优化临时表使用
线上mysql数据库爆出一个慢查询,DBA观察发现,查询时服务器IO飙升,IO占用率达到100%, 执行时间长达7s左右。
SQL语句如下:
SELECT DISTINCT g.*, cp.name AS cp_name, c.name AS category_name, t.name AS type_name FROMgm_game g LEFT JOIN gm_cp cp ON cp.id = g.cp_id AND cp.deleted = 0 LEFT JOIN gm_category c ON c.id = g.category_id AND c.deleted = 0 LEFT JOIN gm_type t ON t.id = g.type_id AND t.deleted = 0 WHERE g.deleted = 0 ORDER BY g.modify_time DESC LIMIT 20 ;
【问题分析】
使用explain查看执行计划,结果如下:
这条sql语句的问题其实还是比较明显的:
查询了大量数据(包括数据条数、以及g.* ),然后使用临时表order by,但最终又只返回了20条数据。
DBA观察到的IO高,是因为sql语句生成了一个巨大的临时表,内存放不下,于是全部拷贝到磁盘,导致IO飙升。
【优化方案】
优化的总体思路是拆分sql,将排序操作和查询所有信息的操作分开。
第一条语句:查询符合条件的数据,只需要查询g.id即可
SELECT DISTINCT g.id FROM gm_game g LEFT JOIN gm_cp cp ON cp.id = g.cp_id AND cp.deleted = 0 LEFT JOIN gm_category c ON c.id = g.category_id AND c.deleted = 0 LEFT JOIN gm_type t ON t.id = g.type_id AND t.deleted = 0 WHERE g.deleted = 0 ORDER BY g.modify_time DESC LIMIT 20 ;
第二条语句:查询符合条件的详细数据,将第一条sql的结果使用in操作拼接到第二条的sql
SELECT DISTINCT g.*, cp.name AS cp_name,c.name AS category_name,t.name AS type_name FROMgm_game g LEFT JOIN gm_cp cp ON cp.id = g.cp_id AND cp.deleted = 0 LEFT JOIN gm_category c ON c.id = g.category_id AND c.deleted = 0 LEFT JOIN gm_type t ON t.id = g.type_id AND t.deleted = 0 WHERE g.deleted = 0 and g.id in(…………………) ORDER BY g.modify_time DESC ;
【实测效果】
在SATA机器上测试,优化前大约需要50s,优化后第一条0.3s,第二条0.1s,优化后执行速度是原来的100倍以上,IO从100%降到不到1%
在SSD机器上测试,优化前大约需要7s,优化后第一条0.3s,第二条0.1s,优化后执行速度是原来的10倍以上,IO从100%降到不到1%
可以看出,优化前磁盘io是性能瓶颈,SSD的速度要比SATA明显要快,优化后磁盘不再是瓶颈,SSD和SATA性能没有差别。
【理论分析】
MySQL在执行SQL查询时可能会用到临时表,一般情况下,用到临时表就意味着性能较低。
- 临时表存储
MySQL临时表分为“内存临时表”和“磁盘临时表”,其中内存临时表使用MySQL的MEMORY存储引擎,磁盘临时表使用MySQL的MyISAM存储引擎;
一般情况下,MySQL会先创建内存临时表,但内存临时表超过配置指定的值后,MySQL会将内存临时表导出到磁盘临时表;
Linux平台上缺省是/tmp目录,/tmp目录小的系统要注意啦。
- 使用临时表的场景
1)ORDER BY子句和GROUP BY子句不同, 例如:ORDERY BY price GROUP BY name;
2)在JOIN查询中,ORDER BY或者GROUP BY使用了不是第一个表的列 例如:SELECT * from TableA, TableB ORDER BY TableA.price GROUP by TableB.name
3)ORDER BY中使用了DISTINCT关键字 ORDERY BY DISTINCT(price)
4)SELECT语句中指定了SQL_SMALL_RESULT关键字 SQL_SMALL_RESULT的意思就是告诉MySQL,结果会很小,请直接使用内存临时表,不需要使用索引排序 SQL_SMALL_RESULT必须和GROUP BY、DISTINCT或DISTINCTROW一起使用 一般情况下,我们没有必要使用这个选项,让MySQL服务器选择即可。
- 直接使用磁盘临时表的场景
1)表包含TEXT或者BLOB列;
2)GROUP BY 或者 DISTINCT 子句中包含长度大于512字节的列;
3)使用UNION或者UNION ALL时,SELECT子句中包含大于512字节的列;
- 临时表相关配置
tmp_table_size:指定系统创建的内存临时表最大大小; http://dev.mysql.com/doc/refman/5.1/en/server-system-variables.html#sysvar_tmp_table_size
max_heap_table_size: 指定用户创建的内存表的最大大小; http://dev.mysql.com/doc/refman/5.1/en/server-system-variables.html#sysvar_max_heap_table_size
注意:最终的系统创建的内存临时表大小是取上述两个配置值的最小值。
- 表的设计原则
使用临时表一般都意味着性能比较低,特别是使用磁盘临时表,性能更慢,因此我们在实际应用中应该尽量避免临时表的使用。 常见的避免临时表的方法有:
1)创建索引:在ORDER BY或者GROUP BY的列上创建索引;
2)分拆很长的列:一般情况下,TEXT、BLOB,大于512字节的字符串,基本上都是为了显示信息,而不会用于查询条件, 因此表设计的时候,应该将这些列独立到另外一张表。
- SQL优化
如果表的设计已经确定,修改比较困难,那么也可以通过优化SQL语句来减少临时表的大小,以提升SQL执行效率。
常见的优化SQL语句方法如下:
1)拆分SQL语句
临时表主要是用于排序和分组,很多业务都是要求排序后再取出详细的分页数据,这种情况下可以将排序和取出详细数据拆分成不同的SQL,以降低排序或分组时临时表的大小,提升排序和分组的效率,我们的案例就是采用这种方法。
2)优化业务,去掉排序分组等操作
有时候业务其实并不需要排序或分组,仅仅是为了好看或者阅读方便而进行了排序,例如数据导出、数据查询等操作,这种情况下去掉排序和分组对业务也没有多大影响。
- 如何判断使用了临时表?
使用explain查看执行计划,Extra列看到Using temporary就意味着使用了临时表。
详细信息请参考MySQL官方手册: http://dev.mysql.com/doc/refman/5.1/en/internal-temporary-tables.html
转载自http://tech.uc.cn/?p=2218
对于一些数据量较大的系统,数据库面临的问题除了查询效率低下,还有就是数据入库时间长。特别像报表系统,每天花费在数据导入上的时间可能会长达几个小时或十几个小时之久。因此,优化数据库插入性能是很有意义的。
经过对MySQL innodb的一些性能测试,发现一些可以提高insert效率的方法,供大家参考参考。
1. 一条SQL语句插入多条数据。
常用的插入语句如:
修改成:
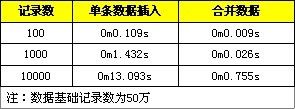
修改后的插入操作能够提高程序的插入效率。这里第二种SQL执行效率高的主要原因是合并后日志量(MySQL的binlog和innodb的事务让日志)减少了,降低日志刷盘的数据量和频率,从而提高效率。通过合并SQL语句,同时也能减少SQL语句解析的次数,减少网络传输的IO。
这里提供一些测试对比数据,分别是进行单条数据的导入与转化成一条SQL语句进行导入,分别测试1百、1千、1万条数据记录。
2. 在事务中进行插入处理。
把插入修改成:
使用事务可以提高数据的插入效率,这是因为进行一个INSERT操作时,MySQL内部会建立一个事务,在事务内才进行真正插入处理操作。通过使用事务可以减少创建事务的消耗,所有插入都在执行后才进行提交操作。
这里也提供了测试对比,分别是不使用事务与使用事务在记录数为1百、1千、1万的情况。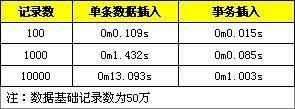
3. 数据有序插入。
数据有序的插入是指插入记录在主键上是有序排列,例如datetime是记录的主键:
修改成:
由于数据库插入时,需要维护索引数据,无序的记录会增大维护索引的成本。我们可以参照innodb使用的B+tree索引,如果每次插入记录都在索引的最后面,索引的定位效率很高,并且对索引调整较小;如果插入的记录在索引中间,需要B+tree进行分裂合并等处理,会消耗比较多计算资源,并且插入记录的索引定位效率会下降,数据量较大时会有频繁的磁盘操作。
下面提供随机数据与顺序数据的性能对比,分别是记录为1百、1千、1万、10万、100万。
从测试结果来看,该优化方法的性能有所提高,但是提高并不是很明显。
性能综合测试:
这里提供了同时使用上面三种方法进行INSERT效率优化的测试。
从测试结果可以看到,合并数据+事务的方法在较小数据量时,性能提高是很明显的,数据量较大时(1千万以上),性能会急剧下降,这是由于此时数据量超过了innodb_buffer的容量,每次定位索引涉及较多的磁盘读写操作,性能下降较快。而使用合并数据+事务+有序数据的方式在数据量达到千万级以上表现依旧是良好,在数据量较大时,有序数据索引定位较为方便,不需要频繁对磁盘进行读写操作,所以可以维持较高的性能。
注意事项:
1. SQL语句是有长度限制,在进行数据合并在同一SQL中务必不能超过SQL长度限制,通过max_allowed_packet配置可以修改,默认是1M,测试时修改为8M。
2. 事务需要控制大小,事务太大可能会影响执行的效率。MySQL有innodb_log_buffer_size配置项,超过这个值会把innodb的数据刷到磁盘中,这时,效率会有所下降。所以比较好的做法是,在数据达到这个这个值前进行事务提交。