Servlet工作原理(转)GOOD
转自:http://www.cnblogs.com/linux2009/articles/1693598.html
其他相关:http://zhidao.baidu.com/link?url=aP7PUUpig37Br_okF-V2PExkT5juOrd4VBkRPncHB0qiNxkFuBMnykunWF5UAUDX8YSnGz8tbjjW2iVp_R7uqa
Servlet生命周期详解
如上图所示,Servlet的生命周期可以分为四个阶段,即装载类及创建实例阶段、初始化阶段、服务阶段和实例销毁阶段。下面针对每个阶段的编程任务及注意事项进行详细的说明。
(1)装载类及创建实例
在默认情况下Servlet实例是在第一个请求到来的时候创建,以后复用。如果有的Servlet需要复杂的操作需要载初始化时完成,比如打开文件、初始化网络连接等,可以通知服务器在启动的时候创建该Servlet的实例。具体配置如下:
<servlet>
<servlet-name>TimeServlet</servlet-name>
<servlet-class>com.allanlxf.servlet.basic.TimeServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
其中<load-on-startup>标记的值必须为数值类型,表示Servlet的装载顺序,取值及含义如下:
正数或零:该Servlet必须在应用启动时装载,容器必须保证数值小的Servlet先装载,如果多个
Servlet的<load-on-startup>取值相同,由容器决定它们的装载顺序。
负数或没有指定<load-on-startup>:由容器来决定装载的时机,通常为第一个请求到来时。
(2)初始化
一旦Servlet实例被创建,Web服务器会自动调用init(ServletConfig config)方法来初始化该Servlet。其中方法参数config中包含了Servlet的配置信息,比如初始化参数,该对象由服务器创建。
(3)服务一旦Servlet实例成功创建及初始化,该Servlet实例就可以被服务器用来服务于客户端的请求并生成响应。在服务阶段Web服务器会调用该实例的service(ServletRequest request, ServletResponse response)方法,request对象和response对象有服务器创建并传给Servlet实例。request对象封装了客户端发往服务器端的信息,response对象封装了服务器发往客户端的信息。
(4)销毁
当Web服务器认为Servlet实例没有存在的必要了,比如应用重新装载,或服务器关闭,以及Servlet很长时间都没有被访问过。服务器可以从内存中销毁(也叫卸载)该实例。Web服务器必须保证在卸载Servlet实例之前调用该实例的destroy()方法,以便回收Servlet申请的资源或进行其它的重要的处理。
生命周期应用实例
编写一个Servlet,该Servlet记录实例创建以来所有访问过该实例的客户端的IP地址到服务器的某个日志文件中。该日志文件的路径必可以在部署Servlet的时候由部署者指定。
代码:
package com.allanlxf.servlet.lifecycle;
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
/**
* Servelt工作原理实例,将所有访问过该客户端的IP地址记录到服务器的某个文件中。
*
* @author AllanLxf
* @version 1.0
*/
public class IPLogServlet extends HttpServlet
{
private PrintWriter logger;
/**
* Servlet的初始化方法。 不同的平台下文件的路径写法不一样,为了做到Servlet的平台无
* 关性,将用来保存客户端IP地址的文件路径以初始化参数的形式提供,这样只需在部署Servlet
* 的时候指定或改变该文件的 路径即可,而不用重新编译Servlet源代码。
* 由于频繁打开关闭文件效率很低,所以在init()方法中打开文件,在service()方法中写文
* 件,在destroy()方法中关闭文件为最佳实践。
* @throws ServletException
* 如果Servlet没有配置初始化参数filename或参数filename所指定的文件无法找到时。
*/
public void init() throws ServletException
{
String filename = getInitParameter("filename");
try
{
FileOutputStream fout = new FileOutputStream(filename, true);
logger = new PrintWriter(fout);
} catch (IOException e)
{
throw new ServletException("fail to open:" + filename);
}
}
/**
* Servlet服务方法,记录客户端的IP地址到日志文件中。
* 由于文件属于共享资源,多个线程同时写一个文件,会出现结果混乱的情况,所以要控制同步
* 访问。
* @param request 包含客户端请求信息的对象。
* @param response 包含服务器响应信息的对象。
*/
public void service(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException
{
response.setContentType("text/html;charset=gbk");
PrintWriter out = response.getWriter();
out.println("<html>");
out.println("<head>");
out.println(" <title>ip-log</title>");
out.println("</head>");
out.println("<body>");
out.println("<h3 align=\"center\">Thanks for your visiting!</h3>");
out.println("</body>");
out.println("</html>");
//记录日志信息
synchronized (this)
{
logger.print(new java.util.Date());
logger.print(":来自客户端:");
logger.println(request.getRemoteAddr());
}
}
/**
* Servlet实例销毁方法。关闭日志文件。
*/
public void destroy()
{
logger.close();
}
}
Servlet与URL匹配
为了让客户端访问服务器中的Servlet,部署者需要为每个Servlet配置一个访问路径,该路径有如下的三种写法:
(1)确切路径匹配
以“/”开始,后面跟一个具体的路径名称,也可以包含子路径。比如:/time、/basic/time、/basic/time/http都属确切的路径匹配。在该匹配模式下,客户端只能通过这一唯一的路径来访问该Servlet实例。
(2)模糊路径匹配
以“/”开始,以“/*”结束,中间可以包含子路径。比如:/*、/basic/*、/user/management/* 都属于模糊路径匹配。在该匹配模式下,客户端可以通过一组相关的路径来访问该Servlet的实例,即可以通过URL来传递附加信息。
(3)扩展名匹配
以”*.”开始,以任意其它的字符结束。比如:*.do、*.action、*.ctrl等都属于扩展名的匹配。在该匹配模式下,客户端可以通过一组相关的路径来访问该Servlet的实例,即可以通过URL来传递附加信息。
(4)缺省的Servlet
配置成“/”的Servlet为该应用的缺省的Servlet,Web服务器会将所有的无法识别的客户端请求交给缺省的Servlet来处理。
匹配优先级别
在一个Web应用中会同时发布多个Servlet,不可避免的会出现多个Servlet都可以服务于某一个请求的情况。比如系统中发布了三个Servlet,它们的匹配路径分别为:/* 、 *.do 及 /basic,如果客户端的请求路径位:/basic,那么 /basic以及 /* 都可以服务于该请求。因此规范中规定了Web服务器匹配Servlet的顺序规则,具体顺序规定如下:
1. 寻找确切的路径匹配的Servlet。
2. 如果没有确切的路径匹配,按照模糊的路径匹配,如果有多个路径存在,取固定部分路径最长的Servlet。
3. 寻找扩展名的匹配。
4. 如果上述规则都无法匹配到Servlet,系统会将请求交给缺省的Servlet处理。
5. 如果没有缺省的Servlet,报告错误信息给调用者。
假如系统中有如下的Servlet的匹配模式:
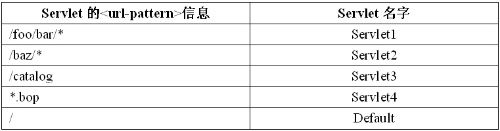
下面分别用不同的路径访问该应用,匹配结果如下:
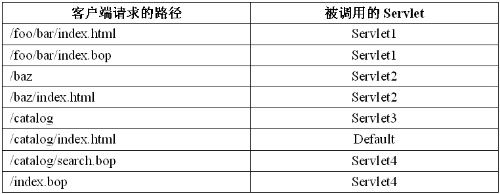
补充:
Servlet执行流程 web服务器接受到一个http请求后,web服务器会将请求移交给servlet容器, servlet容器首先对所请求的URL进行解析并根据web.xml 配置文件找到相应的处理servlet, 同时将request、response对象传递给它,servlet通过request对象可知道客户端的请求者、 请求信息以及其他的信息等,servlet在处理完请求后会把所有需要返回的信息放入response对象中 并返回到客户端,servlet一旦处理完请求,servlet容器就会刷新response对象, 并把控制权重新返回给web服务器。