聚集索引,非聚集索引
不论是 聚集索引,还是非聚集索引,都是用B+树来实现的。我们在了解这两种索引之前,需要先了解B+树。如果你对B树不了解的话,建议参看以下几篇文章: BTree,B-Tree,B+Tree,B*Tree都是什么 http://blog.csdn.net/manesking/archive/2007/02/09/1505979.aspx
B+ 树的结构图:
B+ 树的特点:
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
- 不可能在非叶子结点命中;
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
B+ 树中增加一个数据,或者删除一个数据,需要分多种情况处理,比较复杂,这里就不详述这个内容了。
聚集索引(Clustered Index)
- 聚集索引的叶节点就是实际的数据页
- 在数据页中数据按照索引顺序存储
- 行的物理位置和行在索引中的位置是相同的
- 每个表只能有一个聚集索引
- 聚集索引的平均大小大约为表大小的5%左右
下面是两副简单描述聚集索引的示意图:
在聚集索引中执行下面语句的的过程:
select * from table where firstName = 'Ota'
一个比较抽象点的聚集索引图示:
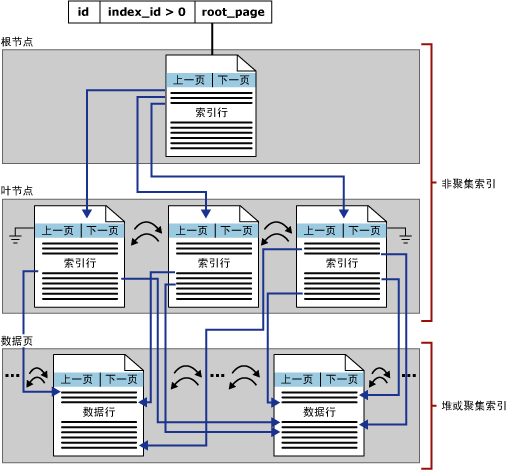
非聚集索引 (Unclustered Index)
- 非聚集索引的页,不是数据,而是指向数据页的页。
- 若未指定索引类型,则默认为非聚集索引
- 叶节点页的次序和表的物理存储次序不同
- 每个表最多可以有249个非聚集索引
- 在非聚集索引创建之前创建聚集索引(否则会引发索引重建)
在非聚集索引中执行下面语句的的过程:
select * from employee where lname = 'Green'
一个比较抽象点的非聚集索引图示:
什么是 Bookmark Lookup
虽然SQL 2005 中已经不在提 Bookmark Lookup 了(换汤不换药),但是我们的很多搜索都是用的这样的搜索过程,如下:先在非聚集中找,然后再在聚集索引中找。
在 http://www.sqlskills.com/ 提供的一个例子中,就给我们演示了 Bookmark Lookup 比 Table Scan 慢的情况,例子的脚本如下:
USE CREDIT go -- These samples use the Credit database. You can download and restore the -- credit database from here: -- http://www.sqlskills.com/resources/conferences/CreditBackup80.zip -- NOTE: This is a SQL Server 2000 backup and MANY examples will work on -- SQL Server 2000 in addition to SQL Server 2005. ------------------------------------------------------------------------------- -- (1) Create two tables which are copies of charge: ------------------------------------------------------------------------------- -- Create the HEAP SELECT * INTO ChargeHeap FROM Charge go -- Create the CL Table SELECT * INTO ChargeCL FROM Charge go CREATE CLUSTERED INDEX ChargeCL_CLInd ON ChargeCL (member_no, charge_no) go ------------------------------------------------------------------------------- -- (2) Add the same non-clustered indexes to BOTH of these tables: ------------------------------------------------------------------------------- -- Create the NC index on the HEAP CREATE INDEX ChargeHeap_NCInd ON ChargeHeap (Charge_no) go -- Create the NC index on the CL Table CREATE INDEX ChargeCL_NCInd ON ChargeCL (Charge_no) go ------------------------------------------------------------------------------- -- (3) Begin to query these tables and see what kind of access and I/O returns ------------------------------------------------------------------------------- -- Get ready for a bit of analysis: SET STATISTICS IO ON -- Turn Graphical Showplan ON (Ctrl+K) -- First, a point query (also, see how a bookmark lookup looks in 2005) SELECT * FROM ChargeHeap WHERE Charge_no = 12345 go SELECT * FROM ChargeCL WHERE Charge_no = 12345 go -- What if our query is less selective? -- 1000 is .0625% of our data... (1,600,000 million rows) SELECT * FROM ChargeHeap WHERE Charge_no < 1000 go SELECT * FROM ChargeCL WHERE Charge_no < 1000 go -- What if our query is less selective? -- 16000 is 1% of our data... (1,600,000 million rows) SELECT * FROM ChargeHeap WHERE Charge_no < 16000 go SELECT * FROM ChargeCL WHERE Charge_no < 16000 go ------------------------------------------------------------------------------- -- (4) What's the EXACT percentage where the bookmark lookup isn't worth it? ------------------------------------------------------------------------------- -- What happens here: Table Scan or Bookmark lookup? SELECT * FROM ChargeHeap WHERE Charge_no < 4000 go SELECT * FROM ChargeCL WHERE Charge_no < 4000 go -- What happens here: Table Scan or Bookmark lookup? SELECT * FROM ChargeHeap WHERE Charge_no < 3000 go SELECT * FROM ChargeCL WHERE Charge_no < 3000 go -- And - you can narrow it down by trying the middle ground: -- What happens here: Table Scan or Bookmark lookup? SELECT * FROM ChargeHeap WHERE Charge_no < 3500 go SELECT * FROM ChargeCL WHERE Charge_no < 3500 go -- And again: SELECT * FROM ChargeHeap WHERE Charge_no < 3250 go SELECT * FROM ChargeCL WHERE Charge_no < 3250 go -- And again: SELECT * FROM ChargeHeap WHERE Charge_no < 3375 go SELECT * FROM ChargeCL WHERE Charge_no < 3375 go -- Don't worry, I won't make you go through it all :) -- For the Heap Table (in THIS case), the cutoff is: 0.21% SELECT * FROM ChargeHeap WHERE Charge_no < 3383 go SELECT * FROM ChargeHeap WHERE Charge_no < 3384 go -- For the Clustered Table (in THIS case), the cut-off is: 0.21% SELECT * FROM ChargeCL WHERE Charge_no < 3438 SELECT * FROM ChargeCL WHERE Charge_no < 3439 go
这个例子也就是 吴家震 在Teched 2007 上的那个演示例子。
小结:
这篇博客只是简单的用几个图表来介绍索引的实现方法:B+数, 聚集索引,非聚集索引,Bookmark Lookup 的信息而已。
参考资料:
表组织和索引组织 http://technet.microsoft.com/zh-cn/library/ms189051.aspx http://technet.microsoft.com/en-us/library/ms189051.aspx
How Indexes Work http://manuals.sybase.com/onlinebooks/group-asarc/asg1200e/aseperf/@Generic__BookTextView/3358
Bookmark Lookup http://blogs.msdn.com/craigfr/archive/2006/06/30/652639.aspx
Logical and Physical Operators Reference http://msdn2.microsoft.com/en-us/library/ms191158.aspx