K-SVD简述——字典学习,稀疏编码,MOD与之对比(附代码)
1. k-SVD introduction
1. K-SVD usage:
Design/Learn a dictionary adaptively to betterfit the model and achieve sparse signal representations.
2. Main Problem:
Y = DX
Where Y∈R(n*N), D∈R(n*K), X∈R(k*N), X is a sparse matrix.
N is # of samples;
n is measurement dimension;
K is the length of a coefficient.
2. Derivation from K-Means
3. K-Means:
1) The sparse representationproblem can be viewed as generalization of the VQ objective. K-SVD can be viewed as generalization of K-Means.
2) K-Means algorithm for vectorquantization:
Dictionary of VQ codewords is typically trained using K-Means algorithm.
When Dictionary D is given, each signal is represented as its closestcodeword (under l2-norm distance). I.e.
Yi = Dxi
Where xi = ej is a vector from the trivial basis,with all zero entries except a one in the j-th position.
3) VQ的字典训练:
K-Means被视作一个sparse coding的特例,在系数x中只有一个非零元,MSE定义为:

所以VQ的问题是:
4) K-Means 算法实现的迭代步骤:
1) 求X的系数编码
2) 更新字典
3. K-SVD,generalizing the K-Means
4. Objective function
5. K-SVD的求解
Iterative solution: 求X的系数编码(MP/OMP/BP/FOCUSS),更新字典(Regression).
K-SVD优化:也是K-SVD与MOD的不同之处,字典的逐列更新:
假设系数X和字典D都是固定的,要更新字典的第k列dk,领稀疏矩阵X中与dk相乘的第k行记做![]() ,则目标函数可以重写为:
,则目标函数可以重写为:
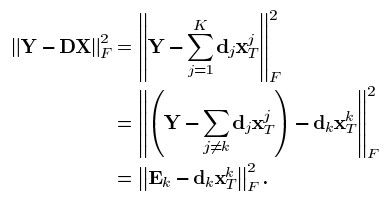
上式中,DX被分解为K个秩为1的矩阵的和,假设其中K-1项都是固定的,剩下的1列就是要处理更新的第k个。矩阵Ek表示去掉原子dk的成分在所有N个样本中造成的误差。
这里是我个人查资料后补充(OMP):
问题的模型是 x=argmin norm(y-D*x,2)^2 s.t.norm(x,1)<=k; 我们下面来介绍一下解决这个问题的常用方法OMP(Orthogonal Matching Pursuit) .我们主要目标是找出x中最主要的K个分量(即x满足K稀疏),不妨从第1个系数找起,假设x中仅有一个非零元x(m),那么 y0=D(:,m)*x(m)即是在只有一个主元的情况下最接近y的情况,norm(y-y0,2)/norm(y,2)<=sigma,换句话说 在只有一个非零元的情况下,D的第m列与y最“匹配”,要确定m的值,只要从D的所有列与y的内积中找到最大值所对应的D的列数即可,然后通过最小二乘法 即可确定此时的稀疏系数。考虑非零元大于1的情况,其实是类似的,只要将余量r=y-y0与D的所有列做内积,找到最大值所对应D的列即可。
模型: [D,x]=argmin norm(y-D*x,2)^2 s.t.norm(x,1)<=k。 如何同时获取字典D和稀疏系数x呢?方法是将该模型分解:第一步将D固定,求出x的值,这就是你常听到的稀疏分解(Sparse Coding),也就是上一节提到的字典D固定,求信号y在D上稀疏表示的问题;第二步是使用上一步得到的x来更新字典D,即字典更新 (Dictionary Update)。如此反复迭代几次即可得到优化的D和x。
Sparse Coding:x=argmin norm(y-D*x,2) s.t.norm(x,1)<=k
Dictinary Update:D=argmin norm(y-D*x,2)^2
MOD(Method of Optimal Direction)。Sparse Coding其采用的方法是OMP贪婪算法,Dictionary Update采用的是最小二乘法,即D=argmin norm(y-D*x,2)^2 解的形式是D=Y*x'*inv(x*x’)。因此MOD算法的流程如下:
初始化: 字典D_mxn可以初始化为随机分布的mxn的矩阵,也可以从输入信号中随机的选取n个列向量,下面的实验我们选取后者。 注意OMP要求字典的各列必须规范化,因此这一步我们要将字典规范化。 根据输入信号确定原子atoms的个数,即字典的列数。还有迭代次数。
主循环: Sparse Coding使用OMP算法; Dictionary Update采用最小二乘法。 注意这一步得到的字典D可能会有列向量的二范数接近于0,此时为了下一次迭代应该忽略该列原子,重新选取一个服从随机分布的原子。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
function [A,x]= MOD(y,codebook_size,errGoal)
%==============================
%input parameter
% y - input
signal
% codebook_size - count of atoms
%output parameter
% A - dictionary
% x - coefficent
%==============================
if
(size(y,2)<codebook_size)
disp(
'codebook_size is too large or training samples is too small'
);
return
;
end
% initialization
[rows,cols]=size(y);
r=randperm(cols);
A=y(:,r(1:codebook_size));
A=A./repmat(
sqrt
(sum(A.^2,1)),rows,1);
mod_iter=10;
% main loop
for
k=1:mod_iter
% sparse coding
if
nargin==2
x=OMP(A,y,5.0/6*rows);
elseif nargin==3
x=OMPerr(A,y,errGoal);
end
% update dictionary
A=y*x
'/(x*x'
);
sumdictcol=sum(A,1);
zeroindex=find(
abs
(sumdictcol)<eps);
A(zeroindex)=randn(rows,length(zeroindex));
A=A./repmat(
sqrt
(sum(A.^2,1)),rows,1);
if
(sum((y-A*x).^2,1)<=1e-6)
break
;
end
end
|
K-SVD对比MOD
K-SVD同MOD一样也分为Sparse Coding和Dictionary Update两个步骤,Sparse Coding没有什么特殊的,也是固定过完备字典D,使用各种迭代算法求信号在字典上的稀疏系数。同MOD相比,K-SVD最大的不同在字典更新这一步,K-SVD每次更新一个原子(即字典的一列)和其对应的稀疏系数,直到所有的原子更新完毕,重复迭代几次即可得到优化的字典和稀疏系数。
6. 提取稀疏项
如果在5.中这一步就用SVD更新dk和![]() ,SVD能找到距离Ek最近的秩为1的矩阵,但这样得到的系数
,SVD能找到距离Ek最近的秩为1的矩阵,但这样得到的系数![]() 不稀疏,换句话说,
不稀疏,换句话说,![]() 与更新dk前
与更新dk前![]() 的非零元所处位置和value不一样。那怎么办呢?直观地想,只保留系数中的非零值,再进行SVD分解就不会出现这种现象了。所以对Ek和
的非零元所处位置和value不一样。那怎么办呢?直观地想,只保留系数中的非零值,再进行SVD分解就不会出现这种现象了。所以对Ek和![]() 做变换,
做变换,![]() 中只保留x中非零位置的,Ek只保留dk和
中只保留x中非零位置的,Ek只保留dk和![]() 中非零位置乘积后的那些项。形成
中非零位置乘积后的那些项。形成![]() ,将
,将![]() 做SVD分解,更新dk。
做SVD分解,更新dk。
这里是我个人查资料后补充:
SVD decomposes into . The solution for is the first column of U, the coefficient vector as the first column of . After updated the whole dictionary, the process then turns to iteratively solve X, then iteratively solve D.
7. 总结
K-SVD总可以保证误差单调下降或不变,但需要合理设置字典大小和稀疏度。
在我的实验中,随着字典的增大,K-SVD有整体效果提升的趋势,但不一定随着稀疏度的增大使得整体误差下降。
8. Reference:
1) K-SVD: An algorithm fordesigning overcomplete dictionaries for sparse representation (IEEE Trans. OnSignal Processing 2006)
2) From sparse solutions of systemsof equations to sparse modeling of signals and images (SIAM Review 2009 240')