论文读书笔记-automatic text summarization for annotating images
这篇论文要解决的问题是找到描述一副图片的关键词(即给图像加注释),这里所说的图片都是带有文字叙述的图片,比如报纸上的那些图片,往往下面会有一行小字注明是什么。为了提高关键词的准确率,本文使用了四种方法进行抽取,最后进行了对比实验。
下面是摘自本文的一些要点:
1、 两种给图像加注释的技术
计算机视觉技术,这个很容易想到,用计算机识别图像然后加注释很正常,在该技术中,最常用的两类方法是物体识别和图像分割,物体识别指识别出图像中的物体,然后就可以按照物体添加注释;图像分割即把图像分成多个区域,每个区域用词加以描述。
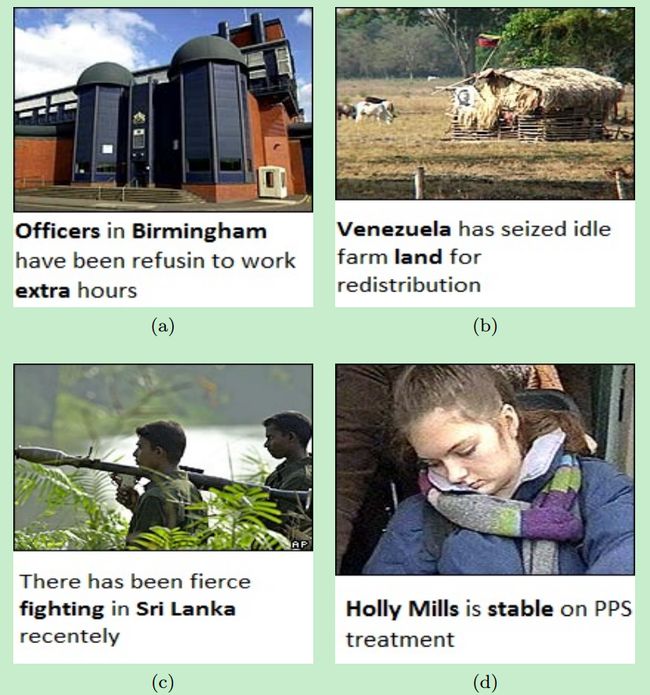
自然语言处理技术,使用该技术的前提是假设图像往往会带有一些描述性的文字,针对这些文字进行处理就能得到一些描述性的关键词
2、 四种方法之一(tf-idf)
目前抽取关键词最常见的方法是tf-idf,可以对图像描述性的文字进行关键词抽取,得到最后结果:


很显然,这种方法效果没有考虑词与词之间的关系,过于简单。
3、 四种方法之二(sentence-featuresmodel)
翻译过来是基于句子特征的模型,这种方法的思想是首先得到一段话中最主要的句子,然后从这些最主要的句子中抽取那些最具有代表意义的词,作者假设这些词最能代表这幅图片。
为了找到一段话中最主要的句子,前提是把每个句子转换为一个特征向量,这个向量能够衡量该句子与其他句子的语义联系,文本中最重要的句子应该是和其他句子具有最多相似度的句子。作者首先假设段落中首尾的句子是重要的,先赋予较高的权重,然后使用word2vec计算词的向量,计算同一个句子中词语的相似度和其他文本中词语的相似度,把这些相似度划分到20个范围之内,把这20个范围内的值作为一个句子的特征向量。
除此之外,作者还提出比较某个指定句子中的每个词与文本中其他词的相似度,用一个相似度的均值作为一个该句子标记,这个标记也能反应该句子特征。
把句子向量化之后,就能够对这些特征进行分类,最主要的句子应该位于每个类的中心。
4、 四种方法之三(word-featuresmodel)
这种方法和第二种方法有相似之处,不过这里是直接把词进行向量化,无须进一步的操作。在经过word2vec生成每个词的向量之后,再加上每个词的tf-idf。对于标记问题,这里只判断每个词是不是在文本对应的标题中出现过。最后对词进行分类,得到每个类中心点的词,把它们作为关键词。
5、 四种方法之四(hiddenmarkov model)
为了把每个句子表示成一个特征向量,首先还是按照第二种方法得到唯一的表现形式,在这个基础上作者增加了topic这个概念,通过对大量的语料进行学习,能够给每个句子标记上一个topic。然后再进行聚类。
6、 对比结果
最后作者用BBC的样本集进行了实验对比,结果如下:
可以看到第二种方法的效果最好。最后是使用第三种方法得到的图像注释: