C专家编程--指针和数组(四) 指针对数组的访问
首先,我要说明的,在C语言中,把“多维数组”叫做“数组的数组”更好理解一下。(下面我就统一称之为“数组的数组”)
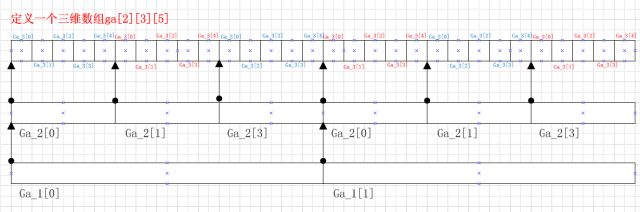
有的教程中喜欢将数组的数组用矩阵表示,不过我更趋向于直线表示,如下图(定义数组的数组int ga[2][3][5])
 (如果图片太小,建议保存到电脑上对其放大查看)
(如果图片太小,建议保存到电脑上对其放大查看)
我对数组的数组的理解(以ga[2][3][5]为例): 即为数组的数组,数组里面包含数组,数组作为另一个数组的元素。
int ga[2][3][5] = {ga_1[1], ga_1[2]}
= {{ga_2[0], ga_2[1], ga_2[3]},
{ga_2[0], ga_2[1], ga_2[3]}}
= {{ga_3[0], ga_3[1], ga_3[2], ga_3[3], ga_3[4]},
{ga_3[0], ga_3[1], ga_3[2], ga_3[3], ga_3[4]},
...(此处省略3个,上下一个6个(ga_3[0]~ga_3[4])的)
{ga_3[0], ga_3[1], ga_3[2], ga_3[3], ga_3[4]}}; //可能这种表达有点问题!!!欢迎指出 :)
首先,我们看一下指针和一维数组的关系:
int one[5] = {0};
int *p1=one; //一维数组就是这样子的,没错吧?
然后,再来看看指针与二维数组的关系:
int two[3][5] = {0};
int (*p2)[5] = two; //注意和上述一维数组的关系和区别噢!
最后我们看看指针与三位数组的关系:
int three[2][3][5] = {0};
int (*p3)[3][5] = three; //这下你应该总结出来了一点规律了吧?
是的,四维数组、五维数组、...差不多都是这样子的。
下面开始解释其原因:(请始终牢记“多维数组”即是“数组的数组”)
1、上述三维数组中的ga[2]可以看作一维数组ga_1[2],其元素是ga_1[0],ga_1[1]。
2、ga_1[0]又是一个数组,其元素是ga_2[0],ga_2[1],ga_2[2],亦即是ga_1[0]可以表示为ga_1[0][3],同理有ga_1[1][3](请注意颜色!);
3、当然ga_2[0] 亦可以表示为ga_2[0][5],同理...;
4、总结的表达式就为上述很长的那个连等式;
5、还有问题需要注意,就是分割出来的子数组的首指针是指向什么位置的;
5、不知道我解释的对不对,您能看懂么? 欢迎指出错误!!!
既然上面有指针p1,p2,p3与数组有关联了,那么现在开始用指针对数组元素访问:
p1:
printf( " one[%d] = %d\n " , i, * (p + i));
p2:
for (; i < 3 ; i ++ )
for (j = 0 ; j < 5 ; j ++ )
printf( " two[%d][%d] = %d\n " , i, j, * ( * (p2 + i) + j));
p3:
for (; i < 2 ; i ++ )
for (j = 0 ; j < 3 ; j ++ )
for (k = 0 ; k < 5 ; k ++ )
printf( " three[%d][%d][%d] = %d\n " , * ( * ( * (p3 + i) + j) + k));
【提示:如果你想愿意可以用指针访问数组的方式,和使用数组下标访问的方式,将数组各个元素的地址打印出来,然后比较一下。打印地址的控制符是"%p"】。
另外需要注意的是:
1、在*(*(*(p3+i)+j)+k)中,当执行“p3+i”的时候数组步长为“4*3*5=60”,当执行“...+j”的时候步长为“4*5=20”,当执行“...+k”的时候步长为“4”,这里的“4”都是指int类型所在字节数。(关于数组步长的概念,请大家查阅其相关资料。)
2、int (*r)[5] = ga[1]中g[1]指的是第二个ga_2[0]地址,亦即是ga[2][3][5]被看作ga_2[2]了;
int *t = g[1][1]中g[0][0]指的是第二个ga_2[1]地址,亦即是ga[2][3][5]被当作ga_1[2][3]了。
(这点可能有点难理解,建议上机操作一次。)
ps:貌似用指针和下标访问的多位数组的效率是一样的,到底使用那种方式看自己对其掌握的熟练程度。但是二者所代表的含义不一样,请参考本博博文:http://www.cnblogs.com/ziwuge/archive/2011/10/24/2194813.html 中第三篇模版里提到的内容。
第一篇 动机
讲述C++什麽地方吸引了作者,和作者为什麽要在编程中使用C++。
一开始,作者就提出了C++本质——抽象和封装:类。 抽象可以帮助设计者可以有所侧重,C++使我们更容易把程序看作抽象的集合,同时也隐藏了那些用户无须关心的抽象工作细节。封装则是C++可以把问题精心划分为分割良好的模块,使得模块与模块之间的信息得到很好的隐藏。模块化不完全同于C中也能实现模块化的函数,书中Page4上小题“不用类来实现”中已经阐述了这个观点——C中函数模块化也是有效的,但是与C++类有3个明显的缺点:①C中函数不是内联的,因此即使当跟踪关闭的时候,它还能保持函数调用的开销(“效率”是使C++经久不衰的最主要原因之一);②C中函数引入了很多全局函数名,而C++引入一个类名即可;③C++类可以使该类具有一般性,C++中有重载和覆盖,C中则必须为每种情况都提供一个函数(C不支持重载,所以参数不同导致)。C++使问题模块化,然后会给代码复用、软件开发和维护等带来很大便利。
作者在解释“为什麽用C++工作” 中,提到了编程语言的规范(L注:这一点我一直很看重,因为在软件开发的过程中,大部分时候是和同事一起完成,按照已有的编程语言规范可以使你工作很愉快,可以帮助你把精力大部分放在软件的算法和架构上去),其中说道很多后来的编程语言中使用的内存管理——垃圾回收机制,但垃圾回收要求系统在运行速度、编译器、运行时系统复杂度等方面付出代价。但C++采用构造函数和析构函数解决内存使用问题,不过这给程序员了一定压力。说实话,我觉得垃圾回收机制就是对析构函数的进一步封装(仅是个人理解),但是这要求程序设计者对程序整个运行状况都必须了解,即就是所谓的“庖丁解牛”!
另外,文中例举到①成功使用动态内存的必须操作:知道要分配多大的内存;不使用超出分配的内存范围外的内存;不再需要时释放内存;只有不再使用时,才释放内存;只释放分配的内存;切记检查每个分配请求,以确保成功。 ②编程环境:你把自己的程序交给编译器编译,编译器把相应的机器代码放入一个文件,连接程序读取这个文件,把这些机器指令和相关库中的机器指令结合起来,放入另一个文件,得到执行这个文件的命令后,操作系统把文件读入内存,并且跳到文件的第一条指令。
第二篇 类和继承
这一篇没怎么看懂,对于我来说很抽象!我还是记录一下几个知识点:代理类、句柄、虚函数、SmartPointer(智能指针)、CopyOnWrite(写时复制)、(纯)虚函数。第十一章(什麽时候不应当使用虚函数)我觉得有意思,因为对象在调用虚函数的时候容易混淆,毕竟C++的多态就是靠这个。虚函数的详细解释参考:C++虚函数表解析(转) 和 虚继承与虚函数表,下面给出书中一个例子:
class Base { public: void f(); virtual void g(); }; class Derived: public Base { public: void f(); virtual void g(); }; Base b; Derived d; Base * bp = &b; Base * bq = &d; Derived * dp = &d; bp->f(); /*Base::f()*/ bp->g(); /*Base::g()*/ bq->f(); /*Base::f()*/ bq->g(); /*Derived::g()*/ dp->g(); /*Derived::g()*/ dp->f(); /*Derived::f()*/
你会发现只有指针的静态类型与它所指向的实际对象的类型不同时,非虚函数f和虚函数g运行起来才会有所差别。另外书中一个例子:
Base* bp; Derived* dp; bp = new Derived; dp = new Derived; delete bp; // Base必须有一个虚析构函数 delete dp; // 这里虚析构函数可要可不要
这里一个基类指针来删除一个派生类对象,Base必须有一个虚析构函数。这里我是这样子理解的,派生类Derived继承自基类Base,由于Base没有析构函数(不考虑默认的),所以Derived也不会有(因为自己也没添加),应该想到基类和派生类构造函数和析构函数执行顺序:基类构造函数→派生类构造函数→派生类析构函数→基类析构函数。上例中派生类没有析构函数,所以按照上诉执行过程,最后基类必须要有析构函数,否则对象资源不能很好的释放。
第三篇 模版
感觉这一张就是介绍STL的!!!幸好之前对STL有一点的了解,要不然这一篇也是看不懂的。
里面提到一个之前没有注意的知识点:在使用数组的时候,下标和指针均可以访问数组,但是这两者的区别? 最简单的答案:下标容易理解,而指针效率更高。更深层次的回答:在下标中,下标值本身就有意义,而与它是否用于下标无关;在指针中,要访问容器的元素没有必要知道容器的标识(因为指针就包含了所有必要的信息) 。简单地说,就是程序只要拥有一个指向数组元素的指针就可以访问整个数组,而通过下标进行元素访问的程序就要另外知道正在使用的是哪一个数组。不过需要注意:“几个数组的对应元素”的概念在使用下标实现的时候远比使用指针更简单,释放数组时(可结合数组的声明周期到了???),会不通知指针的所有者,一次性使所有指向数组元素的指针失效,而下标则仍然保有其意义。
在P145中注释中提高一个:内建数组既不能被复制也不能赋值。 你可以将内建数组传递给一个函数,不过这不是数组复制,而是将该数组转化成一个指向数组元素首地址的指针,然后将这个指针传递给函数。这点可以认真思考思考!
指针和整数相减或相加都会得到一个新的指针。
在第十六章“作为接口的模版” 举的一个例子,然后以此改进,这个过程值得学习。
第十八章里提到“反转链表” ,作者列出了具体代码(那种方法是我之前没有遇见的)。
第二十章“函数对象” 也是不错,不能动态的创建函数,不过我觉得没在这个必要吧。
第四篇 库
这一篇看着头疼!!!
内建类型和内置类型有什麽联系和区别?
对于编译器而言,一个数组就是一个地址,一个指针就是一个地址的地址。
什么时候数组和指针是相同的:
1、表达式中的数组名(与声明不同)被编译器当作一个指向该数组第一个元素的指针(在表达式中,指针和数组是可以互换的,因为它们在编译器里的最终形式都是指针,并且都可以去下标操作.例对数组的引用如a[i]在编译时总是被编译器改写成*(a+i)的形式);
2、下标总是与指针的偏移量相同;
3、在函数参数的声明中,数组名被编译器当作指向该数组第一个元素的指针。
另外,对第一点的解释:存在几个极少见的例外,就是把数组当作一个整体来使用。
如下列情况:
1、数组作为sizeof的操作数-显然 此时需要的是整个数组的大小,而不是指向第一个元素的大小;
2、使用&操作符取数组的地址(原因:一个数组就是一个地址,一个指针就是一个地址的地址);
3、数组是一个字符串(或宽字符串)常量初始值。
编译器自动把下标值的步长调整到数组元素的大小。
对起始地址执行加法操作之前,编译器会负责计算每次增加的步长。这就是为什么指针总是有类型限制,每个指针只能指向同一种类型的原因所在-因为编译器需要知道对指针进行解除引用操作时应该取几个字节,以及每个下标的步长应取几个字节。
步长计算方法:偏移量乘以每个数组元素所占字节数,计算结果就是偏移数组起始地址的实际字节数。步长因子常常是2的乘方(如int是4个字节,double是8个字节)这样编译器在计算时就可以使用快速的左移位运算,而不是相对缓慢的加法运算。
C语言把数组下标改写成指针偏移量的根本原因是是真和偏移量是底层硬件所使用的基本模型。亦即是,在底层硬件中,都是使用指针来访问数据的(如前面说的,编译器都会把改写成指针形式)。
对于多维数组的方位ca[i][j],编译为*(*(ca+i)+j)。
只有字符串常量才可以初始化指针数组,指针数组不能由非字符串的类型直接初始化。
int (*ga)[20] 是被翻译成一个指向20个元素的的int数组的指针,而不是一个20个指针元素的数组。