可延迟函数、内核微线程、工作队列
本文研究多个用于在内核环境当中延迟处理的方法(特别是在 Linux 内核版本 2.6.27.14 当中)。 尽管这些方法针对 Linux 内核,但方法背后的理念, 对于系统架构研究具有更广泛的意义。例如, 可以将这些理念应用到传统的嵌入式系统当中,取代原有的调度程序来进行任务调度 。
在开始研究用于内核中的可延迟函数之前, 让我们先了解一下相关问题的背景情况。 操作系统会因为一个硬件事件而产生中断(例如出现了一个来自网卡的数据包), 对该事件的处理过程从一个中断开始。 通常,中断会导致大量任务停止。 其中一些任务是在中断上下文完成的,然后任务被传递给软件栈来继续处理(参见 图 1)。
图 1. Top-half 以及 bottom-half 处理过程
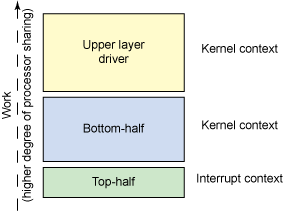
问题在于,有多少任务需要在中断上下文完成? 关于中断上下文的问题是,在此期间部分或者全部中断可以被禁止, 这就增加了处理其他硬件问题的时延(并导致处理习惯的改变)。 因此,有必要简化中断过程中要完成的任务, 把一些任务转移到内核上下文中去完成(在该上下文, 处理器资源更有可能被高效共享)。
正如 图 1 所示, 在中断上下文所完成的处理过程称为 top half, 基于中断并被推出中断上下文之外的处理过程称为 bottom half (top half 要依据 bottom half 来安排后续的处理过程)。 bottom-half 处理过程在内核上下文完成,这意味着允许中断操作。 因此通过延迟时间不敏感的任务,来更迅速处理高频率中断事件, 能够带来性能的优化。
有关 bottom halves 的历史
Linux 能够快速响应各种功能需求,延迟功能也不例外。 自 Linux2.3版本内核开始,就提供了软中断功能, 具有一组 32 个静态定义的 bottom halves。 作为静态元素,其定义在编译过程中完成(不同于新的动态机制)。 软中断用于在内核线程上下文中处理时间要求严格的处理过程(软件中断)。 可以在 ./kernel/softirq.c 中找到软中断的来源。 在 2.3 版本的 Linux 内核中还引入了微线程(参见 ./include/linux/interrupt.h)。 微线程的构建基于软中断,用于允许动态生成可延迟函数。 最终,在 2.5 版本 Linux 内核中引入了工作队列(参见 ./include/linux/workqueue.h)。 工作队列允许将任务延迟到中断上下文之外,进入内核处理上下文。
现在我们探讨一下任务延迟、微线程以及工作队列的动态机制。
回页首
微线程介绍
软中断最初为具有 32 个软中断条目的矢量, 用来支持一系列的软件中断特性。 当前,只有 9 个矢量被用于软中断, 其中之一是 TASKLET_SOFTIRQ(参见 ./include/linux/interrupt.h)。 虽然软中断还存在于内核中,推荐采用微线程和工作队列,而不是分配新的软中断矢量。
微线程是一个延迟方法,可以实现将已登记的函数进行推后运行。 top half(中断处理程序)完成少量的任务,然后安排微线程在晚些的 bottom half 中执行。
清单 1. 声明并调度微线程
/* Declare a Tasklet (the Bottom-Half) */ void tasklet_function( unsigned long data ); DECLARE_TASKLET( tasklet_example, tasklet_function, tasklet_data ); ... /* Schedule the Bottom-Half */ tasklet_schedule( &tasklet_example ); |
一个给定的微线程只运行在一个 CPU 中(就是用于调用该微线程的那个 CPU), 同一微线程永远不会同时运行在多个 CPU 中。 但是不同的微线程可以同时运行在不同的 CPU 中。
微线程可由 tasklet_struct 结构体表示(参见 图 2), 其中包含了用于管理和维护微线程的必要数据 (状态,通过 atomic_t 来实现允许/禁止控制,函数指针,数据,以及链表引用)。
图 2. tasklet_struct 结构体的内部情况
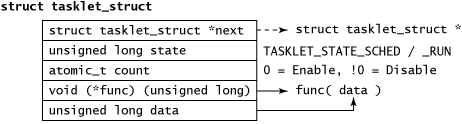
通过软中断机制来调度微线程,当机器处于严重软件中断负荷之下时, 可通过 ksoftirqd(一种每 CPU 内核线程)软中断来调度。 下面将探讨微线程应用编程接口(API)中支持的各类函数。
微线程 API
微线程通过宏调用来定义 DECLARE_TASKLET(参见 清单 2)。 在底层,该宏调用只是利用所提供的信息对结构体 tasklet_struct 进行初始化(微线程名,函数, 以及微线程专有数据)。 默认情况下,微线程处于允许状态,这意味着它可以被调度。 还可以利用宏 DECLARE_TASKLET_DISABLED 将微线程默认声明为禁止状态。 这时需要调用函数 tasklet_enable 来实现微线程可被调度。 可以分别利用函数 tasklet_enable 和函数 tasklet_disable 实现允许和禁止一个微线程(从调度的角度)。 函数 tasklet_init 也存在并利用用户提供的微线程数据来对 tasklet_struct 进行初始化。
清单 2. 微线程的创建以及 enable/disable 函数
DECLARE_TASKLET( name, func, data ); DECLARE_TASKLET_DISABLED( name, func, data); void tasklet_init( struct tasklet_struct *, void (*func)(unsigned long), unsigned long data ); void tasklet_disable_nosync( struct tasklet_struct * ); void tasklet_disable( struct tasklet_struct * ); void tasklet_enable( struct tasklet_struct * ); void tasklet_hi_enable( struct tasklet_struct * ); |
有两个 disable 函数,每一个都对微线程发出 disable 请求, 但是,微线程被终止后,只有 tasklet_disable 返回(其中 tasklet_disable_nosync 可能在终止发生之前返回)。disable 函数允许微线程被 “掩码”(也就是说,并不执行),直到 enable 函数被调用为止。 存在两个 enable 函数: 一个用于正常优先级调度(tasklet_enable),另一个用于允许高优先级调度(tasklet_hi_enable)。 正常优先级调度通过 TASKLET_SOFTIRQ-level 软中断来执行, 高优先级调度则通过 HI_SOFTIRQ-level 软中断执行。
由于存在正常优先级和高优先级的 enable 函数, 因此要有正常优先级和高优先级的调度函数(参见 清单 3)。 每个函数利用特殊的软中断矢量来为微线程排队(tasklet_vec 用于正常优先级, 而 tasklet_hi_vec 用于高优先级)。 来自高优先级矢量的微线程先得到服务,随后是来自正常优先级矢量的微线程。 注意,每个 CPU 维持其自己的正常优先级和高优先级软中断矢量。
清单 3. 微线程调度函数
void tasklet_schedule( struct tasklet_struct * ); void tasklet_hi_schedule( struct tasklet_struct * ); |
最后,微线程生成之后,就可以通过函数 tasklet_kill 来停止微线程(参见 清单 4)。 函数 tasklet_kill 保证微线程不会再运行, 并且,如果按进度该微线程应该运行,将会等到它运行完,然后再 kill 该线程。 tasklet_kill_immediate 只在指定的 CPU 处于 dead 状态时被采用。
清单 4. 微线程 kill 函数
void tasklet_kill( struct tasklet_struct * ); void tasklet_kill_immediate( struct tasklet_struct *, unsigned int cpu ); |
通过该 API,可见微线程 API 比较简单,实现也很简单。 可以通过 ./kernel/softirq.c 和 ./include/linux/interrupt.h 来了解微线程的实现机制。
有关微线程的简单例子
我们来看一个使用微线程 API 的简单例子(参见 清单 5)。 如这里所示,微线程函数(my_tasklet_function 和 my_tasklet_data)通过相关数据生成, 然后由 DECLARE_TASKLET 来声明一个新的微线程。 当该模块被插入后,微线程将被调度,这保证它在今后可执行。 当该模块被卸载,函数 tasklet_kill 将被调用来保证微线程不处于可调度状态。
清单 5. 微线程处于内核模块上下文的简单例子
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/interrupt.h>
MODULE_LICENSE("GPL");
char my_tasklet_data[]="my_tasklet_function was called";
/* Bottom Half Function */
void my_tasklet_function( unsigned long data )
{
printk( "%s\n", (char *)data );
return;
}
DECLARE_TASKLET( my_tasklet, my_tasklet_function,
(unsigned long) &my_tasklet_data );
int init_module( void )
{
/* Schedule the Bottom Half */
tasklet_schedule( &my_tasklet );
return 0;
}
void cleanup_module( void )
{
/* Stop the tasklet before we exit */
tasklet_kill( &my_tasklet );
return;
}
|
回页首
工作队列介绍
工作队列是实现延迟的新机制,从 2.5 版本 Linux 内核开始提供该功能。 不同于微线程一步到位的延迟方法,工作队列采用通用的延迟机制, 工作队列的处理程序函数能够休眠(这在微线程模式下无法实现)。 工作队列可以有比微线程更高的时延,并为任务延迟提供功能更丰富的 API。 从前,延迟功能通过 keventd 对任务排队来实现, 但是现在由内核工作线程 events/X 来管理。
工作队列提供一个通用的办法将任务延迟到 bottom halves。 处于核心的是工作队列(结构体 workqueue_struct), 任务被安排到该结构体当中。 任务由结构体 work_struct 来说明, 用来鉴别哪些任务被延迟以及使用哪个延迟函数(参见 图 3)。 events/X 内核线程(每 CPU 一个)从工作队列中抽取任务并激活一个 bottom-half 处理程序(由处理程序函数在结构体 work_struct 中指定)。
图 3. 工作队列背后的处理过程
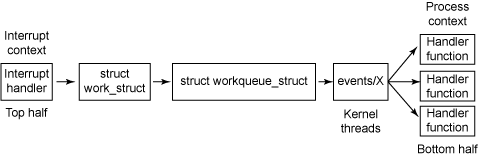
由于 work_struct 中指出了要采用的处理程序函数, 因此可以利用工作队列来为不同的处理程序进行任务排队。 现在,让我们看一下能够用于工作队列的 API 函数。
工作队列 API
工作队列 API 比微线程稍复杂,主要是因为它支持很多选项。 我们首先探讨一下工作队列,然后再看一下任务和变体。
通过 图 3 可以回想工作队列的核心结构体是队列本身。 该结构体用于将任务安排出 top half ,进入 bottom half ,从而延迟它的执行。 工作队列通过宏调用生成 create_workqueue,返回一个 workqueue_struct 参考值。 可以通过调用函数 destroy_workqueue 来远程遥控工作队列(如果需要):
struct workqueue_struct *create_workqueue( name ); void destroy_workqueue( struct workqueue_struct * ); |
通过工作队列与之通信的任务可以由结构体 work_struct 来定义。 通常,该结构体是用来进行任务定义的结构体的第一个元素(后面有相关例子)。 工作队列 API 提供三个函数来初始化任务(通过一个事先分配的缓存); 参见 清单 6。 宏 INIT_WORK 提供必需的初始化数据以及处理程序函数的配置(由用户传递进来)。 如果开发人员需要在任务被排入工作队列之前发生延迟,可以使用宏 INIT_DELAYED_WORK 和 INIT_DELAYED_WORK_DEFERRABLE。
清单 6. 任务初始化宏
INIT_WORK( work, func ); INIT_DELAYED_WORK( work, func ); INIT_DELAYED_WORK_DEFERRABLE( work, func ); |
任务结构体的初始化完成后,接下来要将任务安排进工作队列。 可采用多种方法来完成这一操作(参见 清单 7)。 首先,利用 queue_work 简单地将任务安排进工作队列(这将任务绑定到当前的 CPU)。 或者,可以通过 queue_work_on 来指定处理程序在哪个 CPU 上运行。 两个附加的函数为延迟任务提供相同的功能(其结构体装入结构体 work_struct 之中,并有一个 计时器用于任务延迟 )。
清单 7. 工作队列函数
int queue_work( struct workqueue_struct *wq, struct work_struct *work ); int queue_work_on( int cpu, struct workqueue_struct *wq, struct work_struct *work ); int queue_delayed_work( struct workqueue_struct *wq, struct delayed_work *dwork, unsigned long delay ); int queue_delayed_work_on( int cpu, struct workqueue_struct *wq, struct delayed_work *dwork, unsigned long delay ); |
可以使用全局的内核全局工作队列,利用 4 个函数来为工作队列定位。 这些函数(见 清单 8)模拟 清单 7,只是不需要定义工作队列结构体。
清单 8. 内核全局工作队列函数
int schedule_work( struct work_struct *work ); int schedule_work_on( int cpu, struct work_struct *work ); int scheduled_delayed_work( struct delayed_work *dwork, unsigned long delay ); int scheduled_delayed_work_on( int cpu, struct delayed_work *dwork, unsigned long delay ); |
还有一些帮助函数用于清理或取消工作队列中的任务。想清理特定的任务项目并阻塞任务, 直到任务完成为止, 可以调用 flush_work 来实现。 指定工作队列中的所有任务能够通过调用 flush_workqueue 来完成。 这两种情形下,调用者阻塞直到操作完成为止。 为了清理内核全局工作队列,可调用 flush_scheduled_work。
int flush_work( struct work_struct *work ); int flush_workqueue( struct workqueue_struct *wq ); void flush_scheduled_work( void ); |
还没有在处理程序当中执行的任务可以被取消。 调用 cancel_work_sync 将会终止队列中的任务或者阻塞任务直到回调结束(如果处理程序已经在处理该任务)。 如果任务被延迟,可以调用 cancel_delayed_work_sync。
int cancel_work_sync( struct work_struct *work ); int cancel_delayed_work_sync( struct delayed_work *dwork ); |
最后,可以通过调用 work_pending 或者 delayed_work_pending 来确定任务项目是否在进行中。
work_pending( work ); delayed_work_pending( work ); |
这就是工作队列 API 的核心。在 ./kernel/workqueue.c 中能够找到工作队列 API 的实现方法, API 在 ./include/linux/workqueue.h 中定义。 下面我们看一个工作队列 API 的简单例子。
工作队列简单例子
下面的例子说明了几个核心的工作队列 API 函数。 如同微线程的例子一样,为方便起见,可将这个例子部署在内核模块上下文。
首先,看一下将用于实现 bottom half 的任务结构体和处理程序函数(参见 清单 9)。 首先您将注意到工作队列结构体参考的定义 (my_wq)以及 my_work_t 的定义。 my_work_t 类型定义的头部包括结构体 work_struct 和一个代表任务项目的整数。 处理程序(回调函数)将 work_struct 指针引用改为 my_work_t 类型。 发送出任务项目(来自结构体的整数)之后,任务指针将被释放。
清单 9. 任务结构体和 bottom-half 处理程序
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/workqueue.h>
MODULE_LICENSE("GPL");
static struct workqueue_struct *my_wq;
typedef struct {
struct work_struct my_work;
int x;
} my_work_t;
my_work_t *work, *work2;
static void my_wq_function( struct work_struct *work)
{
my_work_t *my_work = (my_work_t *)work;
printk( "my_work.x %d\n", my_work->x );
kfree( (void *)work );
return;
}
|
清单 10 是 init_module 函数, 该函数从使用 create_workqueue API 函数生成工作队列开始。 成功生成工作队列之后,创建两个任务项目(通过 kmalloc 来分配)。 利用 INIT_WORK 来初始化每个任务项目,任务定义完成, 接着通过调用 queue_work 将任务安排到工作队列中。 top-half 进程(在此处模拟)完成。如同清单 10 中所示,任务有时会晚些被处理程序处理。
清单 10. 工作队列和任务创建
int init_module( void )
{
int ret;
my_wq = create_workqueue("my_queue");
if (my_wq) {
/* Queue some work (item 1) */
work = (my_work_t *)kmalloc(sizeof(my_work_t), GFP_KERNEL);
if (work) {
INIT_WORK( (struct work_struct *)work, my_wq_function );
work->x = 1;
ret = queue_work( my_wq, (struct work_struct *)work );
}
/* Queue some additional work (item 2) */
work2 = (my_work_t *)kmalloc(sizeof(my_work_t), GFP_KERNEL);
if (work2) {
INIT_WORK( (struct work_struct *)work2, my_wq_function );
work2->x = 2;
ret = queue_work( my_wq, (struct work_struct *)work2 );
}
}
return 0;
}
|
最终的元素在 清单 11 中展示。 在模块清理过程中,会清理一些特别的工作队列(它们将保持阻塞状态直到处理程序完成对任务的处理), 然后销毁工作队列。
清单 11. 工作队列清理和销毁
void cleanup_module( void )
{
flush_workqueue( my_wq );
destroy_workqueue( my_wq );
return;
}
|
回页首
微线程与工作队列的区别
从对微线程和工作队列的简短介绍中, 可以发现两个将任务从 top halves 延迟到 bottom halves 的不同方法。 微线程提供低延迟机制,该方式简单而直接, 而工作队列提供复杂的 API 来允许对多个任务项目进行排队。 每种方法都在中断上下文延迟任务,但只有微线程采用 run-to-complete 的风格自动运行, 而在此处,如果需要,工作队列允许处理程序休眠。 为有效实现任务延迟,可根据具体需求来选择相应的方法。
回页首
更进一步
这里所探讨的任务延迟方法涉及了历史的和当前的应用在 Linux 内核中的延迟方法(除了计时器之外,这将在以后的文章中讨论)。 它们当然不是新的 — 事实上,它们在过去已经以其他形式存在 — 但是它们代表了一种有趣的架构模式,这在 Linux 中和其他地方都很有用。 从软中断到微线程再到任务队列再到延迟的工作队列,Linux 在提供一致的和兼容的用户空间体验的同时,保持其内核各方面的持续发展。