分布式内存文件系统Tachyon
UCBerkeley研发的Tachyon(超光子['tækiːˌɒn],名字要不要这么太嚣张啊:)是一款为各种集群并发计算框架提供内存数据管理的平台,也可以说是一种内存式的文件系统吧。如下图,它就处于这样一个层次:在现有存储系统如HDFS之上,在Spark,MapReduce,Impala等各种计算框架之下。

为什么要有这么一个框架呢?MapReduce就不说了,但像Spark这种内存计算框架,为什么还需要再加一层内存管理的文件系统?因为像Spark这种,框架其实只提供了强大的内存计算能力,但未提供存储能力。那么默认让Spark自己直接在内存管理数据还不够吗?下面就看一下现有的几个问题。
问题1:不同任务或框架间交换数据慢
不同任务或不同计算框架间的数据共享情况在所难免,例如Spark的分属不同Stage的两个任务,或Spark与MapReduce框架的数据交互。在这种情况下,一般就需要通过磁盘来完成数据交换,而这通常是效率很低的。
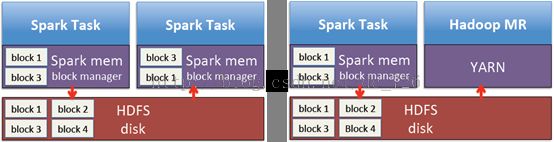
而引入Tachyon中间层后,数据交换实际上也是在内存中进行的。

问题2:执行引擎和存储引擎是同一进程
这就是前面提到过的,让Spark自己来管理内存会出现的问题。默认情况下,Spark的任务执行和数据本身都在一个进程内。当执行出现问题时就会导致整个进程崩溃,并丢失进程内的所有数据。

而Tachyon这一层的引入,就相当于将存储引擎从Spark中抽离出来,从而每个任务进程只负责执行。进程的崩溃不会丢失数据,因为数据都在Tachyon里面了。

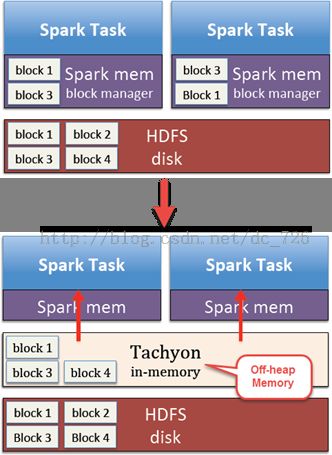
问题3:数据被重复加载和GC
不同的Spark任务可能会访问同样的数据,例如两个任务都要访问HDFS中的某些Block,像下图中的Block1和3。这样就没办法了,每个任务都要自己去磁盘加载数据到内存中。而Tachyon不仅只保存一份数据,而且它还使用堆外内存,避免GC开销。
Tachyon如何容错?
前面我们已经看到了Tachyon如何进一步提升Spark的性能的,包括避免数据落地到磁盘,共享数据以及堆外内存避免GC等。但Tachyon本身又是如何容错的呢?不落地DFS中数据不是照样会丢失吗?而且Tachyon只在内存中保存一份数据拷贝。有一种形象的说法是:Tachyon将lineage从Spark中下移到了自己。既然手握lineage,就有办法了。跟Spark类似,它利用lineage信息(lineage-based recovery)和异步记录的checkpoint来恢复数据 (与Spark类似,都是基于RDD不可变性以及粗粒度操作才能完成的,不同点是Tachyon管理的可以是跨框架的lineage而不限于RDD和Spark的转换?),所以Tachyon放心大胆地积极(aggressively)使用内存。
其次,Tachyon本身的master通过ZooKeeper集群管理,down机时会自动选举出新的leader,并且worker会自动连接到新的leader上。

现在Tachyon版本还只是0.5,资料也比较少。关于其异步checkpointing的图算法也找到什么资料,还没有搞懂。但看起来还挺有意思的,持续关注吧。
参考资料
1 Tachyon-A Reliable Memory Centric Storage for Big Data Analytics
2 Tachyon-Reliable File Sharing at Memory-Speed Across Cluster Frameworks