A Simple Deep Network:sparse autoencoder and softmax regression
During this spring break, I worked on building a simple deep network, which has two parts, sparse autoencoder and softmax regression. The method is exactly the same as the “Building Deep Networks for Classification” part in UFLDL tutorial. For better understanding it, I re-implemented it using C++ and OpenCV.
GENERAL OUTLINE
- Read dataset (including training data and testing data) into cv::Mat.
- Pre-processing data (size normalization, random order, zero mean etc.), this is for accelerate the training speed.
- Implement function which calculating sparse autoencoder cost and gradients.
- Implement function which calculating softmax regression cost and gradients.
- Implement function which calculating the whole network’s cost and gradients.
- Using gradient checking method to check whether the above functions work correctly.
- Train sparse autoencoder layer by layer (for example, say we want 3 sparse autoencoder layers. First we train 1st layer using training data as both input and output, after that, we get the hidden layer activation using the trained weights and biases. The activation of first layer sparse autoencoder is as both input and output of 2nd layer sparse autoencoder. And similarly, the activation of 2nd layer is as both input and output of 3rd layer, this is why I said train this part layer by layer.)
- Train softmax regression. In this part, the input is the last layer autoencoder’s activation, and output is the Y part of training dataset.
- Fine-Tune the whole network using back propagation method.
- Now we got the trained network, we can test it.
Here are some figures stolen from UFLDL tutorial, they help clarify the training part.
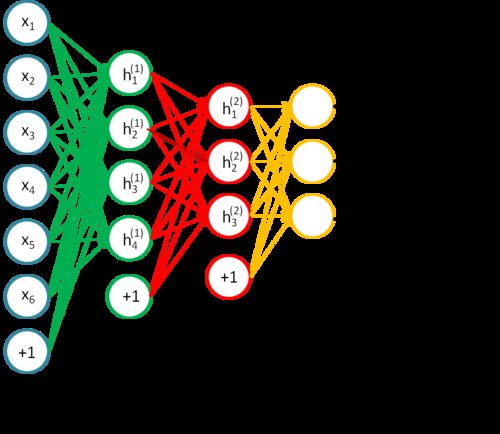
Say the dataset have 6 features in each sample, and we are training a network which has 2 layers of autoencoder, the first layer has 4 neurons, the second layer has 3 neurons. The dataset’s Y can be one of three values.
So first we train autoencoder layer 1.
Then train autoencoder layer 2.
After trained all layers of autoencoder, train softmax regression.
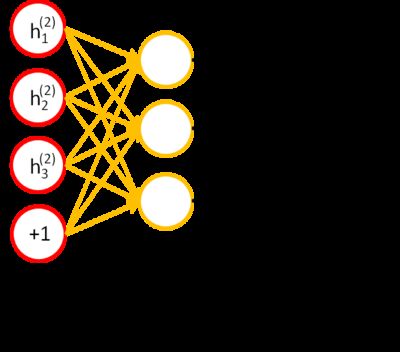
The last step is Fine-Tune the whole network.
SOURCE CODE(C++):
// MnistClassify.cpp
//
// Author: Eric Yuan
// Blog: http://eric-yuan.me
// You are FREE to use the following code for ANY purpose.
//
// A deep net hand writing classifier.
// Using sparse autoencoder and softmax regression.
// First train sparse autoencoder layer by layer,
// then train softmax regression,
// and fine-tune the whole network.
//
// To run this code, you should have OpenCV in your computer.
// Have fun with it
#include "opencv2/core/core.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/highgui/highgui.hpp"
#include <math.h>
#include <fstream>
#include <iostream>
using namespace cv;
using namespace std;
#define IS_TEST 0
#define IS_TEST_SA 0
#define IS_TEST_SMR 0
#define IS_TEST_FT 0
#define ATD at<double>
#define elif else if
int SparseAutoencoderLayers = 2;
int nclasses = 10;
int batch;
typedef struct SparseAutoencoder{
Mat W1;
Mat W2;
Mat b1;
Mat b2;
Mat W1grad;
Mat W2grad;
Mat b1grad;
Mat b2grad;
double cost;
}SA;
typedef struct SparseAutoencoderActivation{
Mat aInput;
Mat aHidden;
Mat aOutput;
}SAA;
typedef struct SoftmaxRegession{
Mat Weight;
Mat Wgrad;
double cost;
}SMR;
Mat
concatenateMat(vector<Mat> &vec){
int height = vec[0].rows;
int width = vec[0].cols;
Mat res = Mat::zeros(height * width, vec.size(), CV_64FC1);
for(int i=0; i<vec.size(); i++){
Mat img(height, width, CV_64FC1);
vec[i].convertTo(img, CV_64FC1);
// reshape(int cn, int rows=0), cn is num of channels.
Mat ptmat = img.reshape(0, height * width);
Rect roi = cv::Rect(i, 0, ptmat.cols, ptmat.rows);
Mat subView = res(roi);
ptmat.copyTo(subView);
}
divide(res, 255.0, res);
return res;
}
int
ReverseInt (int i){
unsigned char ch1, ch2, ch3, ch4;
ch1 = i & 255;
ch2 = (i >> 8) & 255;
ch3 = (i >> 16) & 255;
ch4 = (i >> 24) & 255;
return((int) ch1 << 24) + ((int)ch2 << 16) + ((int)ch3 << 8) + ch4;
}
void
read_Mnist(string filename, vector<Mat> &vec){
ifstream file(filename, ios::binary);
if (file.is_open()){
int magic_number = 0;
int number_of_images = 0;
int n_rows = 0;
int n_cols = 0;
file.read((char*) &magic_number, sizeof(magic_number));
magic_number = ReverseInt(magic_number);
file.read((char*) &number_of_images,sizeof(number_of_images));
number_of_images = ReverseInt(number_of_images);
file.read((char*) &n_rows, sizeof(n_rows));
n_rows = ReverseInt(n_rows);
file.read((char*) &n_cols, sizeof(n_cols));
n_cols = ReverseInt(n_cols);
for(int i = 0; i < number_of_images; ++i){
Mat tpmat = Mat::zeros(n_rows, n_cols, CV_8UC1);
for(int r = 0; r < n_rows; ++r){
for(int c = 0; c < n_cols; ++c){
unsigned char temp = 0;
file.read((char*) &temp, sizeof(temp));
tpmat.at<uchar>(r, c) = (int) temp;
}
}
vec.push_back(tpmat);
}
}
}
void
read_Mnist_Label(string filename, Mat &mat)
{
ifstream file(filename, ios::binary);
if (file.is_open()){
int magic_number = 0;
int number_of_images = 0;
int n_rows = 0;
int n_cols = 0;
file.read((char*) &magic_number, sizeof(magic_number));
magic_number = ReverseInt(magic_number);
file.read((char*) &number_of_images,sizeof(number_of_images));
number_of_images = ReverseInt(number_of_images);
for(int i = 0; i < number_of_images; ++i){
unsigned char temp = 0;
file.read((char*) &temp, sizeof(temp));
mat.ATD(0, i) = (double)temp;
}
}
}
Mat
sigmoid(Mat &M){
Mat temp;
exp(-M, temp);
return 1.0 / (temp + 1.0);
}
Mat
dsigmoid(Mat &a){
Mat res = 1.0 - a;
res = res.mul(a);
return res;
}
void
weightRandomInit(SA &sa, int inputsize, int hiddensize, int nsamples, double epsilon){
double *pData;
sa.W1 = Mat::ones(hiddensize, inputsize, CV_64FC1);
for(int i=0; i<hiddensize; i++){
pData = sa.W1.ptr<double>(i);
for(int j=0; j<inputsize; j++){
pData[j] = randu<double>();
}
}
sa.W1 = sa.W1 * (2 * epsilon) - epsilon;
sa.W2 = Mat::ones(inputsize, hiddensize, CV_64FC1);
for(int i=0; i<inputsize; i++){
pData = sa.W2.ptr<double>(i);
for(int j=0; j<hiddensize; j++){
pData[j] = randu<double>();
}
}
sa.W2 = sa.W2 * (2 * epsilon) - epsilon;
sa.b1 = Mat::ones(hiddensize, 1, CV_64FC1);
for(int j=0; j<hiddensize; j++){
sa.b1.ATD(j, 0) = randu<double>();
}
sa.b1 = sa.b1 * (2 * epsilon) - epsilon;
sa.b2 = Mat::ones(inputsize, 1, CV_64FC1);
for(int j=0; j<inputsize; j++){
sa.b2.ATD(j, 0) = randu<double>();
}
sa.b2 = sa.b2 * (2 * epsilon) - epsilon;
sa.W1grad = Mat::zeros(hiddensize, inputsize, CV_64FC1);
sa.W2grad = Mat::zeros(inputsize, hiddensize, CV_64FC1);
sa.b1grad = Mat::zeros(hiddensize, 1, CV_64FC1);
sa.b2grad = Mat::zeros(inputsize, 1, CV_64FC1);
sa.cost = 0.0;
}
void
weightRandomInit(SMR &smr, int nclasses, int nfeatures, double epsilon){
smr.Weight = Mat::ones(nclasses, nfeatures, CV_64FC1);
double *pData;
for(int i = 0; i<smr.Weight.rows; i++){
pData = smr.Weight.ptr<double>(i);
for(int j=0; j<smr.Weight.cols; j++){
pData[j] = randu<double>();
}
}
smr.Weight = smr.Weight * (2 * epsilon) - epsilon;
smr.cost = 0.0;
smr.Wgrad = Mat::zeros(nclasses, nfeatures, CV_64FC1);
}
SAA
getSparseAutoencoderActivation(SA &sa, Mat &data){
SAA acti;
data.copyTo(acti.aInput);
acti.aHidden = sa.W1 * acti.aInput + repeat(sa.b1, 1, data.cols);
acti.aHidden = sigmoid(acti.aHidden);
acti.aOutput = sa.W2 * acti.aHidden + repeat(sa.b2, 1, data.cols);
acti.aOutput = sigmoid(acti.aOutput);
return acti;
}
void
sparseAutoencoderCost(SA &sa, Mat &data, double lambda, double sparsityParam, double beta){
int nfeatures = data.rows;
int nsamples = data.cols;
SAA acti = getSparseAutoencoderActivation(sa, data);
Mat errtp = acti.aOutput - data;
pow(errtp, 2.0, errtp);
errtp /= 2.0;
double err = sum(errtp)[0] / nsamples;
// now calculate pj which is the average activation of hidden units
Mat pj;
reduce(acti.aHidden, pj, 1, CV_REDUCE_SUM);
pj /= nsamples;
// the second part is weight decay part
double err2 = sum(sa.W1)[0] + sum(sa.W2)[0];
err2 *= (lambda / 2.0);
// the third part of overall cost function is the sparsity part
Mat err3;
Mat temp;
temp = sparsityParam / pj;
log(temp, temp);
temp *= sparsityParam;
temp.copyTo(err3);
temp = (1 - sparsityParam) / (1 - pj);
log(temp, temp);
temp *= (1 - sparsityParam);
err3 += temp;
sa.cost = err + err2 + sum(err3)[0] * beta;
// following are for calculating the grad of weights.
Mat delta3 = -(data - acti.aOutput);
delta3 = delta3.mul(dsigmoid(acti.aOutput));
Mat temp2 = -sparsityParam / pj + (1 - sparsityParam) / (1 - pj);
temp2 *= beta;
Mat delta2 = sa.W2.t() * delta3 + repeat(temp2, 1, nsamples);
delta2 = delta2.mul(dsigmoid(acti.aHidden));
Mat nablaW1 = delta2 * acti.aInput.t();
Mat nablaW2 = delta3 * acti.aHidden.t();
Mat nablab1, nablab2;
delta3.copyTo(nablab2);
delta2.copyTo(nablab1);
sa.W1grad = nablaW1 / nsamples + lambda * sa.W1;
sa.W2grad = nablaW2 / nsamples + lambda * sa.W2;
reduce(nablab1, sa.b1grad, 1, CV_REDUCE_SUM);
reduce(nablab2, sa.b2grad, 1, CV_REDUCE_SUM);
sa.b1grad /= nsamples;
sa.b2grad /= nsamples;
}
void
softmaxRegressionCost(Mat &x, Mat &y, SMR &smr, double lambda){
int nsamples = x.cols;
int nfeatures = x.rows;
//calculate cost function
Mat theta(smr.Weight);
Mat M = theta * x;
Mat temp, temp2;
temp = Mat::ones(1, M.cols, CV_64FC1);
reduce(M, temp, 0, CV_REDUCE_SUM);
temp2 = repeat(temp, nclasses, 1);
M -= temp2;
exp(M, M);
temp = Mat::ones(1, M.cols, CV_64FC1);
reduce(M, temp, 0, CV_REDUCE_SUM);
temp2 = repeat(temp, nclasses, 1);
divide(M, temp2, M);
Mat groundTruth = Mat::zeros(nclasses, nsamples, CV_64FC1);
for(int i=0; i<nsamples; i++){
groundTruth.ATD(y.ATD(0, i), i) = 1.0;
}
Mat logM;
log(M, logM);
temp = groundTruth.mul(logM);
smr.cost = - sum(temp)[0] / nsamples;
Mat theta2;
pow(theta, 2.0, theta2);
smr.cost += sum(theta2)[0] * lambda / 2;
//calculate gradient
temp = groundTruth - M;
temp = temp * x.t();
smr.Wgrad = - temp / nsamples;
smr.Wgrad += lambda * theta;
}
void
fineTuneNetworkCost(Mat &x, Mat &y, vector<SA> &hLayers, SMR &smr, double lambda){
int nfeatures = x.rows;
int nsamples = x.cols;
vector<Mat> acti;
acti.push_back(x);
for(int i=1; i<=SparseAutoencoderLayers; i++){
Mat tmpacti = hLayers[i - 1].W1 * acti[i - 1] + repeat(hLayers[i - 1].b1, 1, x.cols);
acti.push_back(sigmoid(tmpacti));
}
Mat M = smr.Weight * acti[acti.size() - 1];
Mat tmp;
reduce(M, tmp, 0, CV_REDUCE_MAX);
M = M + repeat(tmp, M.rows, 1);
Mat p;
exp(M, p);
reduce(p, tmp, 0, CV_REDUCE_SUM);
divide(p, repeat(tmp, p.rows, 1), p);
Mat groundTruth = Mat::zeros(nclasses, nsamples, CV_64FC1);
for(int i=0; i<nsamples; i++){
groundTruth.ATD(y.ATD(0, i), i) = 1.0;
}
Mat logP;
log(p, logP);
logP = logP.mul(groundTruth);
smr.cost = - sum(logP)[0] / nsamples;
pow(smr.Weight, 2.0, tmp);
smr.cost += sum(tmp)[0] * lambda / 2;
tmp = (groundTruth - p) * acti[acti.size() - 1].t();
tmp /= -nsamples;
smr.Wgrad = tmp + lambda * smr.Weight;
vector<Mat> delta(acti.size());
delta[delta.size() -1] = -smr.Weight.t() * (groundTruth - p);
delta[delta.size() -1] = delta[delta.size() -1].mul(dsigmoid(acti[acti.size() - 1]));
for(int i = delta.size() - 2; i >= 0; i--){
delta[i] = hLayers[i].W1.t() * delta[i + 1];
delta[i] = delta[i].mul(dsigmoid(acti[i]));
}
for(int i=SparseAutoencoderLayers - 1; i >=0; i--){
hLayers[i].W1grad = delta[i + 1] * acti[i].t();
hLayers[i].W1grad /= nsamples;
reduce(delta[i + 1], tmp, 1, CV_REDUCE_SUM);
hLayers[i].b1grad = tmp / nsamples;
}
acti.clear();
delta.clear();
}
void
gradientChecking(SA &sa, Mat &data, double lambda, double sparsityParam, double beta){
//Gradient Checking (remember to disable this part after you're sure the
//cost function and dJ function are correct)
sparseAutoencoderCost(sa, data, lambda, sparsityParam, beta);
Mat w1g(sa.W1grad);
cout<<"test sparse autoencoder !!!!"<<endl;
double epsilon = 1e-4;
for(int i=0; i<sa.W1.rows; i++){
for(int j=0; j<sa.W1.cols; j++){
double memo = sa.W1.ATD(i, j);
sa.W1.ATD(i, j) = memo + epsilon;
sparseAutoencoderCost(sa, data, lambda, sparsityParam, beta);
double value1 = sa.cost;
sa.W1.ATD(i, j) = memo - epsilon;
sparseAutoencoderCost(sa, data, lambda, sparsityParam, beta);
double value2 = sa.cost;
double tp = (value1 - value2) / (2 * epsilon);
cout<<i<<", "<<j<<", "<<tp<<", "<<w1g.ATD(i, j)<<", "<<w1g.ATD(i, j) / tp<<endl;
sa.W1.ATD(i, j) = memo;
}
}
}
void
gradientChecking(SMR &smr, Mat &x, Mat &y, double lambda){
//Gradient Checking (remember to disable this part after you're sure the
//cost function and dJ function are correct)
softmaxRegressionCost(x, y, smr, lambda);
Mat grad(smr.Wgrad);
cout<<"test softmax regression !!!!"<<endl;
double epsilon = 1e-4;
for(int i=0; i<smr.Weight.rows; i++){
for(int j=0; j<smr.Weight.cols; j++){
double memo = smr.Weight.ATD(i, j);
smr.Weight.ATD(i, j) = memo + epsilon;
softmaxRegressionCost(x, y, smr, lambda);
double value1 = smr.cost;
smr.Weight.ATD(i, j) = memo - epsilon;
softmaxRegressionCost(x, y, smr, lambda);
double value2 = smr.cost;
double tp = (value1 - value2) / (2 * epsilon);
cout<<i<<", "<<j<<", "<<tp<<", "<<grad.ATD(i, j)<<", "<<grad.ATD(i, j) / tp<<endl;
smr.Weight.ATD(i, j) = memo;
}
}
}
void
gradientChecking(vector<SA> &hLayers, SMR &smr, Mat &x, Mat &y, double lambda){
//Gradient Checking (remember to disable this part after you're sure the
//cost function and dJ function are correct)
fineTuneNetworkCost(x, y, hLayers, smr, lambda);
Mat grad(hLayers[0].W1grad);
cout<<"test fine-tune network !!!!"<<endl;
double epsilon = 1e-4;
for(int i=0; i<hLayers[0].W1.rows; i++){
for(int j=0; j<hLayers[0].W1.cols; j++){
double memo = hLayers[0].W1.ATD(i, j);
hLayers[0].W1.ATD(i, j) = memo + epsilon;
fineTuneNetworkCost(x, y, hLayers, smr, lambda);
double value1 = smr.cost;
hLayers[0].W1.ATD(i, j) = memo - epsilon;
fineTuneNetworkCost(x, y, hLayers, smr, lambda);
double value2 = smr.cost;
double tp = (value1 - value2) / (2 * epsilon);
cout<<i<<", "<<j<<", "<<tp<<", "<<grad.ATD(i, j)<<", "<<grad.ATD(i, j) / tp<<endl;
hLayers[0].W1.ATD(i, j) = memo;
}
}
}
void
trainSparseAutoencoder(SA &sa, Mat &data, int hiddenSize, double lambda, double sparsityParam, double beta, double lrate, int MaxIter){
int nfeatures = data.rows;
int nsamples = data.cols;
weightRandomInit(sa, nfeatures, hiddenSize, nsamples, 0.12);
if (IS_TEST_SA){
gradientChecking(sa, data, lambda, sparsityParam, beta);
}else{
int converge = 0;
double lastcost = 0.0;
cout<<"Sparse Autoencoder Learning: "<<endl;
while(converge < MaxIter){
int randomNum = ((long)rand() + (long)rand()) % (data.cols - batch);
Rect roi = Rect(randomNum, 0, batch, data.rows);
Mat batchX = data(roi);
sparseAutoencoderCost(sa, batchX, lambda, sparsityParam, beta);
cout<<"learning step: "<<converge<<", Cost function value = "<<sa.cost<<", randomNum = "<<randomNum<<endl;
if(fabs((sa.cost - lastcost) ) <= 5e-5 && converge > 0) break;
if(sa.cost <= 0.0) break;
lastcost = sa.cost;
sa.W1 -= lrate * sa.W1grad;
sa.W2 -= lrate * sa.W2grad;
sa.b1 -= lrate * sa.b1grad;
sa.b2 -= lrate * sa.b2grad;
++ converge;
}
}
}
void
trainSoftmaxRegression(SMR& smr, Mat &x, Mat &y, double lambda, double lrate, int MaxIter){
int nfeatures = x.rows;
int nsamples = x.cols;
weightRandomInit(smr, nclasses, nfeatures, 0.12);
if (IS_TEST_SMR){
gradientChecking(smr, x, y, lambda);
}else{
int converge = 0;
double lastcost = 0.0;
cout<<"Softmax Regression Learning: "<<endl;
while(converge < MaxIter){
int randomNum = ((long)rand() + (long)rand()) % (x.cols - batch);
Rect roi = Rect(randomNum, 0, batch, x.rows);
Mat batchX = x(roi);
roi = Rect(randomNum, 0, batch, y.rows);
Mat batchY = y(roi);
softmaxRegressionCost(batchX, batchY, smr, lambda);
cout<<"learning step: "<<converge<<", Cost function value = "<<smr.cost<<", randomNum = "<<randomNum<<endl;
if(fabs((smr.cost - lastcost) ) <= 1e-6 && converge > 0) break;
if(smr.cost <= 0) break;
lastcost = smr.cost;
smr.Weight -= lrate * smr.Wgrad;
++ converge;
}
}
}
void
trainFineTuneNetwork(Mat &x, Mat &y, vector<SA> &HiddenLayers, SMR &smr, double lambda, double lrate, int MaxIter){
if (IS_TEST_FT){
gradientChecking(HiddenLayers, smr, x, y, lambda);
}else{
int converge = 0;
double lastcost = 0.0;
cout<<"Fine-Tune network Learning: "<<endl;
while(converge < MaxIter){
int randomNum = ((long)rand() + (long)rand()) % (x.cols - batch);
Rect roi = Rect(randomNum, 0, batch, x.rows);
Mat batchX = x(roi);
roi = Rect(randomNum, 0, batch, y.rows);
Mat batchY = y(roi);
fineTuneNetworkCost(batchX, batchY, HiddenLayers, smr, lambda);
cout<<"learning step: "<<converge<<", Cost function value = "<<smr.cost<<", randomNum = "<<randomNum<<endl;
if(fabs((smr.cost - lastcost) / smr.cost) <= 1e-6 && converge > 0) break;
if(smr.cost <= 0) break;
lastcost = smr.cost;
smr.Weight -= lrate * smr.Wgrad;
for(int i=0; i<HiddenLayers.size(); i++){
HiddenLayers[i].W1 -= lrate * HiddenLayers[i].W1grad;
HiddenLayers[i].W2 -= lrate * HiddenLayers[i].W2grad;
HiddenLayers[i].b1 -= lrate * HiddenLayers[i].b1grad;
HiddenLayers[i].b2 -= lrate * HiddenLayers[i].b2grad;
}
++ converge;
}
}
}
Mat
resultProdict(Mat &x, vector<SA> &hLayers, SMR &smr){
vector<Mat> acti;
acti.push_back(x);
for(int i=1; i<=SparseAutoencoderLayers; i++){
Mat tmpacti = hLayers[i - 1].W1 * acti[i - 1] + repeat(hLayers[i - 1].b1, 1, x.cols);
acti.push_back(sigmoid(tmpacti));
}
Mat M = smr.Weight * acti[acti.size() - 1];
Mat tmp;
reduce(M, tmp, 0, CV_REDUCE_MAX);
M = M + repeat(tmp, M.rows, 1);
Mat p;
exp(M, p);
reduce(p, tmp, 0, CV_REDUCE_SUM);
divide(p, repeat(tmp, p.rows, 1), p);
log(p, tmp);
//cout<<tmp.t()<<endl;
Mat result = Mat::ones(1, tmp.cols, CV_64FC1);
for(int i=0; i<tmp.cols; i++){
double maxele = tmp.ATD(0, i);
int which = 0;
for(int j=1; j<tmp.rows; j++){
if(tmp.ATD(j, i) > maxele){
maxele = tmp.ATD(j, i);
which = j;
}
}
result.ATD(0, i) = which;
}
acti.clear();
return result;
}
void
readData(Mat &x, Mat &y, string xpath, string ypath, int number_of_images){
//read MNIST iamge into OpenCV Mat vector
int image_size = 28 * 28;
vector<Mat> vec;
//vec.resize(number_of_images, cv::Mat(28, 28, CV_8UC1));
read_Mnist(xpath, vec);
//read MNIST label into double vector
y = Mat::zeros(1, number_of_images, CV_64FC1);
read_Mnist_Label(ypath, y);
x = concatenateMat(vec);
}
int
main(int argc, char** argv)
{
long start, end;
start = clock();
Mat trainX, trainY;
Mat testX, testY;
readData(trainX, trainY, "mnist/train-images-idx3-ubyte", "mnist/train-labels-idx1-ubyte", 60000);
readData(testX, testY, "mnist/t10k-images-idx3-ubyte", "mnist/t10k-labels-idx1-ubyte", 10000);
// Just for testing the algorithm, you can enable the following lines,
// It just use the first 500 training samples, for accelerate the calculation.
// However, mini training sample size leads to lower test accuracy.
// Rect roi = cv::Rect(0, 0, 500, trainX.rows);
// trainX = trainX(roi);
// roi = cv::Rect(0, 0, 500, trainY.rows);
// trainY = trainY(roi);
cout<<"Read trainX successfully, including "<<trainX.rows<<" features and "<<trainX.cols<<" samples."<<endl;
cout<<"Read trainY successfully, including "<<trainY.cols<<" samples"<<endl;
cout<<"Read testX successfully, including "<<testX.rows<<" features and "<<testX.cols<<" samples."<<endl;
cout<<"Read testY successfully, including "<<testY.cols<<" samples"<<endl;
batch = trainX.cols / 100;
// Finished reading data
// pre-processing data.
// For some dataset, you may like to pre-processing the data,
// however, in MNIST dataset, it actually already pre-processed.
// Scalar mean, stddev;
// meanStdDev(trainX, mean, stddev);
// Mat normX = trainX - mean[0];
// normX.copyTo(trainX);
vector<SA> HiddenLayers;
vector<Mat> Activations;
for(int i=0; i<SparseAutoencoderLayers; i++){
Mat tempX;
if(i == 0) trainX.copyTo(tempX); else Activations[Activations.size() - 1].copyTo(tempX);
SA tmpsa;
trainSparseAutoencoder(tmpsa, tempX, 600, 3e-3, 0.1, 3, 2e-2, 80000);
Mat tmpacti = tmpsa.W1 * tempX + repeat(tmpsa.b1, 1, tempX.cols);
tmpacti = sigmoid(tmpacti);
HiddenLayers.push_back(tmpsa);
Activations.push_back(tmpacti);
}
// Finished training Sparse Autoencoder
// Now train Softmax.
SMR smr;
trainSoftmaxRegression(smr, Activations[Activations.size() - 1], trainY, 3e-3, 2e-2, 80000);
// Finetune using Back Propogation
trainFineTuneNetwork(trainX, trainY, HiddenLayers, smr, 1e-4, 2e-2, 80000);
// Finally check result.
Mat result = resultProdict(testX, HiddenLayers, smr);
Mat err(testY);
err -= result;
int correct = err.cols;
for(int i=0; i<err.cols; i++){
if(err.ATD(0, i) != 0) --correct;
}
cout<<"correct: "<<correct<<", total: "<<err.cols<<", accuracy: "<<double(correct) / (double)(err.cols)<<endl;
end = clock();
cout<<"Totally used time: "<<((double)(end - start)) / CLOCKS_PER_SEC<<" second"<<endl;
//waitKey(0);
return 0;
}
The above version uses MNIST dataset, you can get it HERE.
The MNIST database of handwritten digits, available from this page, has a training set of 60,000 examples, and a test set of 10,000 examples. It is a subset of a larger set available from NIST. The digits have been size-normalized and centered in a fixed-size image.
TEST RESULT
MNIST:
2 hidden layers, with 200 neurons in each hidden layer. Accuracy 0.9446
2 hidden layers, with 400 neurons in each hidden layer. Accuracy 0.968
2 hidden layers, with 600 neurons in each hidden layer. Accuracy 0.9266
2 hidden layers, with 800 neurons in each hidden layer. Accuracy 0.9656
MIT CBCL FACE DATABASE (#1)

POSTSCRIPT
You can see that I used stochastic gradient descent in training process, that is because:
- stochastic learning is usually much faster than batch learning.
- stochastic learning also often results in better sulutions.
- stochastic learning can be used for tracking changes.
For more details, check Efficient BackProp by Yann LeCun et al.
Enjoy the code, and feel free to let me know if there’s any bug in it.
![]()
Posted in: Algorithm, Machine Learning, OpenCV | Tags: C++, CBCL, Deep Learning, fine-tune, Machine Learning, MNIST, OpenCV, Softmax, Sparse Autoencoder, UFLDL