Quoc.Le:Hierarchical invariant spatio-temporal features
文献分析:Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis
Quoc.Le, Will Y. Zou, and etc.
为什么选择精读此篇paper?
这篇paper的影响力不是一般的大,很多大牛来学校讲学都提到过次特征描述方式~
加上最近deep learning很火热,这篇paper与deep learning一样都在重视分层特征,局部特征的挖掘~
正因为视觉的局部性,分层性,从人眼的原理来分析图像吗?
maybe~
包括sift, deep learning等,确实都是从分层局部两点来挖掘视觉信息~
正好额也在研究局部~
未来的CV界,无监督学习特征方式,是主流?
像SIFT、HOG、Gist、Phog、Gloh、surf等特征都手动设计的局部特征,不易扩展~
1、无监督特征学习的方法,直接从视频数据中学习特征~
比如:稀疏编码(Sparse coding)、深度信念网(Deep belief nets)和stacked antoencoders~
2、利用独立子空间分析(independent subspace analysis, ISA)算法,从无标签视频数据中,学习具有时空不变性的特征~
是独立组建分析算法(independent component analysis, ICA)的一种扩展。
相比ICA, ISA对局部变换(频率、旋转和速率等)更加鲁棒~
但是ICA和ISA都有一个缺点,就是当数据维度高的时候,训练速度非常慢~
3、并联合深度学习算法(stacking and convolution)来学习分层表示。(这也是deep learning强调的一点)
stacking and convolution 这两个重要的idea,来自卷积神经网络~
具体来说,我们从小的输入patch来学习特征,然后和大的区域进行convolute~
convolutio的输出作为上一层的输入。 从而学习分层特征~
随着paper,我们来对以上三点,进一步的分析:
1、对静态图像的独立子空间分析
独立子空间分析是一种无监督学习的算法,从无标签的图像patch中学习特征。
一个独立子空间分析网络,可视为一个两层的网络,图一示。

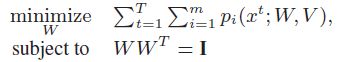 其中,
其中, ![]()
2、Stacked convolutional ISA
首先在小的输入patch上,训练ISA算法。
然后学习网络模型,并在大的区域中进行convolve
PCA后再次进行ISA~
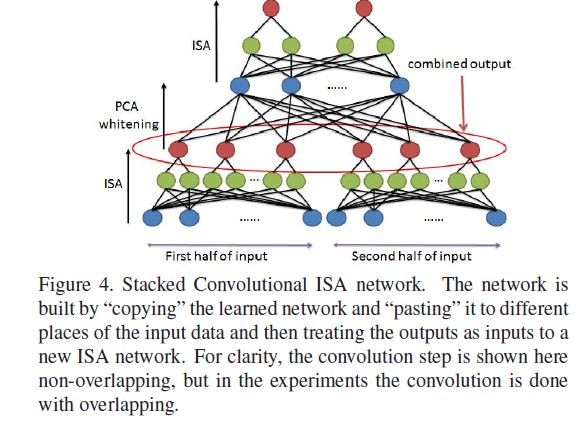
3、学习时空特征·
扩展到视频中,把原来的图像patch,替换为video patch而已~
4、利用批量投影梯度下降法进行学习~ (Batch projected gradient descent)
5、 基于正则化阈值的兴趣点检测
过滤去除一些特征点~
参考微博:http://blog.csdn.net/abcjennifer/article/details/7804962