HDFS的使用及编程
前面总体上认识了HDFS,本文介绍HDFS的使用,主要是对其Java API的介绍,参考hadoop的在线api。
1.web访问:http://localhost:50070,查看dfs、nodes。
2.命令行调用
格式:hadoop fs -command
具体命令:
[-ls <path>] [-lsr <path>] [-du <path>] [-dus <path>] [-count[-q] <path>] [-mv <src> <dst>] [-cp <src> <dst>] [-rm [-skipTrash] <path>] [-rmr [-skipTrash] <path>] [-mkdir <path>] [-put <localsrc> ... <dst>] [-copyFromLocal <localsrc> ... <dst>] [-copyToLocal [-ignoreCrc] [-moveFromLocal <localsrc> ... <dst>] [-moveToLocal [-crc] <src> <localdst>] [-crc] <src> <localdst>] [-getmerge <src> <localdst> [addnl]] [-cat <src>] [-text <src>] [-crc] <src> <localdst>] [-expunge] [-get [-ignoreCrc] [-setrep [-R] [-w] <rep> <path/file>] [-touchz <path>] [-test -[ezd] <path>] [-stat [format] <path>] [-tail [-f] <file>] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-chgrp [-R] GROUP PATH...] [-help [cmd]]
每个命令的作用,可以使用hadoop fs -help command得到提示。还可参考http://cloud.it168.com/a2009/0615/589/000000589533.shtml。
3.Java API调用
关于hdfs的api主要在org.apache.hadoop.fs包中。下面的类除标明外,默认都在该包下。
3.1 org.apache.hadoop.conf.Configuration类:封装了一个客户端或服务器的配置,用于存取配置参数。系统资源决定了配置的内容。一个资源以xml形式的数据表示,由一系列的键值对组成。资源可以用String或path命名,String-指示hadoop在classpath中查找该资源;Path-指示hadoop在本地文件系统中查找该资源。
默认情况下,hadoop依次从classpath中加载core-default.xml(对于hadoop只读),core-site.xml(hadoop自己的配置文件,在安装目录的conf中),初始化配置。这里的classpath是指应用运行的类路径。服务端(hadoop)的classpath指向的是conf。客户端,classpath就是客户端应用的类路径(src)。
方法:addResource系列方法在配置中增加资源。
3.2 FileSystem抽象类:与hadoop的文件系统交互的接口。可以被实现为一个分布式文件系统,或者一个本地件系统。使用hdfs都要重写FileSystem,可以像操作一个磁盘一样来操作hdfs。
方法:
获得FileSystem实例:
static FileSystem get(Configuration):从默认位置classpath下读取配置。
static FileSystem get(URI,Configuration):根据URI查找适合的配置文件,若找不到则从默认位置读取。uri的格式大致为hdfs://localhost/user/tom/test,这个test文件应该为xml格式。
读取数据:
FSDataInputStream open(Path):打开指定路径的文件,返回输入流。默认4kB的缓冲。
abstract FSDataInputStream open(path,int buffersize):buffersize为读取时的缓冲大小。
写入数据:
FSDataOutputStream create(Path):打开指定文件,默认是重写文件。会自动生成所有父目录。有11个create重载方法,可以指定是否强制覆盖已有文件、文件副本数量、写入文件时的缓冲大小、文件块大小以及文件许可。
public FSDataOutputStream append(Path):打开已有的文件,在其末尾写入数据。
其他方法:
boolean exists(path):判断源文件是否存在。
boolean mkdirs(Path):创建目录。
abstract FileStatus getFileStatus(Path):获取一文件或目录的状态对象。
abstract boolean delete(Path f,boolean recursive):删除文件,recursive为ture-一个非空目录及其内容会被删除。如果是一个文件,recursive没用。
boolean deleteOnExit(Path):标记一个文件,在文件系统关闭时删除。
3.2 Path类:用于指出文件系统中的一个文件或目录。Path String用 “/" 隔开目录,如果以 / 开头表示为一个绝对路径。一般路径的格式为”hdfs://ip:port/directory/file"。
3.3 FSDataInputStream类:InputStream的派生类。文件输入流,用于读取hdfs文件。支持随机访问,可以从流的任意位置读取数据。完全可以当成InputStream来进行操作、封装使用。
方法:
int read(long position,byte[] buffer,int offset,int length):从position处读取length字节放入缓冲buffer的指定偏离量offset。返回值是实际读到的字节数。
void readFully(long position,byte[] buffer) / void readFully(long position,byte[] buffer,int offset,int length)。
long getPos():返回当前位置,即距文件开始处的偏移量
void seek(long desired):定位到desired偏移处。是一个高开销的操作。
3.4 FSDataOutputStream:OutputStream的派生类,文件输出流,用于写hdfs文件。不允许定位,只允许对一个打开的文件顺序写入。
方法:除getPos特有的方法外,继承了DataOutputStream的write系列方法。
3.5 其他类
org.apache.hadoop.io.IOUtils:与I/O相关的实用工具类。里面的方法都是静态!
static void copyBytes(InputStream in,OutputStream out,Configuration conf)
static void copyBytes(InputStream in, OutputStream out,Configuration conf,boolean close)
static void copyBytes(InputStream,OutputStream,int buffsize,boolean close)
static void copyBytes(InputStream in,OutputStream out,int buffSize)
copyBytes方法:把一个流的内容拷贝到另外一个流。close-在拷贝结束后是否关闭流,默认关闭。
static void readFully(InputStream in,byte[] buf, int off,int len):读数据到buf中。
FileStatus类:用于向客户端显示文件信息,封装了文件系统中文件和目录的元数据,包括文件长度、块大小、副本、修改时间、所有者以及许可信息。
FileSystem的继承关系如下:
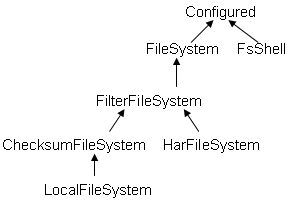
FsShell类:Provide command line access to a FileSystem,是带有主函数main的类,可以直接运行,如java FsShell [-ls] [rmr]。猜测:在终端使用hadoop fs -ls等命令时,hadoop应该就调用了该类FsShell。
ChecksumFileSystem抽象类:为每个源文件创建一个校验文件,在客户端产生和验证校验。HarFileSystem:hadoop存档文件系统,包括有索引文件_index*,内容文件part-*
LocalFileSystem:对ChecksumFileSystem的本地实现。
3.6 使用示例代码
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
//读取数据
FSDataInputStream in=fs.open(new Path("hdfs://localhost:9000/user/whuqin/input/file01"));
//方法一
BufferedReader bf=new BufferedReader(
new InputStreamReader(in));
System.out.println(bf.readLine());
//方法二
IOUtils.copyBytes(in, System.out, 1024,true);
in.close();
//写入数据
FSDataOutputStream out=fs.create(
new Path("hdfs://localhost:9000/user/whuqin/input/fileNew"));
out.writeChars("hello OutputStrea\n");
out.close();
//删除文件
fs.delete(new Path("hdfs://localhost:9000/user/whuqin/input/file01"),true);
方法一:编译成class后,放到hadoop的安装目录下,运行:hadoop HDFSTest(类名)。
方法二:将hadoop的core-site.xml复制到应用的类路径下,直接运行。
补:在命令行模式下,查看了下hdfs的目录结构发现如下:
/home/whuqin/tmp/mapred/system/jobtracker.info /user/whuqin根目录为: /