hadoop本地任务运行过程报临时文件找不到问题排查
10个节点的Hadoop集群在使用mahout做大量的数据分析一段时间后,开始报如下错误:
[2015-12-31 10:07:31,440] [INFO ] pool-5-thread-3 SparseVectorsFromSequenceFiles - Maximum n-gram size is: 1
[2015-12-31 10:07:31,440] [INFO ] pool-5-thread-3 SparseVectorsFromSequenceFiles - Minimum LLR value: 1.0
[2015-12-31 10:07:31,440] [INFO ] pool-5-thread-3 SparseVectorsFromSequenceFiles - Number of reduce tasks: 1
[2015-12-31 10:07:31,440] [INFO ] pool-5-thread-3 SparseVectorsFromSequenceFiles - Tokenizing documents in file:/opt/hermes/analyseEmail/18081133658/SeqFile
[2015-12-31 10:07:31,441] [INFO ] pool-5-thread-3 JvmMetrics - Cannot initialize JVM Metrics with processName=JobTracker, sessionId= - already initialized
[2015-12-31 10:07:31,484] [INFO ] pool-5-thread-3 JobSubmitter - Cleaning up the staging area file:/tmp/hadoop-hermes/mapred/staging/hermes632080608/.staging/job_local632080608_28411
[2015-12-31 10:07:31,484] [ERROR] pool-5-thread-3 TagEmailService - method[tagEmailFromMS] error<org.apache.hadoop.util.Shell$ExitCodeException: chmod: cannot access `/tmp/hadoop-hermes/mapred/staging/hermes632080608/.staging/job_local632080608_28411': No such file or directory
>
org.apache.hadoop.util.Shell$ExitCodeException: chmod: cannot access `/tmp/hadoop-hermes/mapred/staging/hermes632080608/.staging/job_local632080608_28411': No such file or directory
at org.apache.hadoop.util.Shell.runCommand(Shell.java:505)
at org.apache.hadoop.util.Shell.run(Shell.java:418)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:650)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:739)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:722)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:633)
at org.apache.hadoop.fs.FilterFileSystem.setPermission(FilterFileSystem.java:467)
at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:597)
at org.apache.hadoop.mapreduce.JobSubmitter.copyAndConfigureFiles(JobSubmitter.java:179)
at org.apache.hadoop.mapreduce.JobSubmitter.copyAndConfigureFiles(JobSubmitter.java:301)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:389)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1285)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1282)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1556)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1282)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1303)
at org.apache.mahout.vectorizer.DocumentProcessor.tokenizeDocuments(DocumentProcessor.java:93)
at org.apache.mahout.vectorizer.SparseVectorsFromSequenceFiles.run(SparseVectorsFromSequenceFiles.java:257)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at com.cn21.function.KmeansClusterFunction.run(KmeansClusterFunction.java:100)
at com.cn21.service.TagEmailService.tagEmailFromMS(TagEmailService.java:105)
at com.cn21.controller.AccountFileAnalyseController.analyseAcount(AccountFileAnalyseController.java:128)
at com.cn21.controller.AccountFileAnalyseController.access$1(AccountFileAnalyseController.java:116)
at com.cn21.controller.AccountFileAnalyseController$1$1.run(AccountFileAnalyseController.java:95)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
从报错信息上看是临时文件找不到。
排查过程:
1. 首先检查是否权限不足导致无法访问或无法创建。已排除。
2. 尝试在测试环境跑程序,计算运行正常,遂怀疑是否是并发引起的。但也排除了这种可能。
3. 查看到mahout使用了local job来进行运算,尝试切换到使用正常的分布式job来运算。这个问题的确不再出现,但分布式job远慢于local job,而且在长时间运算之后,此问题又再次出现了。
4. 怀疑是mahout中使用的hadoop client相关包版本与生产hadoop集群版本不一致,修改mahout引用的hadoop client相关包版本,由默认的2.4.1改为与生产环境一致的2.6.0。并无解决此问题。
5. 观察到一个反常现象,hadoop在临时文件目录‘${hadoop.tmp.dir}/mapred/staging/’中堆积了大量的临时文件夹,超过12W个,临时文件没有正常过期删除。
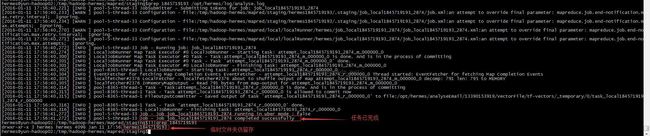
此处任务已完成,但其对应的临时文件夹仍留存在文件系统中。hadoop的逻辑应为任务完成,删除临时文件夹,但此处并未正常处理。
6. 通过请运维设置定时任务合理删除临时文件,问题解决。
异常总结:
首先这个问题是Hadoop本地临时文件没有合理删除导致的。(不知是否系hadoop的bug,因为据网上说法,hadoop应自动删除staging临时文件。浏览源码也没有删除逻辑。)因为Linux内核中对ext3文件系统的子目录个数是有限制的,同级子目录个数限制在32000个,当超过这个数目的时候不可以继续创建文件夹。因此程序报错。
排查耗时原因:
一个原因是异常信息不明确,抛错的点是在给临时文件授权时而非创建临时文件时。另一原因是对hadoop的信任,不相信它会有这样不合理的缺陷。还有一点疑问,如ext3限制子目录个数不可超过32000,为何子目录仍达到了12W个之多?
相关资料:
http://grokbase.com/t/hadoop/general/10b989tcyb/cleaning-up-hadoop-tmp-dir
http://grokbase.com/t/cloudera/cdh-user/141x6xkjz9/staging-directory-not-getting-cleaned-up
希望对大家有帮助,避免绕了弯路。(作者在这个问题上耗了一个多星期)