELDS()
}
CvSeqReader;
而cvStartReadSeq仅仅是对CvSeqReader结构的初始化而已,参数reverse表示是从后往前读(!=0),还是从前往后读(==0)
/*Initialize sequence reader: */
CV_IMPL void
cvStartReadSeq( const CvSeq *seq, CvSeqReader * reader,int reverse)
{
CvSeqBlock*first_block;
CvSeqBlock*last_block;
if( reader )
{
reader->seq = 0;
reader->block = 0;
reader->ptr = reader->block_max = reader->block_min = 0;
}
if( !seq || !reader)
CV_Error(CV_StsNullPtr, "");// 以上均为检验
reader->header_size = sizeof(CvSeqReader );
reader->seq = (CvSeq*)seq;
first_block= seq->first;
if( first_block )
{
last_block= first_block->prev;
reader->ptr = first_block->data;
reader->prev_elem = CV_GET_LAST_ELEM(seq, last_block);
reader->delta_index = seq->first->start_index;
if( reverse )// reverse被置为非0时,当前元素指针ptr与前一个元素指针prev_elem交换,当前block成为上一个block,即last_block
{
schar*temp = reader->ptr;
reader->ptr = reader->prev_elem;
reader->prev_elem = temp;
reader->block = last_block;
}
else
{
reader->block = first_block;
}
reader->block_min = reader->block->data;// 指向当前block的首
reader->block_max = reader->block_min + reader->block->count* seq->elem_size;// 指向当前block的尾
}
else
{
reader->delta_index = 0;
reader->block = 0;
reader->ptr = reader->prev_elem = reader->block_min = reader->block_max = 0;
}
}