AVX 指令集架构简介
AVX 指令集架构的改进和增强的功能:
- 128 位 SIMD 寄存器 xmm0 - xmm15 扩展为 256 位的 ymm0 - ymm15 寄存器
- 支持 256 位的矢量运算,由原来 128 位扩展为 256 位
- 指令可支持最多 4 个操作数,实现目标操作数无需损毁原来的内容
- 引进新的 AVX 指令,非 Legacy SSE 指令移植
- 新增 FMA 指令子集
- 引进新的指令编码模式,使用 VEX prefix 来设计指令编码
AVX 提供了一个子集:
- FMA 指令集
FMA 指令集进行 fused multiply-add/subtract 类运算,用式子表达为:
| ± (a * b) ± c |
4.1 256 位的 SIMD 寄存器
在 AVX 架构中原 Legacy SSE 指令使用的 128 位 SIMD 寄存器扩展为 256 位,xmm0 - xmm15 相应地扩展为 ymm0 - ymm15 它们使用同一个编码:
xmm 寄存器是 ymm 寄存器的低 128 位,它们的关系就好像是在通用寄存器的 eax 寄存器是 rax 寄存器的低 32 位,在 64 位模式下修改 32 位的寄存器会使 64 位寄存器高 32 位清 0
对于 AVX 指令来说有同样的行为,如下所示:
| addss xmm1, xmmword ptr [rax] ; Legacy SEE 指令:结果 ymm1 高 128 位不变 vaddss xmm1, xmmword ptr [rax] ; AVX 指令:ymm1 高 128 位清 0 |
在 AVX 指令中改变 xmm 寄存器的值结果会使相应的 ymm 寄存器高 128 位清 0,这种行为使得 SSE 指令与 AVX 指令变得不一致,因此在 AVX 代码中混合 SSE 代码时,Intel 建议调用 SSE 代码子例程前清 ymm 寄存器的高 128 位以避免性能损失。AVX 指令提供两条指令执行:
| vzeroupper ; 清所有 ymmm 寄存器的高 128 位 vzeroall ; 所有的 ymm 寄存器清为 0 |
4.2 AVX 指令集的功能
AVX 指令集提供了一系列的 floating-point(浮点)处理指令和 integer(整数)处理指令:
- 提供的浮点处理指令,包括:
- 两种宽度的 arithmetic(运算)类指令:
- 256 位宽度的 vector(矢量)运算
- 128 位宽度的 vector 与 scalar(标量)运算
- 两种宽度的 non-arithmetic(非运算)类指令:
- 256 位 non-arithmetic 类 vector 操作指令
- 128 位 non-arithmetic 类 vector 与 scalar 操作指令
- AVX 新增的 non-arithmetic 类指令:这些指令是 AVX 独有的新引进的指令,不存在对应的 SSE 版本
- 两种宽度的 arithmetic(运算)类指令:
- 整数处理指令包括:
- 128 位的 packed integer 运算指令
- 128 位的 packed integer 处理指令
除了新增的 AVX 指令外,其余的指令都是从原有的 SSE 指令移值或扩展而来,这些 AVX 指令有对应的 SSE 版本。
4.2.1 256 位浮点矢量运算指令
AVX 提供了 256 位的浮点矢量 arithmetic(运算)类指令,覆盖了 add,substract,multiply,divide 等各类算术运算,如下表所示:
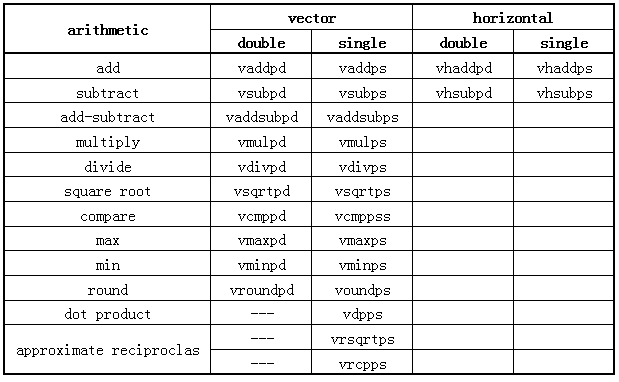
这些指令根据所处理的浮点数据类型分为 double-precision(双精度)和 single-precision(单精度)版本,以后缀后 pd(双精度)和 ps(单精度)来区分,add/subtract 运算多了 horizontal(水平)形式的运算。
4.2.2 256 位浮点矢量处理指令
non-arithmetic(非运算)类指令,覆盖了:logic,blend,shuffle,broadcast,permute,insert/extract,test,convert 处理,如下表:
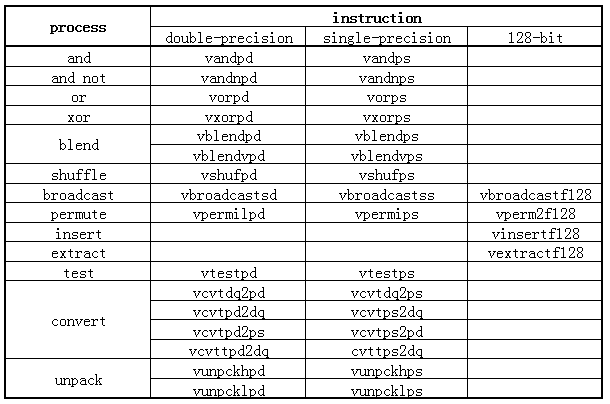
上面其中有几条是 AVX 新增的指令:
- vbroadcastsd,vbradcastss,vbroadcastf128
- vinsertf128 与 vextractf128
- vpermilpd,vpermilps,vperm2f128
4.2.3 128 位的矢量与标量运算指令
128 位 AVX 指令是从原 SSE 指令移值过来,包含了 vector 与 scalar 两类运算指令:
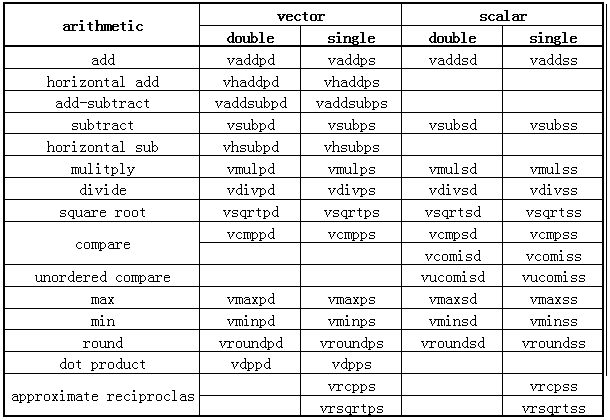
128 位的 AVX 运算指令只 256 位指令多了 scalar 数据的处理,在规格是一致的。
4.2.4 128 位 non-arithmetic 处理指令
其中:vbroadcastss,permilpd 以及 permilps 是 AVX 新增的指令
4.2.5 128 位整数运算指令
在这里还增加了几条 horizontal 数据的整数运算指令
4.2.6 128 位整数处理指令

4.2.7 AVX 指令集中的 load 与 store 指令
在 AVX 中有为数众多的 load/store 类指令,大部分从 SSE 移植过来,并新增了几条。
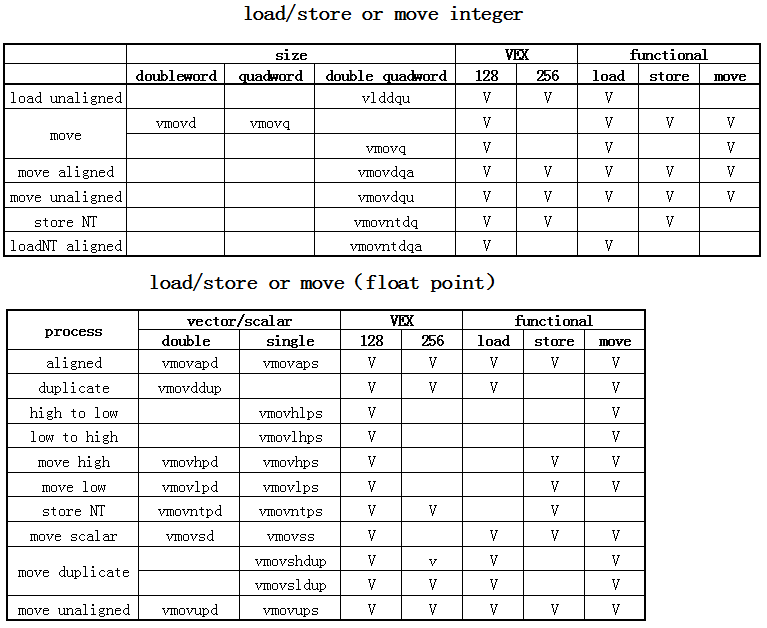
从功能上看:
- load:从 memory 到 register
- store:从 register 到 memory
- move:从 register 到 register
部分指令只有 load 或 store 功能,多数指令既可以做 load/store 也可以做 move
新增的指令 mask move 包括:
- vmaskmovepd
- vmaskmoveps