A Digit Recognizer——基于HTK实现数字串识别系统
这篇博文,可以说是之前学习笔记的实践,准备完成一个基于HTK实现数字串识别系统
整个系统分为四大部分,共有11步组成:
(一)数据准备
Step 1: The Task Grammar
Step 2: The Dictionary
Step 3: Recording the Data
Step 4: Creating theTranscription Files
Step 5: Coding the Data
(二)建立单音素的HMM模型
Step 6: Creating Flat Start Monophone
Step 7: Fixing the Silence Models
Step 8: Realigning the TrainingData
(三)创建绑定状态的三音素HMM模型
Step 9: Making Triphones fromMonophones
Step 10: Making Tied-StateTriphones
(四)识别器的评估
Step 11: Recognizing the TestData
下面是详细的实验步骤:
(一)数据准备
Step 1: The Task Grammar
创建文件:gram
创建位置:根目录下
文件内容:

执行:
HParse gram wdnet
生成:wdnet
生成位置:根目录
生成内容:
Step 2: The Dictionary
创建文件夹:dict lists
创建文件:BEEP语音字典(网上可以下载)beep beep.ded(空)
放入位置:dict
创建文件:global.ded
创建位置:根目录下
创建文件:wlist
创建位置:lists
创建内容: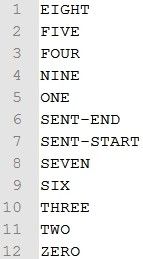
执行:
HDMan -m -w .\lists\wlist -g global.ded -n .\lists\monophones1 -l dlog .\dict\dict1 .\dict\beep生成发音字典:
dict1
monophones1

Step 3: Recording the Data
创建文件夹:labels
HSGen -l -n 64 wdnet.\dict\dict1>.\labels\trainprompts
HSGen -l -n 5 wdnet .\dict\dict1>.\labels\testprompts
生成文件:trainprompts testprompts
注:录音结束后使用SPAAS标注软件完成标注,并且使用SPAAS软件中的发音字典。标注之后生成TextGrid文件,然后转换成HTK使用的lab文件。
Step 4: Creating theTranscription Files
创建文件夹:scripts labels
创建文件:prompts2mlf(HTK scripts目录下自带)
创建位置:scripts
Perl脚本prompts2mlf(在scripts目录下HTK自带)可以把录音文本截成单词级真值文件。
执行:
perl .\scripts\prompts2mlf.\labels\trainwords.mlf .\labels\trainprompts
perl .\scripts\prompts2mlf.\labels\testwords.mlf .\labels\testprompts
注:要在每个lab路径之前加上“*/”
生成文件:trainwords.mlf testwords.mlf
生成位置:labels
标注编辑器HLEd可把单词级真值文本(wordlevel MLF)转成音素级真值文本(phonelevel MLF):
创建文件:mkphones0.led
创建位置:根目录
执行:
HLEd -l * -d .\dict\dict1 -i .\labels\phones0.mlf mkphones0.led .\labels\trainwords.mlf
Step 5: Coding the Data
创建文件夹:config
创建文件:config1(要设置的参数)
创建位置:config
执行:
HCopy -T 1 -C .\config\config1 -S codetr.scp
HCopy -T 1 -C .\config\config1 -S codete.scp

(二) 建立单音素的HMM模型
Step 6: Creating Flat Start Monophone
定义一个原始模型proto:
定义一个原始模型proto
创建文件夹:hmms/hmm0
创建文件:proto
创建位置:根目录
执行:
HCompV -C .\config\config1 -f 0.01 -m -S train.scp -M .\hmms\hmm0 proto
在目录hmm0下生成了更新后的proto和一个截至宏vFloors。基于.\hmms\hmm0\下的两个文件,手工制作主宏文件(Master Macro File)hmmdefs(是由自己的proto生成)和与vFloors相关的宏macros(是由自己的vFloors生成)
由于暂时不用sp模型,删去monophones1中的sp,构成monophone0文件,保存在lists文件夹下。
重新估计参数:
创建文件夹:hmms/hmm1
执行:
HERest -C .\config\config1 -I .\labels\phones0.mlf -t 250.0 150.0 1000.0 -S train.scp -H .\hmms\hmm0\macros -H .\hmms\hmm0\hmmdefs -M .\hmms\hmm1 .\lists\monophones0
同时重复两次迭代:
HERest -C .\config\config1 -I.\labels\phonestrain0.mlf -t 250.0 150.0 1000.0 -S train.scp -H .\hmms\hmm1\macros-H .\hmms\hmm1\hmmdefs -M .\hmms\hmm2 .\lists\monophones0
HERest -C .\config\config1 -I.\labels\phonestrain0.mlf -t 250.0 150.0 1000.0 -S train.scp -H .\hmms\hmm2\macros-H .\hmms\hmm2\hmmdefs -M .\hmms\hmm3 .\lists\monophones0
Step 7: Fixing the Silence Models
对sil模型加入回溯链,对sp绑定到sil的中间状态上。具体的,哑音素模型按下面两步执行。首先,修改hmm3\hmmdef,复制sil的中间状态为sp模型的唯一状态,另存到hmms\hmm4目录下。
sp模型内容:

创建文件夹:hmms/hmm5
利用 HHEd 加入回溯转移概率:
创建文件:sil.hed(指明sp绑定到sil中间状态)
创建位置:根目录
执行:
HHEd -H .\hmms\hmm4\macros -H .\hmms\hmm4\hmmdefs -M .\hmms\hmm5 sil.hed .\lists\monophones1
修改mkphones0.led,去掉最后一行,存为mkphones1.led,利用HLEd工具得到包含sp的音素级真值文本:
HLEd -l * -d .\dict\dict1 -i.\labels\phonestrain1.mlf mkphones1.led .\labels\trainwords.mlf
重估两次:
执行:
HERest -C .\config\config1 -I.\labels\phonestrain1.mlf -t 250.0 150.0 1000.0 -S train.scp -H.\hmms\hmm5\macros -H .\hmms\hmm5\hmmdefs -M .\hmms\hmm6 .\lists\monophones1
HERest -C .\config\config1 -I.\labels\phonestrain1.mlf -t 250.0 150.0 1000.0 -S train.scp -H.\hmms\hmm6\macros -H .\hmms\hmm6\hmmdefs -M .\hmms\hmm7 .\lists\monophones1
我们先看看这时的识别率:执行:
HVite -H .\hmms\hmm7\macros -H.\hmms\hmm7\hmmdefs -S test.scp -l * -i .\results\recout_step7.mlf -w wdnet -p0.0 -s 5.0 .\dict\dict1 .\lists\monophones1
HResults -I.\labels\testwords.mlf .\lists\monophones1 .\results\recout_step7.mlf
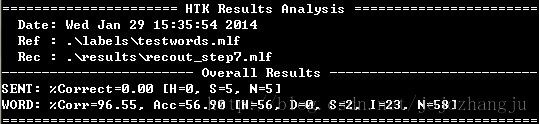 (测试集样本)
(测试集样本)
(训练集样本)
HResults -e ??? SENT-START -e ???SENT-END -I .\labels\testwords.mlf .\lists\monophones1 .\results\recout_step7.mlf
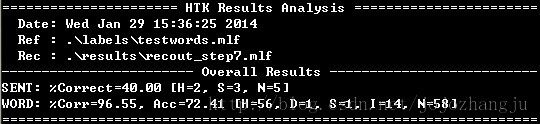 (测试集样本)
(测试集样本)
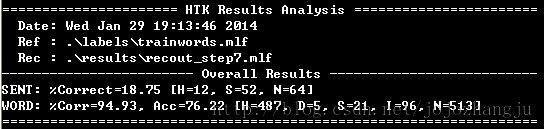 (训练集样本)
(训练集样本)
把dict1字典另存为dict2并替换上面两行成如下形式:
SENT-END [] sil
SENT-START [] sil
执行:HVite -H .\hmms\hmm7\macros -H .\hmms\hmm7\hmmdefs -S test.scp -l * -i .\results\recout_step7_2.mlf -w wdnet -p 0.0 -s 5.0 .\dict\dict2 .\lists\monophones1
HResults -I .\labels\testwords.mlf .\lists\monophones1 .\results\recout_step7_2.mlf
Step 8: Realigning the Training Data
修改dict2 加入silence sil一项,另存为dict3,执行HVite进行Viterbi校准:
执行:
HVite -l * -o SWT -b silence -C.\config\config1 -a -H .\hmms\hmm7\macros -H .\hmms\hmm7\hmmdefs -i .\labels\aligned.mlf-m -t 350.0 -y lab -I .\labels\trainwords.mlf -S train.scp .\dict\dict3.\lists\monophones1
重估两次:
HERest -C .\config\config1 -I .\labels\aligned.mlf -t 250.0 150.0 1000.0 -S train.scp -H .\hmms\hmm7\macros -H .\hmms\hmm7\hmmdefs -M .\hmms\hmm8 .\lists\monophones1
HERest -C .\config\config1 -I .\labels\aligned.mlf -t 250.0 150.0 1000.0 -S train.scp -H .\hmms\hmm8\macros -H .\hmms\hmm8\hmmdefs -M .\hmms\hmm9 .\lists\monophones1
我们再来看看这时的识别率怎么样:
HVite -H .\hmms\hmm9\macros -H .\hmms\hmm9\hmmdefs -S test.scp -l * -i .\results\recout_step8.mlf -w wdnet -p 0.0 -s 5.0 .\dict\dict2 .\lists\monophones1
HResults -I .\labels\testwords.mlf .\lists\monophones1 .\results\recout_step8.mlf
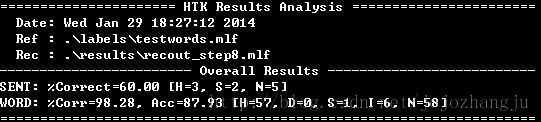 (测试集样本)
(测试集样本)
(训练集样本)
HERest -C .\config\config1 -I .\labels\aligned.mlf -t 250.0 150.0 1000.0 -S train.scp -H .\hmms\hmm9\macros -H .\hmms\hmm9\hmmdefs -M .\hmms\hmm9_1 .\lists\monophones1
HERest -C .\config\config1 -I .\labels\aligned.mlf -t 250.0 150.0 1000.0 -S train.scp -H .\hmms\hmm9_1\macros -H .\hmms\hmm9_1\hmmdefs -M .\hmms\hmm9_2 .\lists\monophones1
HVite -H .\hmms\hmm9\macros -H .\hmms\hmm9\hmmdefs -S test.scp -l * -i .\results\recout_step8_2.mlf -w wdnet -p 0.0 -s 5.0 .\dict\dict2 .\lists\monophones0
HResults -I.\labels\testwords.mlf .\lists\monophones1 .\results\recout_step8_2.mlf
(三)创建绑定状态的三音素HMM模型
Step 9: Making Triphones from Monophones
执行:
HLEd -n .\lists\triphones1 -l * -i .\labels\wintri.mlf mktri.led .\labels\aligned.mlf
执行:perl .\scripts\maketrihed .\lists\monophones1 .\lists\triphones1
修改mktri.hed文件,把第一行的.\lists\triphones1改成./lists/triphones1
执行:
HHEd -H .\hmms\hmm9\macros -H .\hmms\hmm9\hmmdefs -M .\hmms\hmm10 mktri.hed .\lists\monophones1
重估两次:
HERest -C .\config\config1 -I .\labels\wintri.mlf -t 250.0 150.0 1000.0 -S train.scp -H .\hmms\hmm10\macros -H .\hmms\hmm10\hmmdefs -M .\hmms\hmm11 .\lists\triphones1
HERest -C .\config\config1 -I .\labels\wintri.mlf -t 250.0 150.0 1000.0 -s stats -S train.scp -H .\hmms\hmm11\macros -H .\hmms\hmm11\hmmdefs -M .\hmms\hmm12 .\lists\triphones1
Step 10: Making Tied-StateTriphones
执行:
perl .\scripts\mkclscript.prl TB 350.0 .\lists\monophones0>tree.hed
然后修改tree.hed加入问题集等
对dict2 进行修改,另存为 dict5,其中去掉了下述两项:
SENT-END [] sil
SENT-START [] sil
执行HDMan生成fulllist :
HDMan -b sp -n .\lists\fulllist -g global3.ded -l flog .\dict\dict5-tri .\dict\dict5
执行:
HHEd -H .\hmms\hmm12\macros -H .\hmms\hmm12\hmmdefs -M .\hmms\hmm13 tree.hed .\lists\triphones1 > log
生成文件:tiedlist log stats
重估两次:
HERest -C .\config\config1 -I .\labels\wintri.mlf -t 250.0 150.0 1000.0 -S train.scp -H .\hmms\hmm13\macros -H .\hmms\hmm13\hmmdefs -M .\hmms\hmm14 .\lists\tiedlist
HERest -C .\config\config1 -I .\labels\wintri.mlf -t 250.0 150.0 1000.0 -S train.scp -H .\hmms\hmm14\macros -H .\hmms\hmm14\hmmdefs -M .\hmms\hmm15 .\lists\tiedlist (测试集样本)
(测试集样本)
 (训练集样本)
(训练集样本)
以上就是A Digit Recognizer基于HTK实现数字串识别系统的搭建,由于测试集话语太少,所以也用了训练集来作为测试,能够很好的看出效果,下一步相信如果加入了高斯混合之后,识别率会进一步提高。