Set集合,HashSet类,TreeSet类,EnumSet类
java 集合类概述
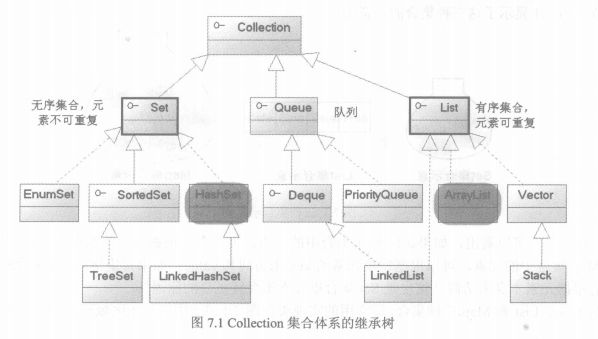

Collection和Map是Java集合类的根接口,Collection 主要是元素集合,就像C#里面List一样,而Map就像C#里面的HashTable,Dictionary一样,属于键值对集合,上面的图是这两个类的体系结构.
下面这么多类,它们的用处和区别也用图来表示

Set集合通用知识
Set集合与Collection基本上完全一样,没有提供任何额外的方法。实际上Set就是Collection,只是行为不同(Set不允许包含重复元素)
set集合不允许包含相同的元素,如果试图把两个相同元素加入同一个Set集合中,则添加操作失败,add方法返回false,且新元素不会被加入。
问1:Set集合如何判断两个对象是否相同?
答:Set集合判断两个对象是否相同,是使用equals方法,而不是使用运算符==的。即,如果两个对象用equals方法比较返回false,Set就不会接受这两个对象了。
举例如下:
package day0211;
import java.util.HashSet;
import java.util.Set;
public class TestSet1 {
/**
* @param args
* 以下代码看出Set集合只接受同一对象一次出现
* 因为如果Set集合是用==运算符判断两个对象是否相等的话,我们通过new来创建逆战,两次的对象肯定不同,会返回true
* 而结果显示只有一个逆战的字符串,所以Set集合是用equals来比较两个字符串的。
*/
public static void main(String[] args) {
Set<String> s1 = new HashSet<String>();
s1.add("周杰伦");
s1.add("谢霆锋");
s1.add(new String("逆战"));
s1.add(new String("逆战"));
System.out.println(s1);
}
}
运行结果如下:
[周杰伦, 逆战, 谢霆锋]
HashSet类
HashSet类是Set接口的典型实现,大多数时候使用Set集合时就是使用这个实现类的。HashSet按Hash算法来存储集合中的元素,因此具有很到的存取和查找性能。
HashSet具有以下的特点:
①不能保证元素的排列顺序,顺序有可能发生变化
②HashSet不是同步的,即线程不安全的,如果多个线程同时访问一个Set集合,如果有2条或者2条以上线程同时修改了HashSet集合时,必须通过代码来保证其同步。
③集合元素可以是null值,但也只能是一个。
问题1:HashSet几个是如何存储元素的?
答:当向HashSet集合存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据该HashCode值来决定该对象在HashSet中的存储位置。如果两个元素通过equals方法比较返回true,但是它们的hashCode()方法的返回值不相等,HashSet将会把它们存储在不同位置,也就可以添加成功。
问题2:HashSet集合如何判断两个对象是否相同?
答:HashSet集合判断两个对象是否相同的标准是两个对象通过equa方法比较相等,并且对象的hashCode()方法返回值也相等。
举例如下:
package day0211;
import java.util.HashSet;
public class TestSet2 {
public static void main(String[] args) {
HashSet hs=new HashSet();
hs.add(new A());
hs.add(new A());
hs.add(new B());
hs.add(new B());
hs.add(new C());
hs.add(new C());
System.out.println(hs);
}
}
class A {
public boolean equals(Object obj) {
return true;
}
}
class B {
public int hashCode() {
return 1;
}
}
class C {
public boolean equals(Object obj) {
return true;
}
public int hashCode() {
return 2;
}
}
运行结果如下:
[day0211.B@1, day0211.B@1, day0211.A@1bc4459, day0211.C@2, day0211.A@150bd4d]
解释:上面程序中hs集合中分别添加了2个A对象,2个B对象,2个C对象,其中C类重写了equals()方法总是返回true、hashCode()方法总是返回2,这将导致HashSet将会把两个C对象当成同一个对象。
注意点:如果需要把一个对象放入HashSet中时,如果重写该对象的对应类的equals()方法时,也应该重写其hashCode()方法,
其规则是:如果2个对象通过equals方法比较返回true,这两个对象的hashCode也应该相同。
这样就不能添加两个一样的元素了,因为两个对象通过equals方法比较返回true,但这两个对象的hashCode()方法返回不同的hashCode时,将导致HashSet会把这两个对象保存在HashSet的不同位置,从而这两个对象都能添加成功,这与Set集合的规则是相违背的。
相反:如果两个对象的hashCode()方法返回相同的hashCode,但是两个对象通过equals方法比较返回false更加麻烦!因为两个对象的hashCode值相同,HashSet试图将它们保存在同一个位置,但实际上不行。
hash算法:能保证通过一个对象快速查找到另一个对象。可以根据该元素的值得到该元素保存在何处。那么hashCode就是元素的索引。
重写hashCode()方法的基本规则:
①当两个对象通过equals方法比较返回true时,这两个对象的hashCode也应该相等
②对象中用作equals比较标准的属性,都应该用来计算hashCode值
重写hashCode()的方法:
①对象内每个要用作equals()比较标准的属性f,计算出hashCode值。
如果字段是boolean 计算为hashCode=(f?1:0);
如果字段是byte,char,short,int则计算为hashCode=(int)f;
如果字段是long 计算为hashCode=(int)(f^(f>>>32));
如果字段是float 计算为hashCode=Float.floatToLongBits(f);
如果字段是double,计算为
long l=Double.doubleToIntBits(f);
hashCode=(int)(l^(1>>>32));
如果字段是一个引用对象,那么直接调用对象的hashCode方法,即hashCode=f.hashCode();
如果需要判空,可以加上如果为空就返回0;
②用第一步中计算出来多个hashCode组合计算出一个hashCode值返回。如: return f1.hashCode()+(int)f2;
或者避免直接相加产生偶然情况,可以为各属性乘以任意一个质数后再相加,如: return f1.hashCode()*17+(int)f2*13;
注意:当向HashSet中添加可变对象时,必须十分小心,如果修改了HashSet集合中的对象,有可能导致该对象与集合中其他对象相等,从而导致HashSet无法准确访问该对象。
HashSet还有一个子类LinkedHashSet
LinkedHashSet集合也是根据元素hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的。也就是遍历LinkedHashSet集合里的元素时,HashSet将会按照元素的添加顺序来访问集合里的元素。
LinkedHashSet与HashSet比较:
前者性能略低于后者,但是迭代访问全部元素时有很好的性能,因为它是以链表来维护内部顺序的。
举例:
package day0211;
import java.util.LinkedHashSet;
public class TestSet3 {
/**
* 以下代码验证了LinkedHashSet集合内的元素的顺序与添加顺序一致
*/
public static void main(String[] args) {
LinkedHashSet<String> lhs = new LinkedHashSet<String>();
lhs.add("java");
lhs.add("andriod");
lhs.add("c++");
lhs.add("linux");
System.out.println("lhs集合内的元素有:" + lhs);
lhs.remove("c++");
System.out.println("lhs集合内的元素有:" + lhs);
lhs.add("c++");
System.out.println("lhs集合内的元素有:" + lhs);
}
}
运行结果如下:
lhs集合内的元素有:[java, andriod, c++, linux]
lhs集合内的元素有:[java, andriod, linux]
lhs集合内的元素有:[java, andriod, linux, c++]
TreeSet类
TreeSet是SortedSet接口的唯一实现,TreeSet可以确保集合元素处于排序状态。
TreeSet还提供了额外的方法:
Comparator comparator():返回当前Set使用的Comparator,或者返回null,表示以自然方式排序
Object first():返回集合中的第一个元素
Object last():返回集合中的最后一个元素
Object lower(Object e):返回集合中小于指定元素的最大元素
Object higher(Object e):返回集合中大于指定元素的最小元素
SortedSet subSet(fromElement,toElement):返回此Set的子集合,范围从fromElement(包含)到toElement(不包含)。
SortedSet headSet(toElement):返回此Set的子集合,由小于toElement的元素组成
SortedSet tailSet(fromElement):返回此Set的子集合,由大于fromElement的元素组成
举例如下:
package day0211;
import java.util.TreeSet;
public class TestSet4 {
/**
*/
public static void main(String[] args) {
TreeSet<String> ts=new TreeSet<String>();
ts.add("豆豆");
ts.add("胖胖");
ts.add("乐乐");
ts.add("财发");
System.out.println("集合中元素有:"+ts);
System.out.println("集合中第一个元素是:"+ts.first());
System.out.println("集合中最后一个元素是:"+ts.last());
//返回比豆豆小的元素组成的集合
System.out.println(ts.headSet("豆豆"));
//返回大于等于豆豆的元素的新集合
System.out.println(ts.tailSet("豆豆"));
//返回大于胖胖的元素的最小元素
System.out.println(ts.higher("胖胖"));
//返回小于豆豆的元素的最大元素
System.out.println(ts.lower("豆豆"));
//返回从胖胖(包含)到财发(不包含)的元素
System.out.println(ts.subSet("胖胖", "财发"));
}
}
运行结果如下:
集合中元素有:[乐乐, 胖胖, 豆豆, 财发]
集合中第一个元素是:乐乐
集合中最后一个元素是:财发
[乐乐, 胖胖]
[豆豆, 财发]
豆豆
胖胖
[胖胖, 豆豆]
以上结果显示TreeSet并不是根据元素的插入顺序进行排序,而是根据元素实际值来进行排序的。
TreeSet的两种排序方法:自然排序和定制排序,默认情况下,使用自然排序。
自然排序:TreeSet会调用集合元素的comparaTo(Object obj)方法来比较元素之间大小关系,然后将集合元素按升序排列。
comparaTo(Object obj)方法:是定义在Comparable接口中的,该方法返回一个整数值,实现该接口的类必须实现该方法,实现了该接口的类的对象也就可以比较大小了。当一个对象调用该方法与另一个对象进行比较,例如:obj1.compareTo(obj2),如果该方法返回0,则表明这两个对象相等,如果该方法返回一个正整数,则表明obj1大于obj2;如果该方法返回一个负整数,则表明obj1小于obj2。
java的一些常用类已经实现了Comparable接口,并提供比较大小的标准。如下是已经实现的常用类:
BigDecimal、BigInteger以及所有数值型对应包装类:按它们对应的数值的大小进行比较。
Character:按字符的UNICODE值进行比较。
Boolean:true对应的包装类实例大于false对应的包装类实例。
String:按字符串中字符的UNICODE值进行比较。
Date、Time:后面的时间、日期比前面的时间、日期大。
如果试图把一个对象添加进TreeSet时,则该对象的类必须实现Comparable接口,否则程序将会跑出异常。
例子:
package day0211;
import java.util.TreeSet;
class F {
}
public class TestSet5 {
/**
* 上面的程序试图向TreeSet集合添加两个A()对象,添加第一个对象时,TreeSet里没有任何元素,所以不会出现问题;
* 当添加第二个A()对象时,TreeSet就会调用该对象的compareTo(Object obj)方法与几个中其他元素进行比较,
* 如果其对应的类(即例子中的A类)没有实现Comparable接口,就会引发ClassCastException异常。
*/
public static void main(String[] args) {
TreeSet ts = new TreeSet();
ts.add(new F());
//会报错
// ts.add(new F());
System.out.println("集合中元素有:" + ts);
}
}
运行结果会报错!Exception in thread "main" java.lang.ClassCastException: day0211.F cannot be cast to java.lang.Comparable
at java.util.TreeMap.put(TreeMap.java:542)
at java.util.TreeSet.add(TreeSet.java:238)
at day0211.TestSet5.main(TestSet5.java:12)
注意点1:上面的程序试图向TreeSet集合添加两个A()对象,添加第一个对象时,TreeSet里没有任何元素,所以不会出现问题;当添加第二个A()对象时,TreeSet就会调用该对象的compareTo(Object obj)方法与几个中其他元素进行比较,如果其对应的类(即例子中的A类)没有实现Comparable接口,就会引发ClassCastException异常。
注意点2:大部分类在实现compareTo(Object obj)方法,都需要将被比较对象obj强制类型转换成相同类型,因为只有相同类的两个实例才会比较大小。比如:当试图将一个对象添加到TreeSet集合中,TreeSet会调用该对象的compareTo(Object obj)方法与集合中其他元素进行比较,这就要求集合中其他元素与该元素是同一个类的实例,即向TreeSet中添加的应该是同一个类的对象,否则会也会引发ClassCastException异常。
举例:
package day0211;
import java.util.TreeSet;
public class TestSet6 {
public static void main(String[] args) {
TreeSet ts = new TreeSet();
ts.add(new String("豆豆"));
//以下代码报错,类型不一致
//ts.add(new Date());
}
}
问题:TreeSet集合如何判断两个对象不相等?
答:标准是两个对象通过equals方法比较返回false,或者通过compareTo(Object obj)比较没有返回0(返回0,表示两个对象相等),即使两个对象是同一个对象,TreeSet也会把它当成两个对象进行处理。
注意:当需要把一个对象放入TreeSet时,重写该对象对应类的equals()方法时,要保证该方法与compareTo(Object obj)方法有一致的结果;
其规则是:如果两个对象通过equals方法比较返回true时,这两个对象通过compareTo(Object obj)方法比较应该返回0。
如果两个对象通过equals方法比较返回true时,但是这两个对象通过compareTo(Object obj)方法比较不返回0时,会导致TreeSet将这两个对象保存在不同的位置,从而两个都被添加成功,这与Set集合的规则有出入。
相反:当两个对象通过compareTo(Object obj)方法比较应该返回0时,但两个对象通过equals方法比较返回false更麻烦!因为两个对象通过compareTo(Object obj)方法比较相同,TreeSet试图将它们保存在同一个位置,但实际上不行。
注意: 注意:当向TreeSet中添加可变元素的属性,必须十分小心,当试图删除该对象时, TreeSet在处理这些对象时将很容易出错
故:在HashSet和TreeSet 集合只推荐仿佛不可变对象!
定制排序:如果需要实现定制排序,例如以降序排序,则可以使用Comparator接口的帮助。该接口里包含一个int compare(T o1,T o2)方法,该方法用于比较o1和o2的大小,如果该方法返回正整数,则表明o1大于o2;如果该方法返回0,则表明o1等于o2;如果该方法返回负整数,则表明o1小于o2。如果需要实现定制排序,则需要在创建TreeSet集合对象时,并提供一个Comparator对象与该TreeSet集合关联,由该Comparator对象负责集合元素的排序逻辑。
EnumSet类
EnumSet是一个专为枚举类设计的集合类,EnumSet中所有值都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显示或隐式的指定。EnumSet的集合元素也是有序的,EnumSet以枚举值在Enum类内的定义顺序来决定集合元素的顺序。
注意点:
1.EnumSet集合不允许加入null元素。如果试图插入,将抛出异常。如果仅仅只是试图测试是否出现null元素或删除null元素都不会抛出异常,删除操作会返回false
2.EnumSet类没有暴露任何构造器来创建该类的实例,程序应该通过它提供的static方法来创建EnumSet对象:
一些常用static方法来创建EnumSet对象:
static EnumSet allof(Class elementType):创建一个包含指定枚举类里所有枚举值的EnumSet es4对象。
static EnumSet complementOf(EnumSet s):创建一个其元素类型与指定EnumSet里的元素类型相同的EnumSet,新的EnumSet集合包含原EnumSet集合所不包含的、此枚举类剩下的枚举值(即新的EnumSet集合和原来的EnumSet集合的集合元素加起来就是该枚举类的所有枚举值)
static EnumSet copyOf(Collection c):使用一个普通集合来创建EnumSet集合
static EnumSet copyOf(EnumSet s):创建一个与指定EnumSet具有相同元素类型、相同集合元素的EnumSet。
static EnumSet noneOf(Class elementType):创建一个元素类型为指定枚举类型的空EnumSet.
static EnumSet of(E first,E...rest):创建一个包含一个或多个枚举值的EnumSet,传入的多个枚举值必须属于同一个枚举类。
static EnumSet range(E from,E to):创建包含从from枚举值,到to枚举值范围内所有枚举值的EnumSet集合。
举例如下:
package day0212;
import java.util.Collection;
import java.util.EnumSet;
import java.util.HashSet;
enum Season
{
SPRING,SUNMMER,FALL,WINTER
}
public class TestEnumSet {
public static void main(String[] args) {
EnumSet es1=EnumSet.allOf(Season.class);
System.out.println("集合es1中的元素包括:"+es1);
EnumSet es2=EnumSet.noneOf(Season.class);
System.out.println("集合es2中的元素包括:"+es2);
es2.add(Season.SUNMMER);
es2.add(Season.SPRING);
System.out.println("集合es2中的元素包括:"+es2);
EnumSet es3=EnumSet.of(Season.SUNMMER, Season.WINTER);
System.out.println("集合es3中的元素包括:"+es3);
EnumSet es4=EnumSet.range(Season.SUNMMER, Season.WINTER);
System.out.println("集合es4中的元素包括:"+es4);
EnumSet es5=EnumSet.complementOf(es4);
System.out.println("集合es5中的元素包括:"+es5);
Collection c1=new HashSet();
System.out.println("集合c1中的元素包括:"+c1);
c1.add(Season.SPRING);
c1.add(Season.WINTER);
EnumSet es6=EnumSet.copyOf(c1);
System.out.println("集合c1中的元素包括:"+c1);
System.out.println("集合es6中的元素包括:"+es6);
/**
* 以下代码会报错当EnumSet集合中的所有元素是由Collection集合中复制而来的时候,
* 要求Collection集合中的元素是同一个枚举类的枚举值。
*/
// c1.add("你好");
// EnumSet es7=EnumSet.copyOf(c1);
// System.out.println("集合c1中的元素包括:"+c1);
// System.out.println("集合es7中的元素包括:"+es7);
}
}
运行结果如下:
集合es1中的元素包括:[SPRING, SUNMMER, FALL, WINTER]
集合es2中的元素包括:[]
集合es2中的元素包括:[SPRING, SUNMMER]
集合es3中的元素包括:[SUNMMER, WINTER]
集合es4中的元素包括:[SUNMMER, FALL, WINTER]
集合es5中的元素包括:[SPRING]
集合c1中的元素包括:[]
集合c1中的元素包括:[SPRING, WINTER]
集合es6中的元素包括:[SPRING, WINTER]
总结如下:
1. HashSet和TreeSet是Set两个典型实现,如何选择 HashSet和TreeSet呢?
答:HashSet的性能总是比TreeSet好,因为TreeSet额外要维护集合元素的次序,只有当需要一个保持排序的Set时,才使用TreeSet,否则都应该使用HashSet。
2.HashSet还有一个子类:LinkedHashSet,对于普通插入、删除操作,LinkedHashSet比HashSet要略微慢点,这是由于维护链表所带来的额外开销造成的,不过,因为有了链表,遍历LinkedHashSet会更快。
3.EnumSet是所有Set实现类中性能最好的,但是它只能保存同一个枚举类的枚举值作为集合元素。
4.Set的三个实现类HashSet、TreeSet、EnumSet都是线程不安全的。如果有多条线程同时访问一个Set集合,并且超过一条线程修改了该Set集合,必须手动保证Set集合的同步性。通常使用Collections工具类的synchronizedSortedSet方法来“包装”该Set集合,此操作最好在创建时进行。例如:SortedSet s=Collections.synchronizedSortedSet(new TreeSet(...));
http://blog.csdn.net/lee576/article/category/1062275/3