跑批利器--读取文件
在上篇文章中已经对示例的基本业务和流程进行了解,同时也知道了SpringBatch的三个接口ItemReader,ItemProcessor,ItemWriter.接下来我们主要是通过示例来具体处理一个文本文件,将里面的数据和内容通过SpringBatch的加工处理来存到新的数据库中.
SpringBatch提供专门的类去读取文本文件:FlatFileItemReader.要用这个类的话我们需要配置一个Spring的bean并实现一个组件用来创建领域对象.剩下的就交给SpringBatch,我们不需要再关注关于I/O具体的处理实现.
下面是一个富文本文件的例子,通常都是有一行一行的数据构成
PRODUCT_ID,NAME,DESCRIPTION,PRICE
PR....210,BlackBerry8100 Pearl,A cell phone,124.60
PR....211,SonyEricsson W810i,Yet another cell phone!,139.45
PR....212,SamsungMM-A900M Ace,A cell phone,97.80
PR....213,ToshibaM285-E 14,A cell phone,166.20
PR....214,Nokia2610 Phone,A cell phone,145.50
接下来我们还要有对应每个记录的产品实体类,一个实例代表着一条记录.如下:
importjava.math.BigDecimal;
publicclass Product {
privateString id;
privateString name;
privateString description;
privateBigDecimal price;
(...)
}
然后我们通过FlatFileItemReader类来 创建一个产品对象从产品文件中.它基本上提供了所有的I/O操作,例如打开一个文件,通过流来一行行的读取,随后再关掉这个文件.LineMapper是实现一行行的产品记录转换成一个个对象的桥梁,SpringBatch提供了一个LineMapper的实现类:DefaultLineMapper.如下图:
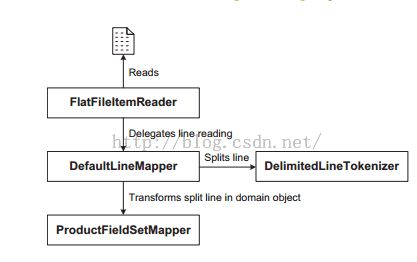
我们可以通过FieldSetMapper将一行行的产品记录通过LineTokenizer来进行分割并转换成一个java对象,FieldSetMapper接口如下:
publicinterface FieldSetMapper<T> {
TmapFieldSet(FieldSet fieldSet) throws BindException;
}
FieldSet的参数来自于LineTokenizer,可以把它当做一个jdbc的结果集,下面的代码片段示例ProductFieldSetMapper的实现
importorg.springframework.batch.item.file.mapping.FieldSetMapper;
importorg.springframework.batch.item.file.transform.FieldSet;
importorg.springframework.validation.BindException;
importcom..domain.Product;
publicclass ProductFieldSetMapper implements FieldSetMapper<Product> {
publicProduct mapFieldSet(FieldSet fieldSet) throws BindException {
Productproduct = new Product();
product.setId(fieldSet.readString("PRODUCT_ID"));
product.setName(fieldSet.readString("NAME"));
product.setDescription(fieldSet.readString("DESCRIPTION"));
product.setPrice(fieldSet.readBigDecimal("PRICE"));
returnproduct;
}
}
从上述的代码片段中我们可以看到它主要的工作是将文本文件里的记录转换成一个product对象,仔细看参数里的字符串,PRODUCT_ID,
NAME,DESCRIPTION,PRICE等,这些是从哪里来的?它们是LineTokenizer的配置里的内容,接下来我们再研究如何配置FlatFileItemReader在Spring容器里.
<beanid="reader"class="org.springframework.batch.item.file.FlatFileItemReader">
<propertyname="resource" value="file:./work/output/output.txt" />
<propertyname="linesToSkip" value="1" />
<propertyname="lineMapper">
<beanclass="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<propertyname="lineTokenizer">
<bean
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer">
<propertyname="names" value="PRODUCT_ID,
NAME,DESCRIPTION,PRICE" />
</bean>
</property>
<propertyname="fieldSetMapper">
<beanclass="com.manning.sbia.ch01.batch.ProductFieldSetMapper" />
</property>
</bean>
</property>
</bean>
上面的资源属性文件定义了文件的读取,因为第一行的内容包括头,所以我们通过lineToSkip属性告诉SpringBatch跳过第一行的内容不处理.通过DelimitedLineTokenizer将一行行的记录字段通过逗号分隔符分开.然后我们给每个字段都定义了对应的名字,这些名字就是要在ProductFieldSetMapper类中用到的FieldSet.最终达到了我们想要的效果.