MapReduce数据流
Hadoop does its best to run the map task on a node where the input data resides in
HDFS. This is called the data locality optimization because it doesn’t use valuable clus-
ter bandwidth. Sometimes, however, all three nodes hosting the HDFS block replicas
for a map task’s input split are running other map tasks, so the job scheduler will look
for a free map slot on a node in the same rack as one of the blocks. Very occasionally
even this is not possible, so an off-rack node is used, which results in an inter-rack
HDFS. This is called the data locality optimization because it doesn’t use valuable clus-
ter bandwidth. Sometimes, however, all three nodes hosting the HDFS block replicas
for a map task’s input split are running other map tasks, so the job scheduler will look
for a free map slot on a node in the same rack as one of the blocks. Very occasionally
even this is not possible, so an off-rack node is used, which results in an inter-rack
network transfer. The three possibilities:
Hadoop在存储有输入数据(HDFS中的数据)的节点上运行Map任务,可以获得最佳性能。这就是所谓的数据本地化优化(data locality optimization)。
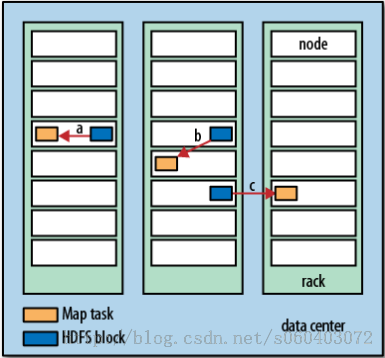
a: Data-local map tasks
b: rack-local map tasks
c: off-rack map tasks
MapReduce data flow with a single reduce task:
一个reduce任务的MapReduce数据流:
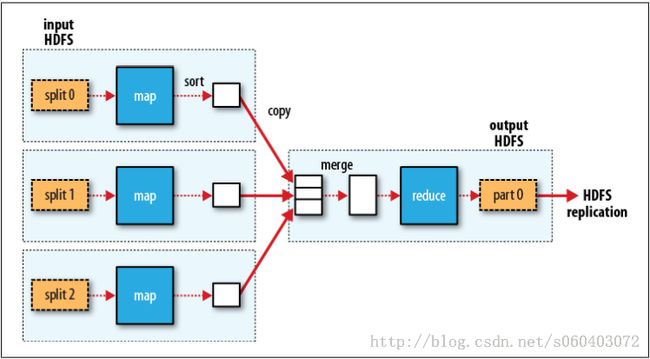
虚线框:node
虚线箭头:node内部的数据传输
实线箭头:节点之间的数据传输
MapReduce data flow with multiple reduce tasks:
多个reduce任务的MapReduce数据流:
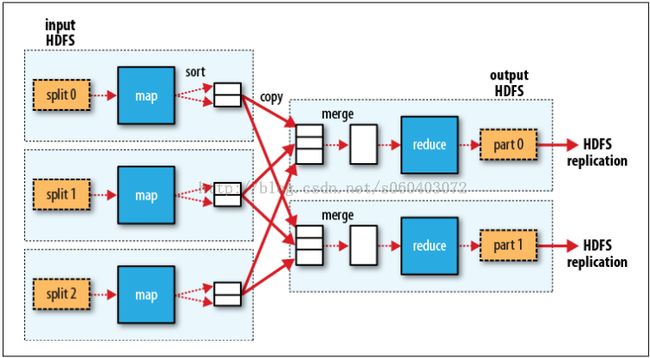
This diagram makes it clear why the data flow between map and reduce tasks is collo-
quially known as “the shuffle,” as each reduce task is fed by many map tasks. The
shuffle is more complicated than this diagram suggests, and tuning it can have a big
impact on job execution time.