作者:元宗 (一淘及搜索事业部-搜索技术-算法技术-主搜索与商城)
1. 什么是Query suggestion
Query下拉推荐是指搜索引擎系统根据用户当前的输入,自动提供一个Query候选列表供用户选择,Query下拉提示(Query suggestion)在搜索引擎和广告竞价平台中已经是标配的产品。Query suggestion可以帮助用户明确搜索意图,减少用户的输入并节约搜索时间,提高搜索体验有重要作用。各个搜索系统的下拉推荐的处理流程基本相同,下拉推荐不同主要体现在后台的query候选产生机制不同,下面介绍几种淘宝下拉推荐算法。
2. 基于PV的下拉推荐
最简单的下拉推荐是基于Query log中每个Query历史PV,这是最直观的下拉推荐算法,主要分三步进行
Offline部分
S1: 在海量Query log中,统计一段时间内每个Query的PV和点击数
Online部分
S1: 经过相似度计算,得到与用户输入 Query相似的候选Query集合
S2: 在相似的候选Query集合中,按照Query的 PV和点击数进行排序
这种方案简单易实现,但也存在如下问题
a. 对top Query的推荐解决较好,对于长尾Query,其相似的候选query可能从历史Querylog中挖掘不到
b. 候选Query语义相同问题,比如输入“连衣裙”,可能推荐“连衣裙女”和“连衣裙女款”两个候选Query,他们的语义基本相同,浪费了一个推荐位置
c. 推荐Query的质量问题,一些质量不高或者作弊Query,由于PV或者点击比较高而被推荐,使得一些质量高的Query没有机会推荐出来
3. 基于静态分的下拉推荐
为了改善上述单纯基于PV的问题,增加高质量Query的被推荐机会,增大下拉推荐中作弊的成本,改善推荐Query排序合理性,引入query静态分的概念,并用基于Query静态分的下拉推荐策略替代原来单纯基于PV的策略。那么什么是Query的静态分?
Query静态分是Query质量的综合指标,该指标拟合了Query各维度的知识:比如Query PV、IPV、UV、IUV、IPVUV、CTR、成交转化率、成交笔数、成交金额、召回商品数等。
将上述知识用logistic回归的方法拟合成一个实数,基于静态分的下拉推荐与基于PV的下拉推荐不同之处在于:
a. 离线部分计算每个Query的静态分
b. 在线部分,利用静态分而不是PV对候选Query进行排序,Query静态分不仅考虑了Query的历史PV/点击信息,而且考虑了Query的交易信息,使得交易行为良好的Query获得更多的展现机会,大大降低了低质量和作弊Query的展现概率。
4. 基于CTR预估的下拉推荐
基于静态分的算法解决了给予高质量候选Query以更多的展现机会和排序位置,但是这种算法与基于PV一样,主要依赖于历史Query自身的特征,搜索Query与候选Query之间的联系仅仅是两者的前缀相同。这种简单的动态特征没有将搜索Query与候选Query紧密的结合在一起,同时静态特征和动态特征的组合都是基于线性加权,每种特征的权重都是在BTS中调整得到的。为了解决两方面的问题,建立搜索词与候选Query的动态联系,这种联系通过CTR来表示。搜索词与候选Query关联性强,它的CTR就会高,反之则会比较低。
CTR预估模型
利用Logistic回归模型来预估Query的CTR,在模型中用到的特征如下
(1)搜索词与推荐Query(用表示)相关的特征;
(2)搜索词与推荐Query的类目相关特征;
(3)候选Query静态分相关特征;
(4)搜索(推荐)Query的词性特征;
(5)搜索(推荐)词对应的结果页面特征。
模型评估
MSE是比较实际值与预测之间的差异,差异值越小越好。
上述特征大部分都能够通过离线计算出来,线上按照通过得到的候选Query的CTR值进行排序。
5. 下拉推荐进阶
1)拼音搜索、拼音和汉字混合
2)拼写纠错与下拉提示
3)作弊Query清理
4)个性化下拉推荐
5)推荐丰富度和多样性
6)多维度推荐(数据规模、商品、买家、卖家、买家卖家握手)
6.1)数据规模维度:买家数量、卖家数量、商品数量;商品属性和类目数量
6.2)商品维度:商品描述角度:卖家经常会对商品进行个性化的描述,以便区别其他卖家并争取更多的曝光量和更好的价格;商品不同分类角度:除了商品所属的后台类目,还可以按照商品使用状态分为用过的,翻新的,珍藏的、有多新/旧;商品准入角度:有一些类目商品是禁止的,如arms,酒精、烟草
6.3)买家:买家类型(casual shopper, impulsive shopper,value-driven shopper, collector flippers)、买家年龄、性别、购买力、价格区间、对品牌是否在意
6.4)卖家:卖家的商品在哪些类目、好评率是否高、发货时间、描述是否属实
6.5)买家和卖家握手:买家和卖家习惯可能不同:买家搜索词和卖家标题、属性、描述可能不一致,如何解决不一致问题
另附一篇:
淘宝搜索下拉框查询词提示(Suggestion)原理
下拉框提示词(如图1所示),在淘宝搜索中,称为Suggestion(查询词提示),已经是淘宝搜索引擎必备的一个功能了,当你在搜索框进行输入时,搜索框会打开下拉的提示框,动态地向你提示一些与你已经输入内容相关的查询串。如果在提示框中看到所希望输入的查询串,直接用鼠标点击或键盘选择后,即可进行搜索,减少你的输入字符数。如果大家有一定的数字媒体检索和搜索引擎的基础知识,应该能联想到高频查询统计是如何运用在这当中的了吧。
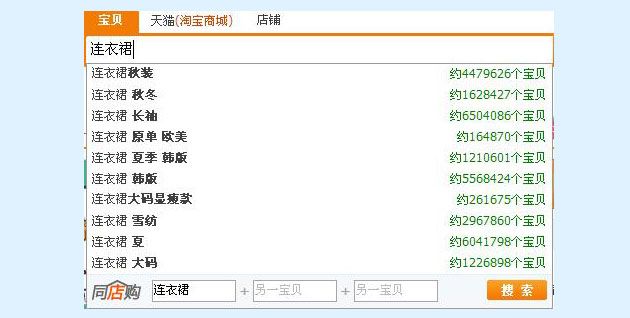
一个基本的模型是:统计查询串中可能出现的各个前缀子串,然后统计以各个前缀子串开头的查询串的频率。对各个子串,取以其作为前缀的对应K个最高频查询串。再以各子串为KEY,建立倒排索引。定期更新倒排索引,即可依据查询频率给出一个比较合理的提示内容。
模型并不复杂,但这么做有什么好处,其中包含的频率统计信息有什么意义呢?
来做个简单分析,比如淘宝搜索引擎,一天接收到的查询次数为1000万次,不同的查询串有100万个。通常而言,按查询频率来统计,频率较高的前10%查询词,其被查询的次数会占到总查询次数的近50%。下面用二分图模型来说明这个过程,如图2所示。
 对于用户和具有相同前缀的查询串,分别以上图中的u和q来表示。对于用户ui查询qi串的行为,以在ui与qi间连边来表示。假设各次查询之间是相互独立的,则一次查询命中查询串q的概率与q的度数成正比。如果将已有的查询记录作为先验模型,那么当某用户发起一次查询时,度数高,即查询频率高的串被命中的概率就大,所以会优先出以用户输入为前缀的高频查询串。
对于用户和具有相同前缀的查询串,分别以上图中的u和q来表示。对于用户ui查询qi串的行为,以在ui与qi间连边来表示。假设各次查询之间是相互独立的,则一次查询命中查询串q的概率与q的度数成正比。如果将已有的查询记录作为先验模型,那么当某用户发起一次查询时,度数高,即查询频率高的串被命中的概率就大,所以会优先出以用户输入为前缀的高频查询串。
而具体到一个查询串,按上述思路来推测,当用户输入第一个字之后,所提示的字串中包含用户希望输入查询串的概率可以这样计算:提示字串在所有以该字开头的查询串中查询次数所占的比例。一个合理的假设是,以某串P作为前缀的查询串Q,其数目会随着P的串长增长而快速下降。这个速度通过统计公共前缀查询串的数目可以推断,用户也能够查找到相关的统计资料,这里不再举具体数据。
按这样的方法,随着用户主动输入字串的长度增长,提示词命中用户真实查询词的概率将不断增加,因而需要用户主动输入的字串长度将缩短。整体上讲,能有效地降低用户使用搜索引擎的复杂度。这对于广大的中文搜索引擎用户,无疑是有吸引力的。因为大多数用户使用的是拼音输入法,需要不断地在同音字中选取自己所需要的字、词,现在搜索引擎有了这样一个功能,大家使用起来会方便很多。
根据以上介绍的Suggestion,我们还可以引入淘宝搜索点击日志,可以进一步利用点击信息来度量查询间的相似性,从而改进Suggestion。
以二分图作为分析工具,对于查询qi,用户点击的结果URL为uj,则在于之间连一加权边,eij其权重对于qi的所有查询中,uj被点击的次数wij。如图3所示。

对于查询qi则可以用这些与之相连的加权边表示。其形式为:
基于这种表示,就可以度量两个查询之间的相似度:
 这种做法就是利用点击作为联系查询与结果的桥梁,将结果集作为表达查询的一个特征空间,并在这个特征空间中度量查询的相似度,从而找到相近的查询作为Suggestion结果,由此可见,淘宝点击日志的作用是多么的重要!
这种做法就是利用点击作为联系查询与结果的桥梁,将结果集作为表达查询的一个特征空间,并在这个特征空间中度量查询的相似度,从而找到相近的查询作为Suggestion结果,由此可见,淘宝点击日志的作用是多么的重要!
百度suggestion解决方案: 点击打开链接